
Foundation models now drive core use cases like text summarization, code generation, image synthesis, and video analysis. AWS Bedrock gives direct access to these models, including Claude (Anthropic), Llama (Meta), Titan (Amazon), and others, through a single API on serverless infrastructure. You don’t manage GPUs, containers, or scaling. You call the model and get a response. Companies are using this to move faster: Dovetail, a B2B SaaS platform for customer insights, uses Bedrock to ship AI features in weeks instead of months. Their customers save around 10 hours per week on analysis tasks and report productivity gains of over 80% (AWS case study).
Abstraction doesn’t remove the need for discipline in operations. Bedrock deployments need Infrastructure as Code (IaC) to stay consistent across dev, test, and prod. Since AWS Provider v5.49, Terraform supports provisioning Bedrock agents, knowledge bases, custom models, and throughput. This means Bedrock infrastructure can be versioned, reviewed in pull requests, and rolled back like any other software change.
This guide demonstrates:
- Provisioning Bedrock resources via Terraform
- Deploying Meta’s Llama 3 foundation model with AWS Lambda
- Integrating Firefly for automated Terraform plans, safe applies, guardrails, and drift detection
Deploying GenAI on AWS works best with code, not clicks. This walkthrough gives you a baseline setup to start from.
What Is Amazon Bedrock?
Amazon Bedrock is a fully managed service that lets you run foundation models from multiple providers using a single, unified API. You don’t deploy servers. You don’t manage model runtimes. You don’t scale anything. You just choose the model, format the payload, and make the request.
The service is designed for developers and teams that need to integrate models like Claude, Llama 3, Titan, and Mistral without worrying about the underlying infrastructure. Bedrock sits in front of these models and provides a consistent interface, regardless of the provider. That means you can switch between Anthropic, Meta, or Amazon models by changing the model ID, no SDK rewrites, no special endpoint handling.
Supported Models and Providers
At the time of writing, Bedrock supports the following:
- Anthropic: Claude 2 and 3 (best-in-class chat models)
- Meta: Llama 3 (available in 8B and 70B variants)
- Amazon: Titan (text generation, embeddings, image generation)
- Mistral: Open-weight chat models with strong performance
- Cohere: Text generation and classification models
- Stability AI: Image generation via Stable Diffusion
Each of these models supports different tasks: text generation, summarization, embeddings, multi-turn conversation, image generation, etc. Some support fine-tuning (Amazon’s Titan models), while others like Claude or Llama do not, at least not yet, as of mid-2025.
Access Model
Bedrock access isn’t globally enabled by default. You need to explicitly request access via the AWS Console or API and enable individual models at the account level. Also, model support is region-specific. For example, Llama 3 might be available in us-east-1 but not eu-central-1. Trying to use a model in the wrong region or without enablement will throw AccessDeniedException.
Bedrock vs. SageMaker
It’s worth understanding how Bedrock compares to SageMaker.
- Bedrock is optimized for consumption; you call existing, pretrained models from external providers. There’s no infrastructure to manage, no training scripts, and no model tuning unless the model explicitly supports it.
- SageMaker, by contrast, is built for training, fine-tuning, and hosting your own models. You provision notebooks, configure training jobs, write custom inference code, and optionally deploy models behind endpoints.
If your use case is to consume existing models quickly, Bedrock is the right tool. If you're a data scientist building custom models or training from scratch, you're likely better off in SageMaker.
Unified API and Model Selection
Every model in Bedrock is accessed through a unified API. You send a InvokeModel or InvokeModelWithResponseStream request, specify the modelId ID, and include your payload. Bedrock handles everything else, routing, tokenization, security, and model hosting.
This unified approach eliminates the need to work with individual provider APIs, manage multiple SDKs, or juggle various auth flows. All the complexity is abstracted away.
Pricing Model
There are two pricing options depending on your usage:
- Pay-as-you-go: You’re billed per request, based on input/output token count (for text) or per image generated. Each model has its own pricing; Titan might be cheaper than Claude, for example.
- Provisioned throughput: For production use cases with consistent traffic, you can reserve model capacity. This guarantees performance and avoids cold starts, but it comes with a longer-term commitment and fixed monthly cost.
Why Deploy AWS-Bedrock using IaC?
If you're working with Bedrock in any meaningful way, across multiple environments, teams, or models, you’ll eventually run into the same set of problems: inconsistent deployments, manual drift, unclear change history, and environments that behave differently without a clear reason. The AWS Console might be good for experimentation, but it doesn't scale. At some point, you need to treat Bedrock like you treat the rest of your infrastructure. That’s where Terraform fits in.
The Case for Infrastructure-as-Code (IaC)
With Terraform, you define Bedrock resources in code: agents, knowledge bases, provisioned throughput, even custom models. This gives you:
- Auditability: Every change is logged, version-controlled, and reviewable in pull requests.
- Repeatability: You can spin up the same setup across dev, staging, and prod, reliably.
- GitOps workflows: Infrastructure changes are triggered by PRs, reviewed like app code, and applied via CI/CD pipelines.
- Drift detection: Tools like Firefly (we’ll get to that) can detect if something was changed outside of code.
This isn’t about adding process for the sake of it, it’s about having a clear, versioned history of infrastructure changes so you can trace, audit, and roll back safely when something fails.
Terraform Support for Terraform AWS Bedrock (AWS Provider v5.49+)
As of AWS provider version 5.49 and newer, Terraform can provision a wide range of Bedrock resources:
- aws_bedrock_agent: Defines a Bedrock agent for orchestrated, multi-step queries.
- aws_bedrock_knowledge_base: Adds retrieval-augmented generation (RAG) by linking models to company data (e.g., S3).
- aws_bedrock_provisioned_model_throughput: Reserves compute capacity for consistent latency and high-throughput applications.
- aws_bedrock_custom_model: Used to launch fine-tuning jobs on supported models (like Titan).
Terraform gives you access to these resources via the standard AWS provider, so there’s no custom tooling or third-party wrappers required.
Example Patterns for Bedrock IaC
In practice, you’ll want to modularize your configuration. A typical layout might look like:
Each module handles a single concern: S3 for training data, IAM for model access roles, Bedrock for model/agent config, and so on. This makes it easier to test, reuse, and extend as your stack grows.
You can also use Terraform workspaces or directory-based environments to separate dev and prod setups, while sharing common modules underneath.
CI/CD Integration
Once you define your infrastructure in Terraform, it becomes just another part of your deployment pipeline. For example, you can:
- Run terraform plan on pull requests
- Apply infrastructure changes on merge
- Tag resources for cost tracking
- Detect drift between declared vs. actual state
You can do this with GitHub Actions, GitLab CI, or a specialized tool like Firefly, which brings Terraform-native visibility and policy enforcement into your CI/CD flows , we’ll cover that in a later section.
Deploying Meta’s Llama 3 via Lambda + Bedrock
To invoke Meta’s Llama 3 foundation model via Amazon Bedrock, a Lambda function is deployed and configured with the required IAM permissions. The infrastructure is defined using Terraform and deploys the Lambda function, its execution role, and associated permissions. This is shown in the flow below from Terraform provisioning through AWS Lambda to Bedrock runtime, including IAM role configuration and model invocation:
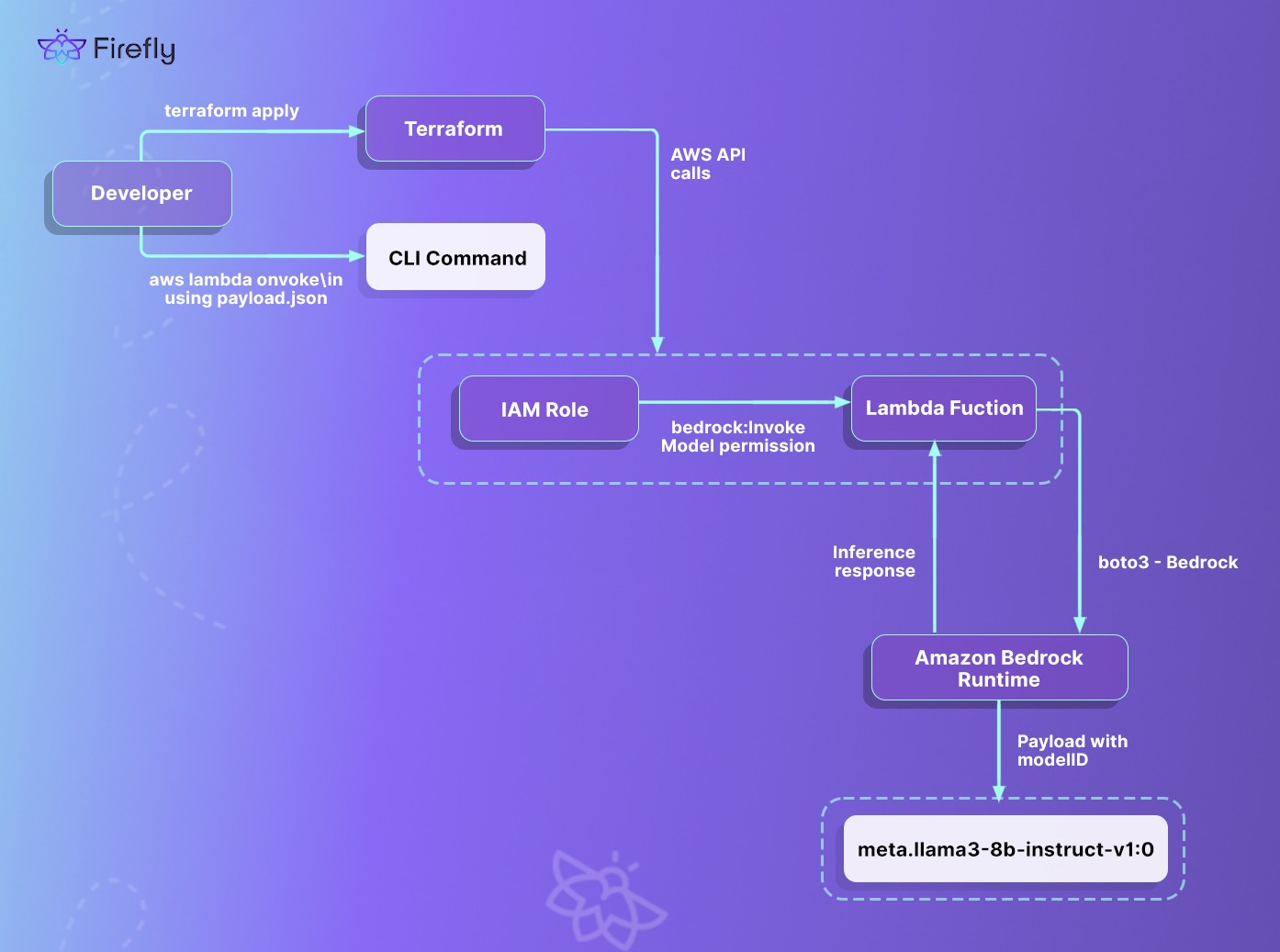
low below from Terraform provisioning through AWS Lambda to Bedrock runtime, including IAM role configuration and model invocation
Terraform Configuration (main.tf)
The setup uses the AWS provider with the region passed via a variable. The configuration defines:
- An IAM role for the Lambda function
- An inline policy allowing bedrock:InvokeModel
- A managed policy attachment for basic Lambda execution
- A Lambda function resource referencing a zip archive
Lambda Code (handler.py)
The Lambda function uses the Bedrock Runtime SDK (boto3) to send a prompt to the Llama 3 model and return the generated text in the response.
Initialize and apply the Terraform configuration above. After deployment, the Lambda function will be available to invoke the Bedrock-hosted model.
Invoking the Lambda via CLI
Create a JSON payload with a custom prompt:
Save the file as payload.json, then invoke the function using the function:
Inspect the response: cat response.json | jq
The output contains the generated response of the prompt passed in payload.json
.png)
Abstracting Bedrock IaC for Teams Using Firefly and Thinkerbell
Firefly provides a platform-level abstraction to manage Terraform deployments through version-controlled automation, policy enforcement, and drift detection. When managing AWS Bedrock resources using Terraform, Firefly simplifies operational overhead by integrating directly with infrastructure workflows.
Self-Service Bedrock Infrastructure Using Thinkerbell AI
Firefly includes Thinkerbell AI, a prompt-based Terraform generator for platform resources. Without Thinkerbell, engineers and analysts would typically have to write Terraform (TF) configurations manually, researching resource syntax, defining variables, managing dependencies, and ensuring compliance with best practices. For complex infrastructures, this often means spending hours or even days drafting and validating Infrastructure as Code (IaC).
With Thinkerbell AI, this process is dramatically simplified. Instead of starting from scratch, you can describe the desired infrastructure in natural language, for example, “Create an AWS EC2 instance with a security group allowing SSH”, and Thinkerbell instantly generates deployable Terraform code. It eliminates the need to manually configure providers, resources, variables, and outputs, allowing teams to focus on architecture rather than syntax.
Example Use Case
For example, when you want to provision a Lambda function that uses Meta's Llama 3 model from Amazon Bedrock, including the correct IAM permissions and roles to allow bedrock:InvokeModel, you would simply input the following prompt into Thinkerbell AI:
Prompt:
Provision a Lambda function that uses Meta’s Llama 3 from Amazon Bedrock with correct IAM permissions and a role that allows bedrock:InvokeModel.
Thinkerbell AI will then generate the necessary Terraform configuration. Below is the output it produces:
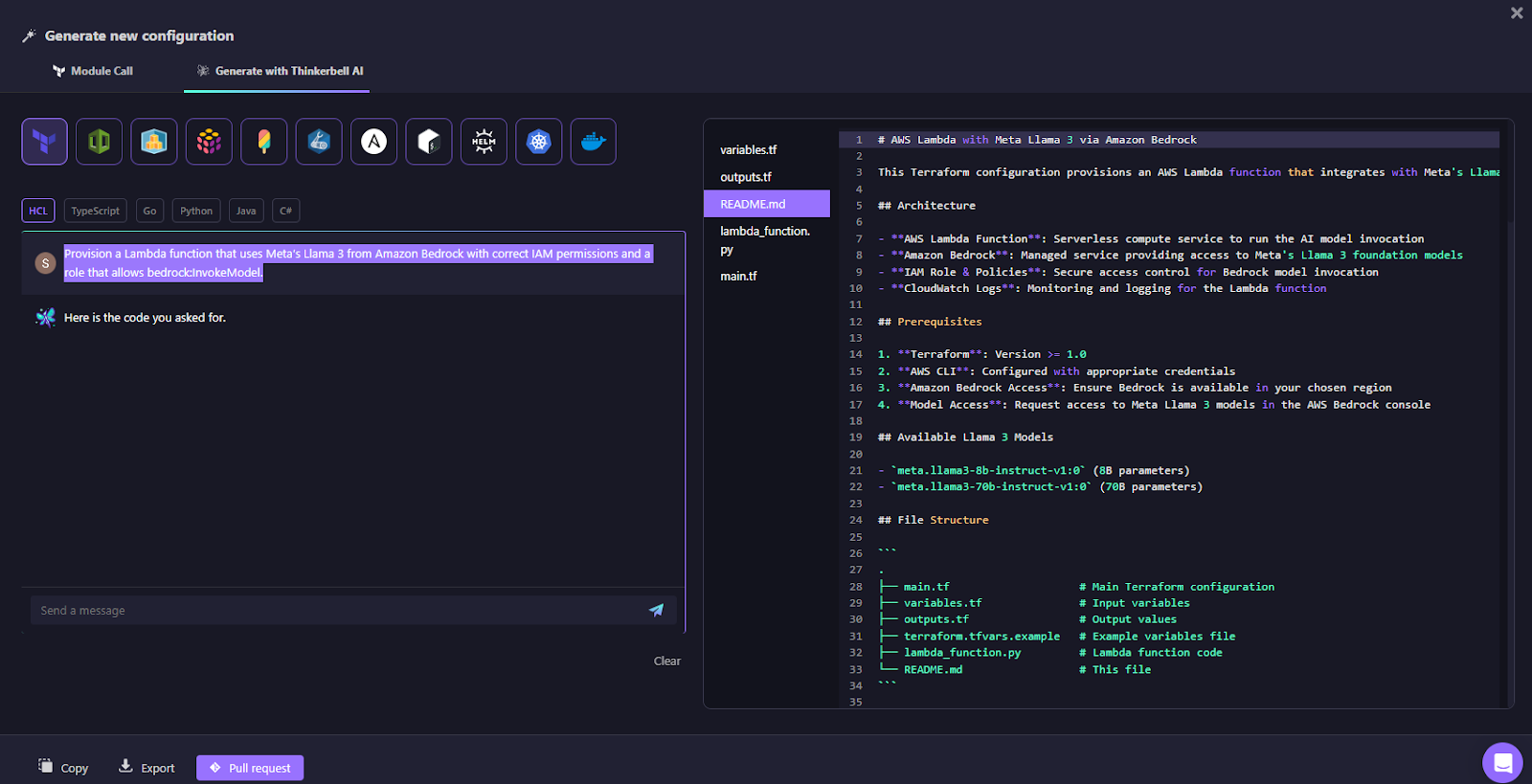
The code can be copied, exported, or pushed directly as a pull request from UI directly your existing github repo as shown in the below snapshot:
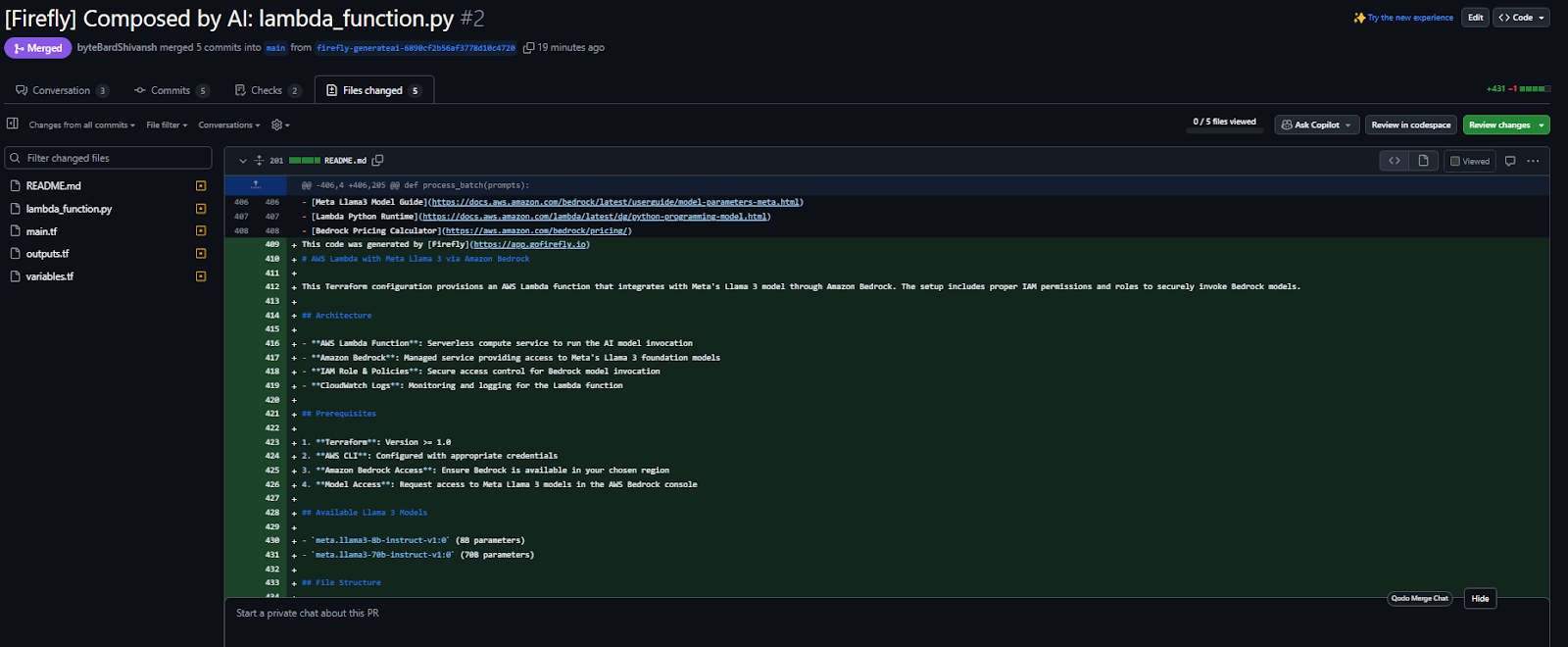
This out-of-the-box lowers the barrier for non-IaC users to contribute to Bedrock provisioning, without compromising on auditability or compliance.
FAQs
What’s the Difference Between AWS SageMaker and Bedrock?
SageMaker is designed for training, tuning, and deploying custom ML models with full infrastructure control. Bedrock is serverless and focused on inference, offering API access to pretrained foundation models like Claude and Llama 3. No infrastructure or training management is required.
Is Amazon Bedrock the Same as ChatGPT?
No. ChatGPT is OpenAI’s application built on GPT models. Bedrock is an AWS service that provides access to foundation models from multiple providers (Anthropic, Meta, Amazon, etc.), but it does not include OpenAI’s models.
How to Use Bedrock in AWS?
Use Bedrock via Console, CLI (bedrock-runtime), or AWS SDKs. Common usage involves invoking models like meta.llama3-8b-instruct-v1:0 using JSON payloads. Terraform can be used to automate agents, knowledge bases, and IAM configuration.
Is Amazon Bedrock a No-Code Platform?
No. Bedrock is low-code. You don’t manage infrastructure, but you still define prompts, handle API calls, and manage IAM. Tools like Firefly’s Thinkerbell reduce IaC complexity by generating Terraform from natural language prompts.
.webp)


.webp)















