
It starts small. You write seven lines of Terraform to create an S3 bucket for logs. A few months later, you’re managing 70 S3 buckets across dev, staging, and prod with versioning, encryption, replication, and policies, all codified in Terraform.
Then one day, your terraform plan shows a diff you don’t expect. Someone toggled replication off in the console during a test. Another team added a lifecycle policy during an incident but never backported it to code. A “temporary” POC bucket was created manually and forgotten. Over time, these ad-hoc changes accumulate, and your infrastructure no longer matches your Terraform files.
Even well-organized teams experience this. One engineer on Reddit described managing a single Terraform monorepo that covered VPC, RDS, and ECR for multiple microservices until they were asked to onboard additional services with their own CloudFormation stacks. That raised the classic dilemma: should the infrastructure for each service reside with its source code, or stay centralized in a single Terraform repository?
This is where drift begins. When environments are split across workspaces or repositories, and some changes happen via CI while others happen via console or CloudFormation, gaps form. Eventually, no one’s sure whether the Terraform code in main.tf or the resources in the cloud are the source of truth.
This isn’t a tooling problem, it’s the reality of scaling infra. Even with modules, CI/CD, and best practices, real-world operations (incident response, POCs, ad-hoc fixes) introduce drift. Teams may “deploy infra with code,” but they don’t always update code after production changes.
And when you’re juggling dozens of services and environments, even a change in a base module means triggering runs across multiple repos and updating each state file to keep everything aligned. That’s why drift detection can’t be just a post-mortem tool. It needs to be continuous. Actively comparing your cloud reality against what your code says it should be, and surfacing mismatches before they snowball into outages or misconfigurations.
Why terraform plan Isn’t Enough to Detect Drift
Terraform plan only compares two things:
- The desired infrastructure configuration, which is defined in your .tf files, and
- The last-known infrastructure state, which is stored in the .tfstate file.
It does not inspect the live cloud environment directly.
This means if any change has occurred outside of Terraform’s control, such as someone modifying a resource via the cloud console, an external automation tool, or an autoscaling event, Terraform won’t detect it unless the .tfstate is explicitly refreshed with the current state of the cloud. Even then, if the change was made to a resource that Terraform doesn’t manage or doesn’t exist in code, it won’t catch it at all.
Here are common scenarios where drift accumulates silently:
- Console changes during incidents: Engineers sometimes adjust security groups, IAM roles, or instance types manually during a production issue. These changes fix the problem but are often not backported to Terraform code, leaving the .tfstate unaware.
- Out-of-band automation: CI/CD pipelines, scripts, or third-party tools (e.g., kubectl, awscli, deployment managers) might create, update, or delete resources that Terraform never sees.
- Cloud-managed behavior: Services like AWS Auto Scaling, Google Cloud Instance Groups, or Azure’s managed databases frequently make automatic changes—like scaling node counts, rotating credentials, or modifying networking rules. These don’t update .tfstate.
- Stale or mismanaged state: Teams working in shared state backends (or with poor state locking) often experience inconsistent .tfstate files. Even in remote backends like S3, if locking isn’t correctly configured or cleanup fails, the state can go out of sync.
- Untracked resources: Not every cloud resource is necessarily codified. It’s common in large environments to find legacy resources or manually created components that were never added to Terraform. These exist in production, but Terraform has no visibility into them.
In all these cases, terraform plan will incorrectly report that “no changes are necessary,” because it’s only comparing the declared code and .tfstate, neither of which may reflect the actual state of your cloud infrastructure.
That’s why teams need something more than a plan, a mechanism that continuously compares live infrastructure with both Git and state, identifying drift even when Terraform isn’t aware of the changes. That’s the only way to catch discrepancies before they cause issues in production.
But even with continuous state refreshes and conservative usage patterns, large-scale Terraform deployments often become brittle, not just because terraform plan can't detect all drift, because the architecture itself doesn't support drift isolation. When a single Terraform plan spans hundreds of loosely related resources across environments, teams, and regions, pinpointing drift becomes nearly impossible. At that scale, drift isn't just a visibility problem; it's an architectural one.
Why the Monolithic Terraform Approach Breaks at Scale
A monolithic Terraform architecture manages your entire infrastructure, across all environments, regions, and services, using one large configuration and state file (or a small set of massive plans). Initially, this feels simple, but as your system grows, it becomes a bottleneck.
A single change (for example, updating a subnet in dev) triggers a full Terraform plan across all resources in every environment and region. Because Terraform must:
- Load all resources from a large state file,
- Refresh the state of every tracked resource to detect drift,
- Build a full dependency graph across thousands of resources,
- Compute potential changes across the entire infrastructure,
these plans frequently take 20+ minutes to complete, even if your actual change is unrelated to 99% of the resources being evaluated. This slows down delivery, increases engineer frustration, and blocks teams from making rapid, safe changes.
Additionally, drift detection becomes impractical because it is hard to isolate what drifted within a massive mixed-resource plan, while CI/CD pipelines slow down and cannot safely run in parallel due to global state locking and wide blast radius risks.
What Are Terraform Stacks?
Consider Terraform Stacks as “folders of responsibility” that cleanly split your infrastructure into smaller, targeted units you can manage independently.
Technically, a stack is a logical grouping of resources (and their Terraform state) for:
- a specific environment (dev, staging, prod),
- a specific region (us-west-2, eu-central-1),
- or a specific service area (networking, compute, IAM).
Each stack:
- Has its own .tfstack.hcl and .tfdeploy.hcl files, defining what modules to deploy, where to deploy them, and how many instances to deploy.
- Uses its own state file and backend, preventing unrelated resources from being evaluated during plan and apply.
- Isolates drift detection, IAM access, and CI/CD pipelines, allowing safe parallel deployments without global locking.
Instead of evaluating hundreds of unrelated resources on each plan, you evaluate only what is relevant to the change, dramatically reducing terraform plan and terraform apply times.
Why Break the Monolith Into Stacks?
The core issue with monolithic Terraform setups is a lack of isolation:
- No clear boundaries for execution and validation.
Example: Updating an S3 bucket policy in the staging environment requires a terraform plan that also evaluates VPCs, IAM roles, Kubernetes clusters, and databases in production across all regions, even though they are unrelated to your change.
- No separation of state management by environment, region, or service.
Example: A single state file tracks all resources, VPCs in us-west-2, EKS clusters in eu-central-1, and databases in us-east-1. If the state file gets corrupted, all environments are blocked until it is repaired, risking downtime across unrelated services.
- Every change risks impacting unrelated infrastructure, forcing full evaluations on each run.
Example: Adding a subnet in dev accidentally triggers unrelated IAM or DNS changes in prod, requiring an engineer to review a massive plan output across hundreds of resources before approving a small, intended change.
- Data sources in a monolith slow down planning.
Terraform uses data sources (e.g., data "aws_vpc" "selected" { ... }) to query real-world resources like VPCs or subnets dynamically during terraform plan. In a monolithic setup, all data sources across all environments and regions are queried on every plan, even if your change only needs one, further increasing plan times and risking failures due to transient API rate limits or credentials issues in unrelated regions.
What Changes When Using Stacks?
With Terraform Stacks, you decompose your monolith into targeted, isolated units (stacks) such as:
- networking/dev/us-west-2
- compute/staging/eu-central-1
- iam/prod/global
Each stack has its own state file, backend, and plan/apply scope, so changes are evaluated only for the resources they manage.
Example After Using Stacks:
You need to add a subnet in dev in us-west-2:
- You run terraform plan in the networking/dev/us-west-2 stack.
- Only the resources in that stack (e.g., VPCs and subnets in us-west-2, dev) are evaluated.
- The plan completes in under a minute, showing only the intended subnet addition.
- There is no risk of affecting unrelated IAM roles in prod or clusters in eu-central-1.
- Other teams can safely deploy changes to their stacks in parallel without conflict.
Stacks turn Terraform workflows from a global, fragile bottleneck into modular, autonomous pipelines, enabling faster, safer, and scalable infrastructure delivery.
Benefits of Moving to Stacks
Adopting Terraform Stacks transforms infrastructure workflows:
- Execution becomes fast: Plans and applies are completed fast because they only process the resources within a single stack.
- CI/CD pipelines parallelize safely: Multiple stacks can run Terraform plans and apply simultaneously without locking unrelated resources.
- Drift detection becomes practical: Tools like Firefly can check drift at the stack level without parsing a massive, mixed-context plan.
- IAM becomes safer: Least-privilege access policies can be enforced per stack scope.
- Deployments become repeatable: You can deploy consistent infrastructure across environments and regions without duplicating configurations.
In practice, Stacks transform Terraform from a slow, global workflow into modular, independent pipelines aligned with how teams operate.
Why Firefly Complements Stacks
Managing Terraform stacks natively means juggling scattered .tfstate files, drift detection scripts, backend configurations, and ad-hoc compliance checks. Each state file lives in S3, GCS, or Terraform Cloud without a central view, making it hard to answer simple questions like:
- Which Terraform version is this stack running?
- Has this stack drifted from its IaC source?
- Which modules are outdated, and what’s the blast radius if I upgrade them?
- Where exactly is the backend storing state?
Firefly’s IaC Explorer solves this problem by centralizing all Terraform stacks into a single, navigable interface.
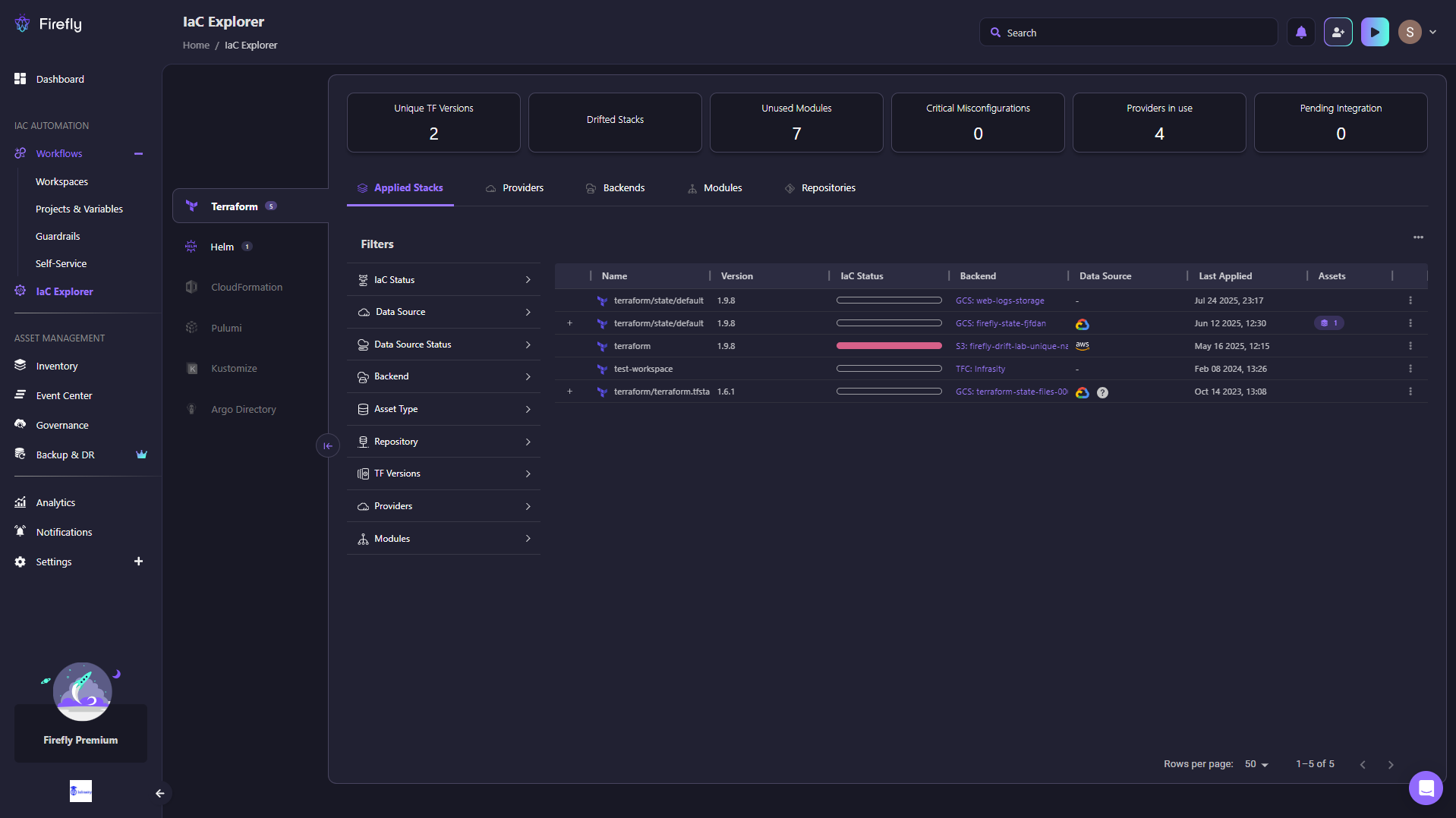
In the snapshot above, Firefly’s IaC Explorer shows:
- Unique TF Versions (2) tracked across the environment.
- Drifted Stacks flagged instantly without running a manual terraform plan.
- Unused Modules (7) surfaced for cleanup.
- Providers in Use (4) with clear visibility into backend locations (GCS, S3, TFC).
- Stack-level details, including version, backend, data source, last applied date, and assets, are all accessible without grepping through state files.
With this view, platform engineers can monitor all stacks across environments from a single dashboard, detect drift automatically without relying on a manual terraform plan, and understand the blast radius of changes through outdated module warnings. They can also audit compliance by exporting filtered stack views and navigating module trees to see exactly how dependencies are wired. Together, Terraform Stacks and Firefly deliver a modular, fast, and observable infrastructure delivery system, something that would otherwise require stitching together scripts, state explorers, and dashboards by hand.
Your Drift Visibility Ends at the Stack Boundary
Splitting the monolith into smaller stacks solves some problems, faster plans, reduced blast radius, and clearer ownership. But it introduces a new kind of blind spot: drift becomes harder to see across the system as a whole.
Each stack only sees what it manages. If you have 40+ stacks across networking, compute, IAM, data, and platform layers, there’s no single command that tells you what’s out of sync across all of them. Running terraform plan in each repo only reveals drift within that specific scope, and only if the .tfstate is up-to-date and reflects what’s in the cloud.
Worse, many real-world issues involve dependencies between stacks. For example:
- A networking stack adds a new security group rule, but the application stack still expects the old CIDR range.
- A database password is rotated manually for an incident, but the config stack doesn’t know, and applications silently fail on restart.
- A resource created via an out-of-band script (e.g., to unblock a pipeline) never gets codified into any stack, and no team knows it exists.
No amount of decomposition fixes this. It just scopes the problem down; it doesn’t solve it. You now have to track drift across dozens of partial views, each limited by what their Terraform config defines.
This fragmentation makes it even easier for untracked resources and state inconsistencies to creep in. Teams start relying on tribal knowledge and Slack threads to remember what’s “real,” and infrastructure hygiene slowly degrades.
That’s where a centralized view, one that scans live infra and compares it to both your .tfstate and Git, becomes important. Without1x it, drift remains invisible until it breaks something.
Beyond Plan: How Firefly Detects Drift Across Code, State, and Cloud
Firefly doesn’t rely on just .tf files and .tfstate like Terraform does during terraform plan. Instead, it continuously monitors your infrastructure by comparing three distinct sources of truth:
- Terraform Code in Git: This is your intended configuration.
- Terraform State File: This reflects the last-known infrastructure state according to Terraform.
- Live Cloud Environment: This is the actual deployed infrastructure across AWS, Azure, GCP, etc.
Firefly continuously syncs and cross-references these layers. So even if a resource was manually changed in the cloud, created outside of Terraform, or deleted by a script that bypassed the Terraform workflow, Firefly can detect the discrepancy, because it isn’t limited to just what's under Terraform’s control.
Here’s how this works in practice:
- If a resource exists in the cloud but not in code or state, Firefly flags it as unmanaged drift, indicating that someone created it manually or via another tool.\
- If a resource exists in state but not in cloud, it’s marked as missing, likely deleted outside of Terraform.
- If a resource exists in code but not in cloud or state, Firefly treats it as planned but not yet provisioned.
This three-way comparison gives teams a complete, accurate view of their infrastructure posture, far beyond what terraform plan alone can provide. It answers a critical question Terraform itself doesn’t ask: “Is the cloud behaving the way we actually defined in Git?”
And because this process is automated and continuous, Firefly can catch drift as it happens, not just when you happen to run a plan.
Drift Detection in a GCP Terraform Environment
To demonstrate how real-world drift appears, and why it's often missed, we ran a drift scan against a representative GCP setup using modular Terraform configurations.
Infrastructure Overview
This environment mirrors what’s typical across many production-grade cloud estates:
- A custom VPC with three subnets
- 5 Compute Engine instances, deployed through a shared module
- 10 GCS buckets, each created using a storage module
- IAM bindings for admin and viewer roles
- One Cloud Monitoring alerting policy
- State stored remotely in a GCS bucket via the gcs backend
Modules were structured cleanly: network, compute, storage, iam, monitoring, and all variables were injected through terraform.tfvars.
Initial apply succeeded:
After deployment, drift was introduced manually using the GCP Console and CLI, a common occurrence in teams responding to incidents or testing changes.
| Drift Type | Example |
|---|---|
| Missing tags | Label removed from prod-data-bucket-3 via console |
| Firewall change | Temporary debug port left open |
| Ghost infra | web-server-3 deleted manually, but still in config |
| IAM inconsistencies | Extra viewer role added via console |
| Untracked resource | A test GCS bucket created via CLI, never codified |
These changes silently diverged from Terraform code and state, with no alerts or errors.
Underlying Causes: Modules and Manual Patching
Many of the drifts traced back to issues in Terraform modules themselves — especially shared, public ones.
For example, Bridgecrew's 2020 analysis of Terraform modules found nearly half lacked basic best practices like:
- Enabling audit logging
- Default encryption
- Lifecycle or retention rules
When these get deployed, engineers often patch them manually in production, but don’t update IaC, introducing long-lived, invisible drift.
Monolithic or tightly coupled modules make this worse. A 2025 study on Terraform anti-patterns found that teams often avoid updating these modules due to:
- Fear of breaking dependencies
- Unclear ownership across teams
- Difficulty tracking what changed and where
Over time, these environments drift farther from their intended design, while still appearing “healthy” in CI pipelines.
How Firefly Solves Drift at Scale
Traditional workflows rely on terraform plan to detect infrastructure drift. But that only compares your code (.tf files) to your Terraform state (.tfstate), not to what's actually running in the cloud.
Firefly closes this gap by continuously reconciling:
- Your IaC in Git (the intended configuration).
- The Terraform state (what Terraform thinks exists), and
- The live infrastructure (queried from cloud provider APIs in real time).
This enables accurate drift detection, contextual analysis, and codified remediation, all while preserving Git as your source of truth.
Drift Automation with Firefly Projects
When you're managing hundreds of environments, cloud accounts, and teams, detecting drift manually becomes impossible. Firefly Projects solves this with structured automation.
With Projects, you can:
- Organize workspaces by team, environment, or cloud provider (e.g., /aws/dev/frontend)
- Define periodic drift detection schedules at the project level
- Automatically inherit configurations across all nested sub-projects and workspaces
- Apply RBAC for team-specific access and audit control
Example: Set a default drift detection plan to run every 5 hours at the /dev project level, and all child resources automatically inherit this.
Here’s what the project creation UI looks like when defining a drift plan:
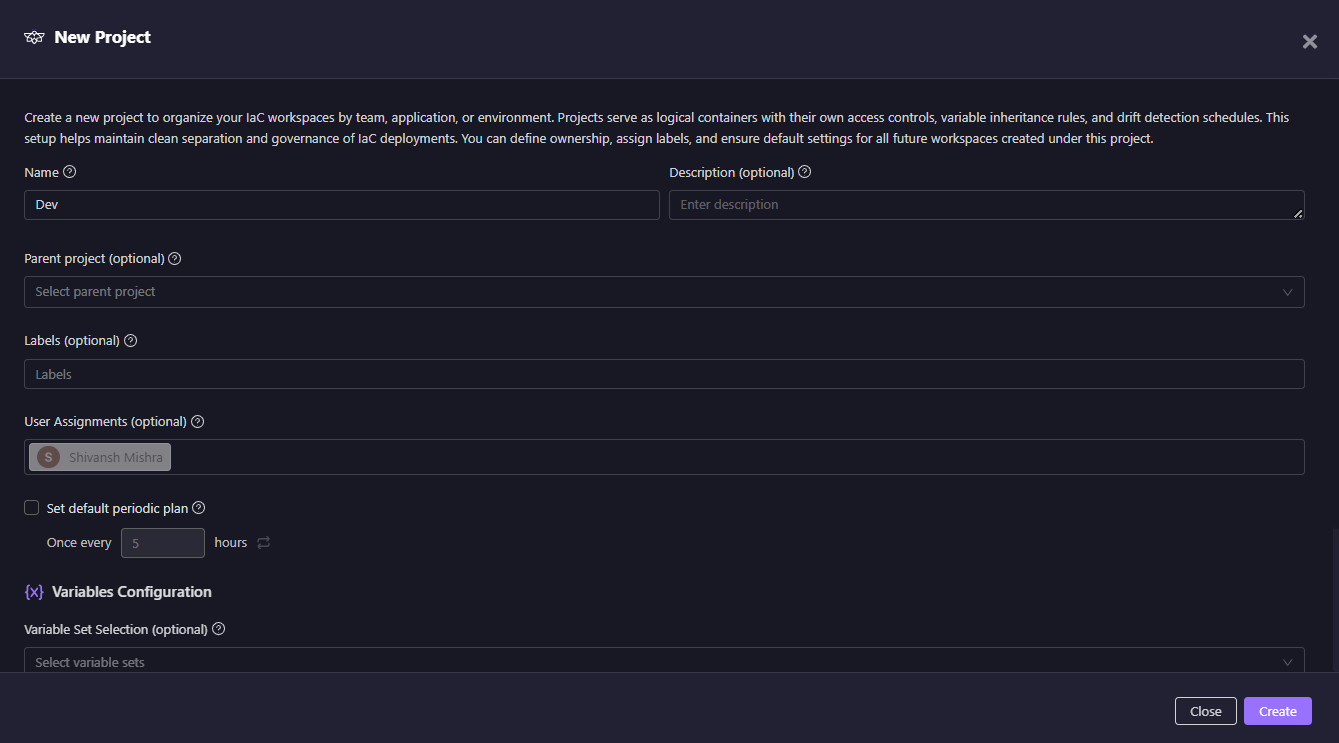
The above form lets you:
- Name the project and define its hierarchy
- Assign users with Viewer/Admin roles
- Apply classification labels (e.g., env:dev, team:platform)
- Configure variable sets and custom variables at the project level
This makes drift detection not just continuous, but also hierarchically scalable and team-specific.
Inventory View: Real-Time Cloud Visibility
Firefly provides a Cloud Asset Inventory, a centralized dashboard showing all resources across cloud accounts, regions, and tools. You get rich metadata for every resource type, provider, region, tags, ownership, Git linkage, drift status, and more.
You can filter by environment, IaC status, drift type, or compliance flags, and even isolate unmanaged or ghost resources across clouds.
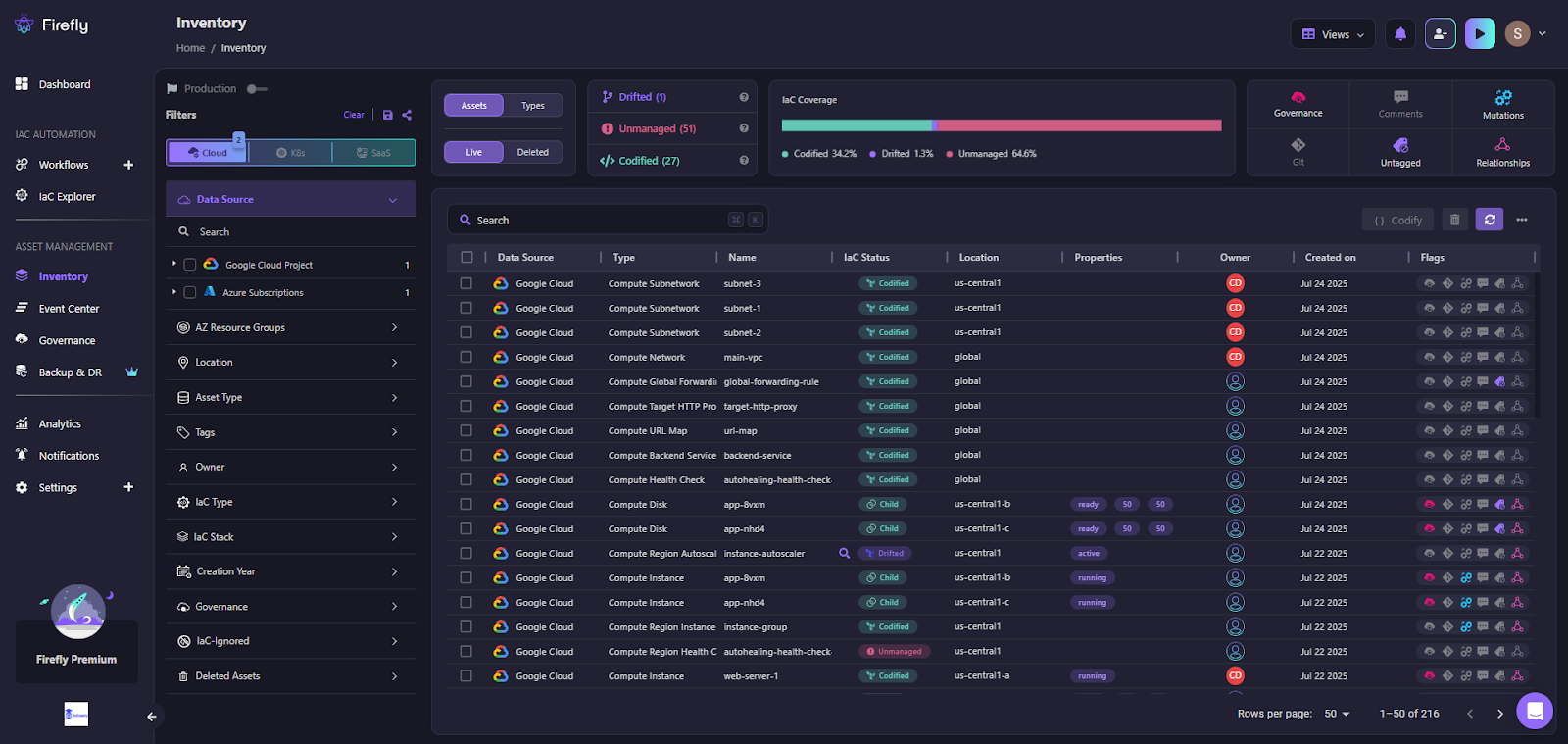
The Firefly Inventory dashboard shows all resources across accounts, with flags for drift, policy violations, and Git tracking.
This high-level view helps teams instantly answer:
- What’s unmanaged or non-compliant?
- Which assets are drifting?
- Who made the last change, IaC or manual?
Resource Deep-Dive & Git Traceability
Clicking into any asset opens its details panel, where Firefly reveals:
- Core metadata (cloud source, tags, creation date),
- Git commit information if managed by code.
- Policy violations, and
- Links to code, console, and commit history.
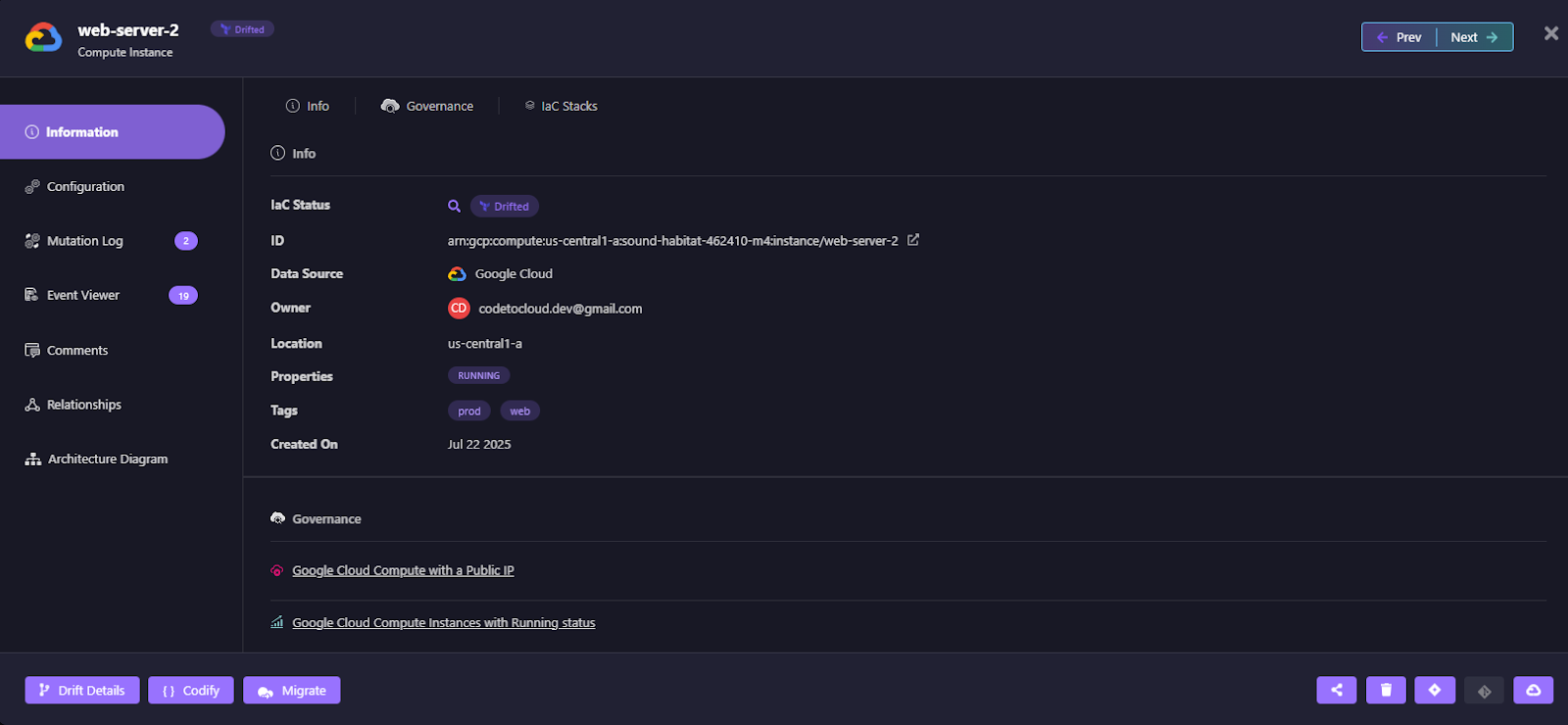
Detailed view of a GCP Compute instance named web-server-2, showing IaC linkage, Git metadata, and direct links to source and cloud console.
This empowers platform teams to:
- Track who changed what, and when.
- Understand infra lineage, and
- Take informed actions like codifying or remediating.
Drift Detection & Side-by-Side Comparison
Firefly continuously scans for drift using cloud event data (like AWS CloudTrail or GCP Audit Logs) and API polling. When drift is detected, it’s marked clearly in the UI, and you can explore a side-by-side diff between the IaC definition and the current live configuration.
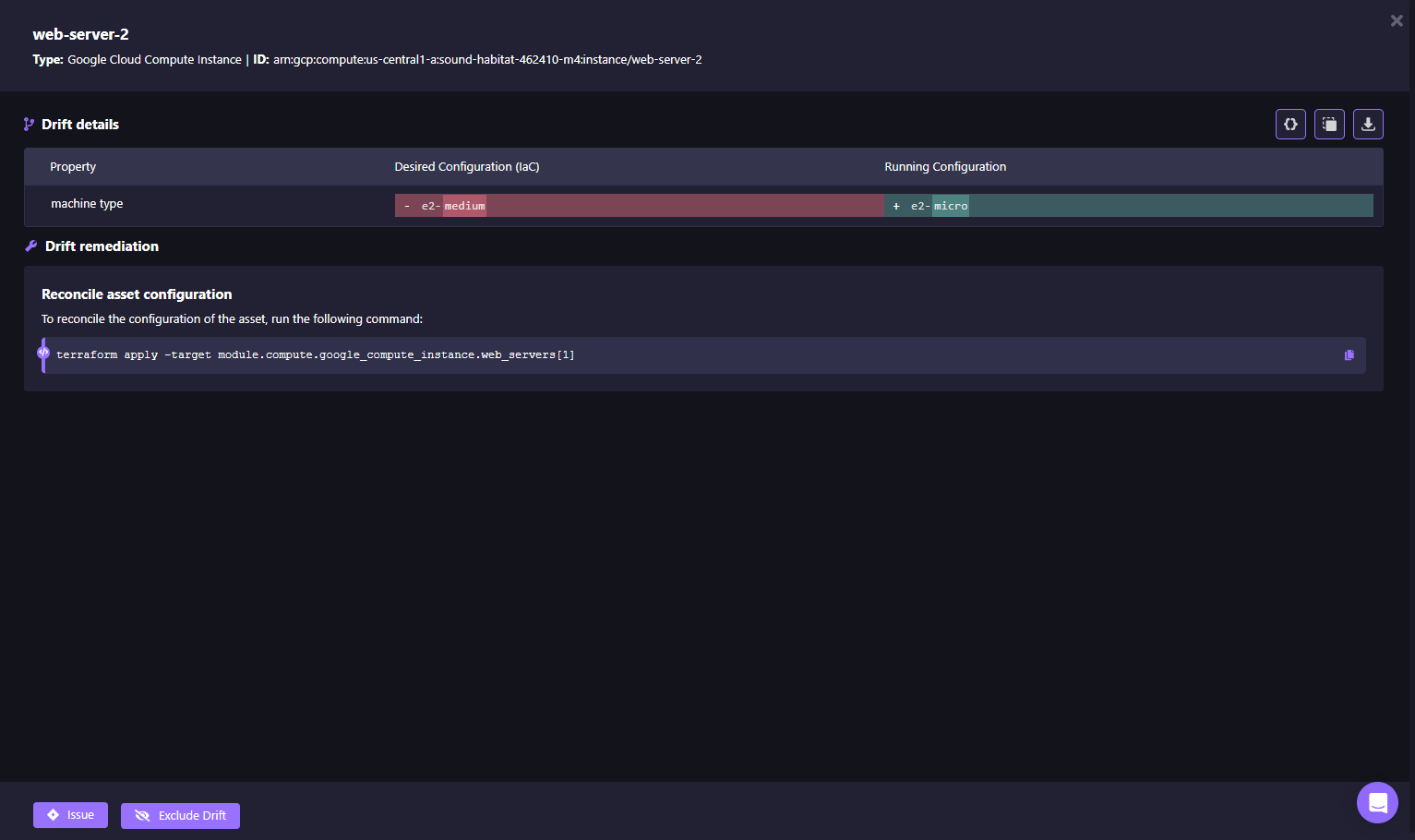
Firefly also auto-generates a Terraform code fix, or a command-line action if preferred. You can either:
- Apply changes directly.
- Generate a pull request to codify the fix in Git, or
- Use the CLI suggestion to reconcile manually.
FAQs
What is Drift in Cloud Computing?
Drift in cloud computing occurs when the actual state of cloud resources differs from the intended state defined in Infrastructure-as-Code (IaC) configurations. This can happen due to manual changes, automated processes, or external tools modifying resources outside of the IaC workflow.
How to Fix CloudFormation Drift
AWS CloudFormation can detect drift by comparing the current state of resources with your stack templates. You can review detected differences and remediate drift by updating your templates, reverting manual changes, or importing unmanaged resources into your stack to realign with your desired configurations.
What is an Example of Configuration Drift?
A common example is manually modifying an AWS security group to open SSH (port 22) for a wider IP range, while your IaC configuration (e.g., Terraform or CloudFormation) still defines a restricted rule. This creates a discrepancy between the actual deployed state and the declared configuration, potentially introducing security risks.
Is Terraform a Configuration Management Tool?
Terraform is primarily an Infrastructure as Code (IaC) tool focused on provisioning and managing cloud infrastructure. It is not a configuration management tool like Ansible, Chef, or Puppet, which are designed to manage the state and configuration of software on existing infrastructure.
.webp)


.webp)















