
Cloud infrastructure in 2025 is a multi-environment, multi-cloud system, not a set-it-and-forget-it deployment. Most engineering teams operate across at least three runtime environments: development for sandboxed experimentation, staging for integration and QA, and production for live, SLA-bound workloads. These environments often span multiple cloud providers, Terraform provisions VPCs, IAM, and S3 in AWS; Bicep manages Azure App Services and SQL; ArgoCD deploys to EKS and AKS using GitOps; Vault handles secrets; Terraform Cloud monitors drift; and CI/CD pipelines like GitHub Actions or Azure DevOps drive everything end-to-end.
A recent question on r/AZURE frames this well:

That question cuts right to the real-world gap. Many teams write IaC, but few treat it like software. Without orchestration, proper environments, CI/CD flows, policy gates, and drift reconciliation, you’re just applying code and hoping it sticks.
One engineer in the thread responded with a hardened setup: Azure DevOps pipelines, service principals scoped per environment, Terraform state in blob storage, daily drift reports, and zero console access. Another made the point even clearer:
“‘One-and-done’ on a local machine is pointless. You have to remove everyone’s access and force them to use a process.”
That “process” is orchestration. Not just provisioning, but enforcing how infrastructure moves through stages: plan, review, approve, apply, monitor, reconcile. Even GitOps, while critical for versioning and auditability, lacks the logic to enforce environment-specific workflows, prevent race conditions, or auto-remediate drift.
This guide explores what that orchestration layer really looks like, how GitOps fits in, where it falls short, and how to build something that actually scales in production.
What is Infrastructure Orchestration?
Infrastructure orchestration is the process of coordinating how infrastructure is provisioned, validated, and deployed across environments, such as dev, staging, and production. It governs not just what gets deployed, but how, when, and under what conditions. It wraps your Infrastructure as Code (IaC), Terraform, Bicep, Pulumi, etc., in logic and workflows that ensure changes are introduced in a consistent, controlled, and auditable way.
Automation vs. Orchestration
Automation handles individual tasks. These are things you script or trigger as part of your workflow:
- terraform fmt, terraform validate and terraform plan in CI
- az bicep build and az deployment sub create for Azure deployments
- kubectl apply or ArgoCD syncing YAMLs into clusters
- Drift detection jobs using terraform refresh + terraform plan -detailed-exitcode
Each of these tasks is important, but they're isolated. They don’t understand sequence, policy, or the broader lifecycle of infrastructure changes.
Orchestration, on the other hand, is the system that connects those tasks together. It defines the execution flow across environments, ensures proper ordering, enforces policies, handles approvals, and integrates with the rest of your deployment process.
What Orchestration Actually Manages
A well-orchestrated infrastructure workflow handles the following responsibilities:
- Order of Operations: Ensures that resources are deployed in dependency order. For example, VPCs and subnets must be provisioned before any application modules or database clusters that rely on them.
- Environment-Specific Logic: Applies different logic based on the target environment. For instance, production might enforce stricter CIDR ranges, require encryption on all resources, or block default tags, while dev is more permissive.
- Policy Enforcement Gates: Uses tools like Open Policy Agent (OPA) or Sentinel to fail the deployment if it violates predefined rules, such as deploying public S3 buckets, over-budget instance types, or missing required tags.
- Approval Workflows: Requires human approval for sensitive operations, like modifying IAM roles, security groups, or networking components in shared environments.
- Multi-Environment Promotion: Promotes changes through environments only when conditions are met. For example, apply to staging first, validate the state, then promote the same code to production after second approval.
- Drift Awareness: Detects and blocks changes when the real infrastructure state has drifted from what’s in Git. Prevents applying new changes on top of stale or inconsistent state.
- Notifications and Rollbacks: Notifies relevant stakeholders (via Slack, Teams, etc.) when a plan or apply is initiated, and automatically triggers rollback or remediation actions if something fails during deployment.
Infrastructure Orchestration with Terraform and GitHub Actions
Let’s take a real example of how infrastructure orchestration works in practice using Terraform in a CI/CD pipeline in GitHub Actions.
Imagine a developer submits a pull request that updates Terraform code for provisioning AWS infrastructure—maybe they're adding a new IAM role or modifying a VPC route. Once that PR is opened, GitHub Actions kicks in and orchestrates the following sequence:
- Checks out the code
- Initializes Terraform with the correct backend configuration (per environment)
- Runs terraform plan using an environment-specific .tfvars file
- Waits for PR review or conditional logic
- Applies changes only on merge to master, and only when the event is a push (not a PR)
Here’s a simplified version of an actual GitHub Actions workflow that orchestrates Terraform end-to-end:
This workflow uses a matrix strategy to support multiple environments, like dev, staging, or prod- without duplicating jobs. The backend configuration dynamically sets the correct state bucket for each environment, ensuring isolation and traceability. During the plan phase, environment-specific .tfvars files inject context such as region, instance sizes, or tagging conventions. The apply step is intentionally gated with a condition so that it only executes on merged code, not on every pull request.
What you see here is a basic orchestration setup that works for a single environment and a small team. But once you're managing multiple environments, cloud providers, or teams with different responsibilities, a simple pipeline isn’t enough. You need a system that can handle dependencies between modules, enforce policies, coordinate promotion across environments, detect drift, manage secrets, and integrate with approval flows, all while keeping Git as the source of truth. That’s where real infrastructure orchestration starts, and it’s built on a few essential components. Let’s walk through those.
The Building Blocks of an Infrastructure Orchestration System
A solid orchestration system isn’t just a fancy pipeline or a wrapper around terraform apply . It’s a composition of multiple layers that work together to manage complexity across environments, teams, and tools. Below are the key components every mature orchestration setup needs to operate reliably and at scale.

Declarative Infrastructure
Everything starts with declarative definitions. Tools like Terraform, Pulumi, and Bicep let you define infrastructure in code, specifying the desired state rather than how to achieve it. This gives you version-controlled, diffable, and reviewable infrastructure, the same way you handle application code.
For example:
- Terraform modules for VPC, EKS, and RDS
- Bicep templates for Azure Functions and Cosmos DB
- Helm charts for Kubernetes services
Declarative IaC is important because orchestration engines rely on it to detect change, run plans, identify drift, and apply changes predictably. Without this foundation, the rest falls apart.
Environment and Resource Graph Awareness
Terraform does build a dependency graph, but only within the context of a single configuration, plan, and state. It constructs this graph at runtime by parsing depends_on declarations, interpolations (like references to resource.attr), and provider relationships. You can inspect the resulting structure manually using terraform graph , which shows the nodes (resources, providers, meta-nodes) and their connections.
But this dependency graph is scoped. It only reflects what Terraform knows based on your current working directory and state file. Once you split infrastructure into multiple stacks, for example, VPC in one state and EKS clusters in another, Terraform has no visibility into how those resources relate unless you explicitly wire them up using data sources or manually pass outputs as inputs.
This is where orchestration becomes necessary.
Let’s say you have:
- A networking stack that provisions the VPC and subnets
- An apps stack that deploys compute into those subnets
- A monitoring stack that provisions Datadog or Prometheus into every environment
Each stack has its own terraform apply lifecycle. If a subnet ID changes in networking, but apps hasn’t re-read that value yet, you have drift or potential failure. Terraform won’t stop you; it has no graph awareness across these boundaries.
Even more practically:
- If someone manually changes a subnet's CIDR block in AWS, Terraform doesn’t know unless you explicitly terraform refresh , or build tooling around drift detection.
- If you promote a change from staging to prod, there’s no guarantee that the same topology exists unless your orchestration system validates live infrastructure via cloud APIs or monitoring data.
To handle this, orchestration needs to model cross-environment and cross-stack relationships, similar to how the diagram you provided outlines layered execution:
- Discovery Engine: Identifies current resource state — across clouds and environments.
- Deployment Engine: Coordinates execution order between stacks or modules — ensuring dependent resources are created in the correct sequence.
- Monitoring and Policy Engines: Feed live state and policy evaluations back into the orchestration system to block or gate changes.
In Terraform terms, orchestration acts as an external controller that understands how modules and states relate. It knows the order in which plans must run, tracks cross-stack dependencies, and triggers re-plans when shared resources change.
Policy-as-Code and Guardrails
Policies must be enforced consistently and automatically. Tools like Open Policy Agent (OPA) or HashiCorp Sentinel let you define guardrails in code, enforcing naming conventions, cost boundaries, tagging standards, security rules, and more.
Common examples include:
- Rejecting any plan that opens a security group to 0.0.0.0/0
- Enforcing resource tagging for cost allocation
- Blocking changes in prod unless an approver is tagged
- Failing deployments that exceed estimated budget thresholds
These policies are applied during the plan or pre-deploy stages, preventing bad configurations from ever reaching production.
Workflow Automation with Approvals and Gates
An orchestration system needs to support multi-step workflows with branching logic, manual gates, and conditionals. A basic example:
- terraform plan runs on pull request
- If the plan passes policy checks, wait for manual approval
- Apply to the staging environment
- If staging apply has no drift or resource replacements, auto-promote to production after a second approval
To integrate team communication, these workflows often include Slack notifications using actions like rtCamp/action-slack-notify or slackapi/slack-github-action. This level of orchestration is possible with native CI tools, but building and maintaining these YAML workflows across services and environments is tedious and time-consuming. That's where orchestration platforms like Firefly add value, by providing these capabilities out of the box within guardrails, and by setting Slack/email notifications every time we run the workflows.

These structured workflows work well when environments are clearly defined, like dev, staging, and prod, and changes flow through a stable release process. Teams increasingly need to spin up temporary environments for testing, previews, or feature-specific deployments, all while maintaining policy enforcement and automation. Supporting these dynamic environments introduces new orchestration challenges that GitOps alone isn’t equipped to handle.
Managing Dynamic Environments with GitOps
GitOps works well for managing static environments, like dev, staging, and prod, where infrastructure is long-lived and changes flow through a structured Git-based workflow. But this model starts to break down when teams need to create dynamic environments, such as per-PR preview environments, isolated integration testing environments, or temporary feature branch deployments.
Why GitOps Alone Isn't Enough
GitOps assumes that infrastructure is defined in Git ahead of time, but these environments are dynamic by nature. You don’t want to push a new commit just to create a preview stack for feature/login-rate-limiting. And even if you did, you’d be left managing dozens of temporary commits or branches cluttering up your repo.
This leads to several GitOps friction points:
- You can't track environments that only exist temporarily
- You need runtime variables (like PR ID, Git SHA, or requester) that don’t belong in static files
- Cleanup is hard to model in Git; you can’t "git delete" an environment
As teams adopt ephemeral environments for testing, QA, or staging, GitOps alone becomes insufficient. This is where the orchestrator steps in.
What a Modern Orchestrator Adds
Modern orchestrators enable dynamic, policy-aware, and event-driven infrastructure workflows that Git alone cannot manage.
1. Preview Environments on CI Events
Orchestrators create ephemeral environments automatically when a pull request opens.
- A CI job (e.g., GitHub Actions or GitLab CI) generates a Terraform plan or Argo CD ApplicationSet using PR-specific variables like pr-12345 and commit SHA.
- These environments are rendered and applied dynamically.
- Terraform Cloud supports on-demand workspace provisioning.
- Argo CD’s Pull Request Generator enables the same for Kubernetes.
2. Runtime Context Injection
Orchestration engines inject live context into plans and manifests.
- Values like branch name, PR number, author, or a random suffix keep resource names unique (eks-web-pr-12345, db-pr-56789).
- These values are exposed as environment variables or metadata within the orchestrated runtime.
3. Policy Enforcement for Non-Prod Stacks
Even short-lived environments are evaluated against policies before provisioning.
- OPA or Sentinel policies run inline to block oversized instances, missing tags, or insecure settings.
- Guardrails apply across all environments, not just production.
- Drift detection and auto-remediation are often built in, ensuring compliance from the start.
4. Lifecycle Tracking and Ownership
Orchestrators map environments to their source metadata.
- Each environment is tied to a PR, branch, or user—enabling auditability.
- A central registry (via API or database) allows teams to discover and track what’s running and why.
- This reduces orphaned resources and improves transparency in shared infrastructure.
5. Automated Teardown and TTL
Git can’t destroy infra, but orchestrators can.
- They listen for PR close or merge events and trigger a destroy workflow.
- TTL (time-to-live) labels can be interpreted by controllers to garbage-collect resources after a fixed period.
- A full lifecycle, create on open, destroy on close, runs with no manual cleanup.
6. Cross-Stack Awareness
Orchestrators manage dependencies between stacks automatically.
- If a preview app depends on a networking layer, the network plan is executed first.
- Outputs like subnet IDs or security group references are passed downstream into dependent plans.
- This coordination ensures correct provisioning order and minimizes manual wiring across state files.
Orchestration extends GitOps with lifecycle hooks, runtime context, dependency handling, and policy enforcement. It enables dynamic, isolated environments per PR, ensures policy compliance before applying, and automates teardown on PR close. Git holds the templates; the orchestrator executes them safely and event-driven.
How Firefly Automates Infrastructure Orchestration in 2025
Firefly is designed to handle real-world infrastructure challenges that GitOps and IaC tools alone can’t solve. Instead of replacing Terraform, Bicep, or Helm, it wraps around them, orchestrating their execution, enforcing policies, managing drift, and integrating seamlessly with Git-based workflows. It acts as a control plane that coordinates infrastructure changes across stacks, tools, and environments as showcased visually in the snapshot below:

Using Firefly CI for Terraform Orchestration
To illustrate how Firefly orchestrates infrastructure workflows in practice, let’s walk through a hands-on example that uses Firefly CI to deploy a Google Cloud Storage bucket with Terraform. This setup demonstrates how Firefly ties together IaC execution, policy evaluation, cost visibility, and Git integration.
Infrastructure Code: main.tf
This Terraform configuration deploys a Google Cloud Storage bucket with a unique suffix and disabled versioning:
GitHub Workflow: deploy-buckets.yml
This GitHub Actions workflow runs the full Terraform lifecycle: plan, apply, and destroy. It also integrates Firefly CLI to post results after each stage.
Key highlights:
- Firefly credentials are passed via secrets
- Plan and apply outputs are piped to .jsonl logs for Firefly to consume
- Firefly automatically posts policy violations, tag coverage, and cost estimations
Here’s the workflow that is deployed in GitHub Actions:
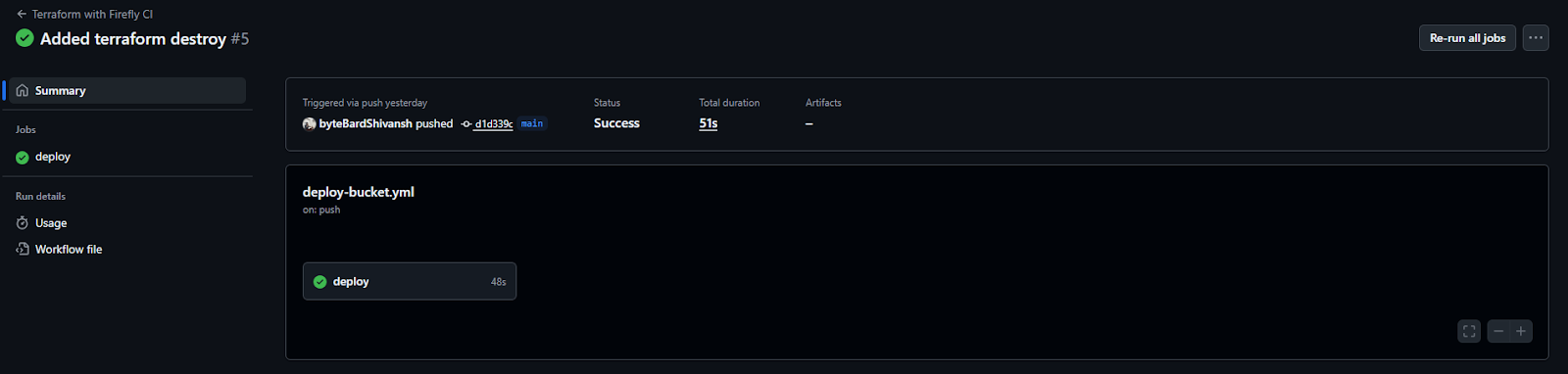
Yaml file:
Firefly Workflow UI: Execution Overview
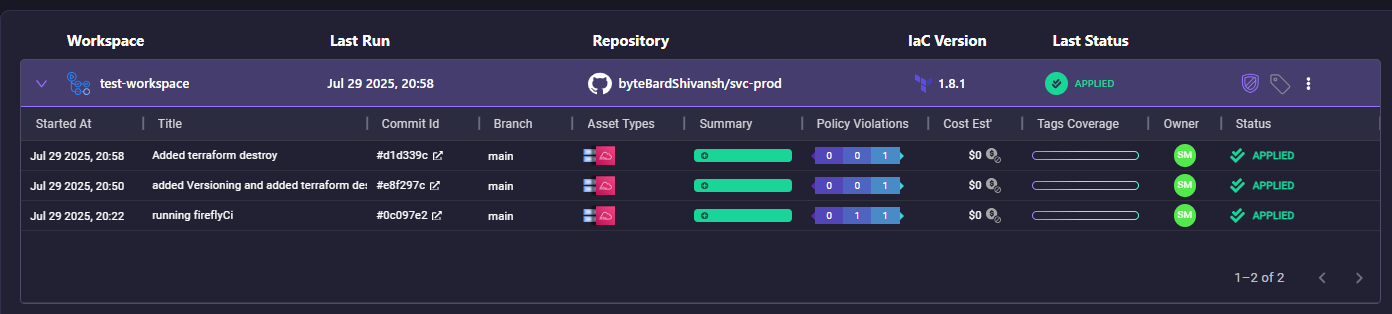
From the Firefly dashboard, we can view:
- Workspace runs with timestamps, commit info, IaC version, and statuses
- Policy violations and tagging metrics
- Cost estimates per resource
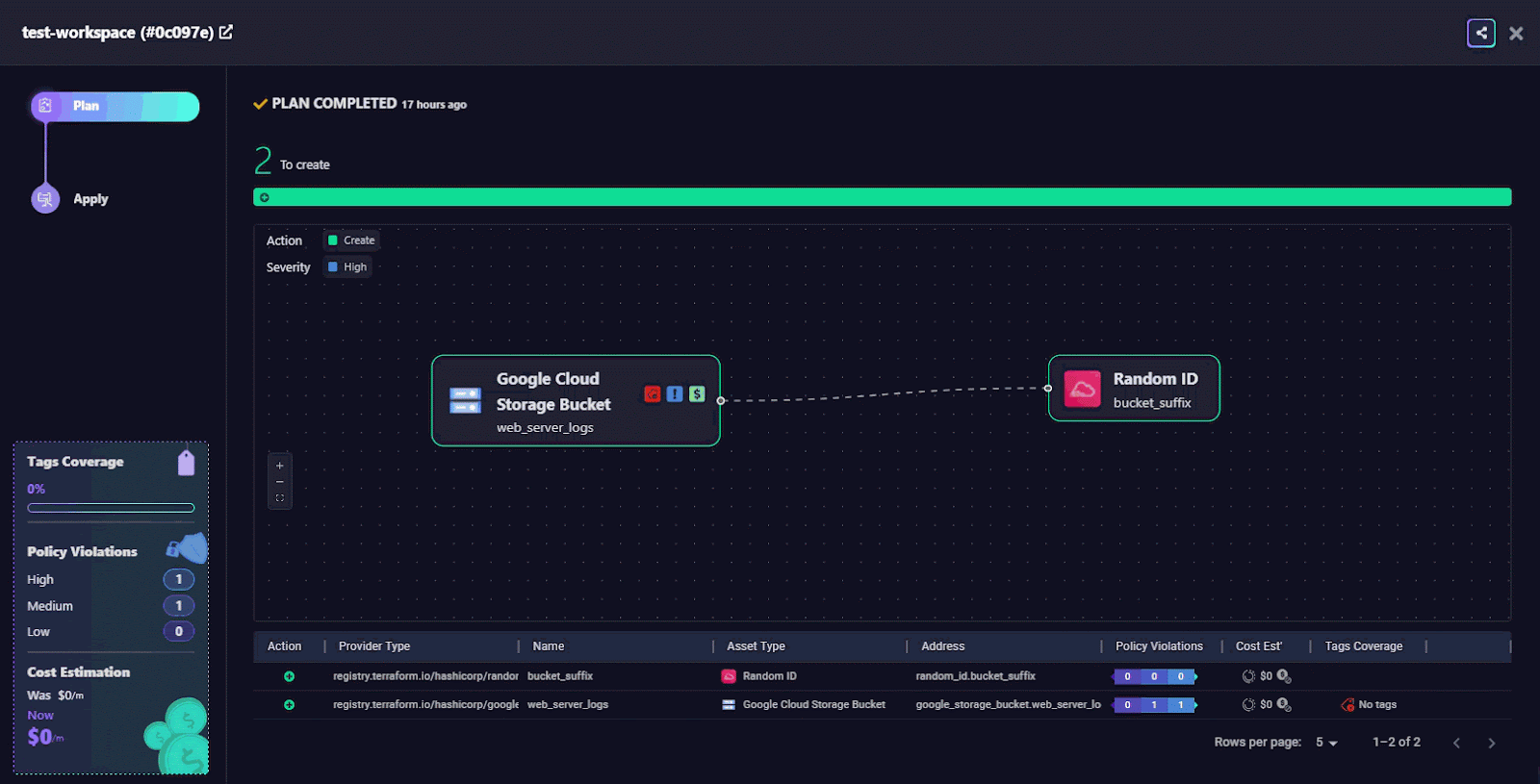
Dependency Graph View
Firefly generates a visual graph of resource dependencies. Here, you can see how the random_id is used to suffix the bucket name, establishing an upstream dependency.
Policy Violation Detection
The Firefly policy engine detects two issues:
- High Severity: Bucket-level access is disabled
- Medium Severity: Versioning is disabled (as per policy, versioning should be on)
These violations are annotated in the UI with remediation suggestions.

Cost Breakdown
Firefly also provides granular cost estimation per resource and per operation:
- $0.03/GB for storage
- $0.05/10k for object adds
- $0.00 for reads

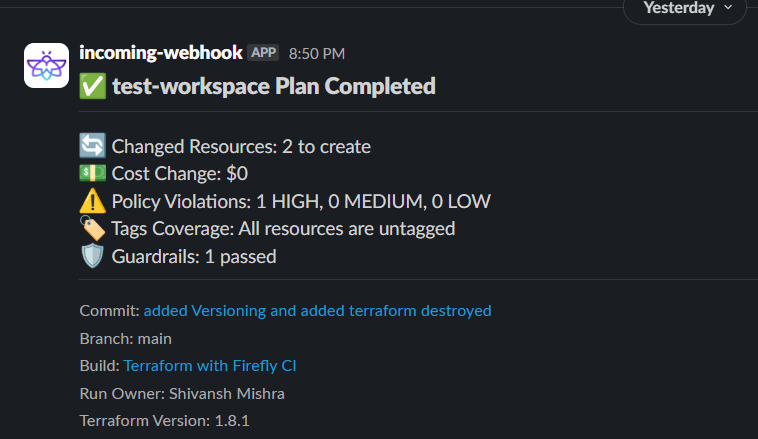
Slack Integration
Post-plan Slack notifications summarize the outcome of each run:
- Resources to change
- Cost delta
- Violations
- Guardrail checks
This hands-on setup shows how Firefly orchestrates Terraform workflows by layering visibility, policy, and context directly on top of GitOps and CI pipelines. It handles the operational burden, allowing teams to focus on writing infrastructure code rather than manually gluing the process together.
FAQs
What is the Difference Between Infrastructure Orchestration and Configuration Management?
Configuration management tools like Ansible, Chef, and Puppet manage the state inside servers, packages, services, files, and system settings. They’re typically agent-based and operate post-provisioning.
Infrastructure orchestration coordinates the full lifecycle of infrastructure, provisioning resources (like VPCs, clusters, databases), enforcing policy, managing dependencies, and controlling multi-step workflows. Orchestration sits above configuration and is concerned with when and how infra changes are applied across environments.
What is the Difference Between IaC and Orchestration?
Infrastructure as Code (IaC) tools like Terraform, Bicep, and Pulumi define what infrastructure should look like, resources, modules, dependencies using code.
Orchestration handles how and when that code gets executed: across environments, in the right order, with approvals, policies, and drift detection. Think of IaC as the blueprint, and orchestration as the builder with a plan and checklist.
What is Cloud Orchestration and Automation?
Automation runs specific tasks: deploy a VM, tag resources, run a script. It’s about repeatable, isolated actions.
Cloud orchestration coordinates multiple automated steps into structured workflows. It handles dependencies, retries, conditional logic, and cross-environment promotion. It's automation with awareness of context, sequence, and impact.
What is the Primary Purpose of Cloud Orchestration?
The goal is to make infrastructure manageable at scale. Cloud orchestration provides:
- Consistent deployment workflows across environments
- Policy enforcement and approval flows
- Drift detection and reconciliation
- Integration with Git, CI/CD, monitoring, and cost tooling
- Lifecycle management of dynamic environments
It’s what makes IaC usable and safe for real-world teams working across multiple clouds and stacks.

.avif)
.avif)


.webp)


.webp)















