
TL;DR
- Agentic AI refers to AI software that can observe live environments, decide what needs to change, execute actions against real systems, verify outcomes, and continue operating toward a defined goal without waiting for constant human input.
- In cloud infrastructure operations, agentic IaC means continuously comparing live cloud environments against declared infrastructure definitions, detecting drift and unmanaged resources, generating and validating remediation changes against policy and governance controls, and executing operational workflows autonomously with appropriate approval guardrails, without requiring an engineer to initiate each step.
- AI coding assistants can generate infrastructure code when prompted, but autonomous infrastructure operations require continuous cloud visibility, policy validation, workflow orchestration, and remediation capabilities that operate independently of human initiation.
- Firefly implements this agentic loop through live cloud inventory, codification, drift detection, guardrails, and automated workflows, accessible through its AI SRE interface and via MCP integrations with tools like Claude Code and Cursor.
You've probably seen the word "agentic" everywhere lately, such as agentic AI, agentic workflows, and agentic platforms. The idea behind the term is simpler than the marketing around it: instead of waiting for a human to trigger every action, the system keeps working toward a goal on its own.
Most AI tools engineers use today, like ChatGPT, Copilot, and Claude, are generative and reactive. You prompt them, they generate the IaC, and they stop. You paste an error into Claude and get an explanation along with a suggested fix. You ask Copilot to write a Terraform resource, and it generates the config for it. But the AI is only as aware as the context you hand it, so a Security Group that drifted at 3 am stays unknown until an engineer opens a console.
You define the goal, and an agentic system keeps operating toward it, watching the environment, deciding what needs to change, taking action against real systems, checking the result, and repeating the cycle continuously.
Applied to infrastructure, imagine a system watching your cloud environment around the clock. A Security Group change in the AWS console outside Terraform. The system detects the drift, generates the Terraform update needed to reconcile it, validates the change against policy, and runs the remediation workflow before the issue turns into a production incident.
Agentic IaC is infrastructure that manages the gap between what your code declares and what your cloud actually runs, continuously, without waiting for an engineer to notice something is wrong.
This post covers what agentic IaC is, why standard IaC leaves that gap after Day 1, and how the loop works in practice, including the two ways it happens today and the governance needed before any agent touches production.
What Agentic IaC Actually Is, and Why IaC Alone Doesn't Get You There
In cloud infrastructure operations, agentic behaviour looks like this: a system continuously reads the live state of your AWS, Azure, or GCP environment, compares it against what's declared in Terraform, identifies drift or unmanaged resources, generates the Terraform changes required to reconcile the difference, validates those changes against policy, executes the remediation workflow, and verifies the outcome, then repeats the cycle again.
A Security Group change in the AWS console. An S3 bucket gets created outside Terraform. An engineer modifies an RDS instance directly in production. The system detects the change, determines whether it violates the desired IaC state, generates the corrective action, and routes or applies the remediation based on governance rules. That's agentic IaC.
And because a standard Infrastructure-as-Code workflow stops long before this point. IaC solved the Day 1 provisioning problem.
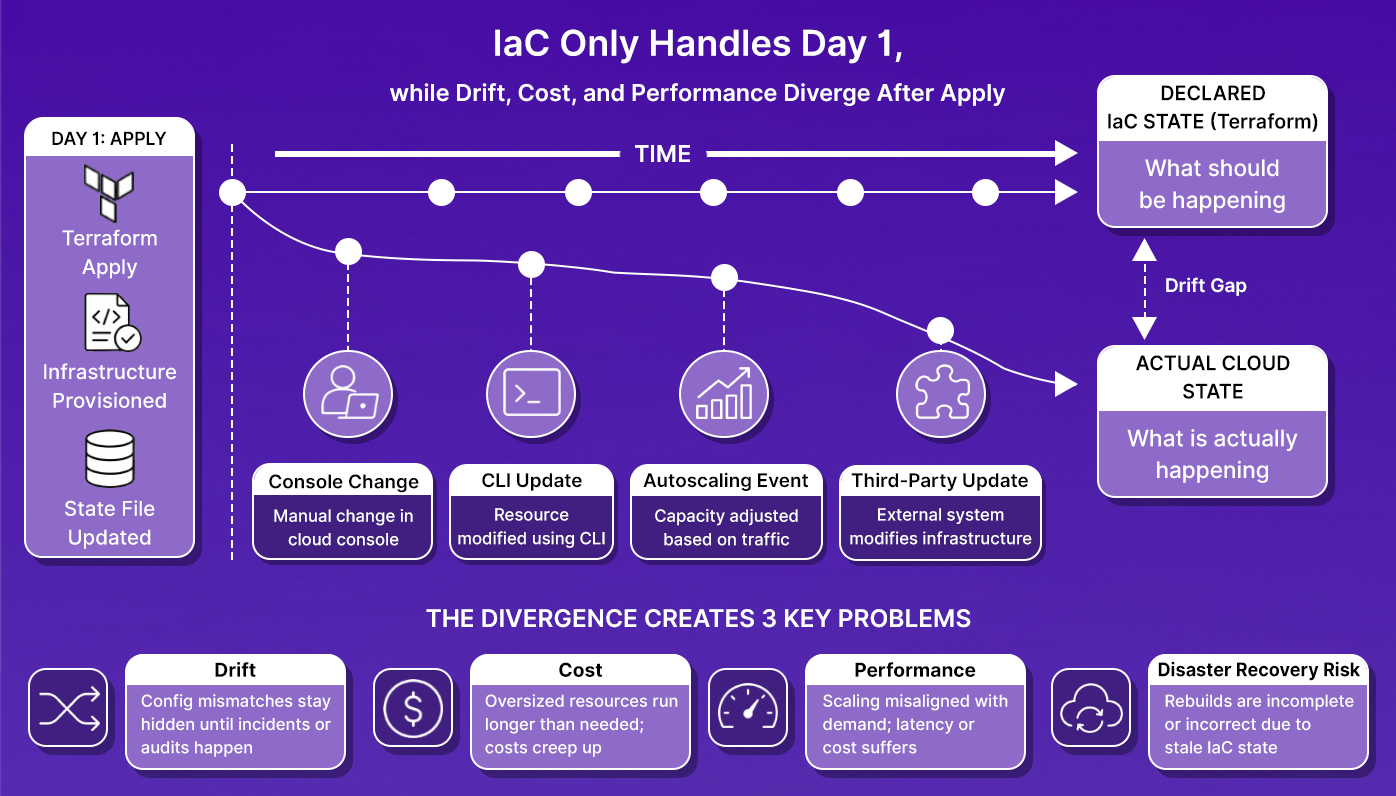
Instead of creating infrastructure manually through cloud consoles, teams could define cloud resources declaratively in Terraform, store them in Git, review changes in pull requests, and consistently recreate environments.
But after the initial deployment, infrastructure keeps changing while Terraform remains static unless someone actively maintains alignment between them.
Four operational gaps start accumulating:
1. Drift
A developer temporarily opens a Security Group port in the AWS console for debugging. Terraform still declares the port closed. The live cloud state and the declared IaC state have diverged, but nothing automatically reconciles them.
2. Unmanaged resources
Resources created before Terraform adoption, provisioned manually, or spun up outside approved workflows never enter Terraform state. Since Terraform doesn't know they exist, drift detection, policy evaluation, and lifecycle management never apply to them.
3. Cost overruns
An oversized RDS instance or overprovisioned Kubernetes node pool reaches production because nothing evaluates infrastructure cost impact during the operational workflow itself. The problem only surfaces later through billing alerts.
4. Policy violations
A Terraform configuration can pass terraform plan while still violating security or governance requirements. An unencrypted database, missing tags, or overly permissive IAM policy may still deploy successfully unless policy validation exists outside Terraform syntax checks.
According to Firefly's State of Infrastructure-as-Code 2026 report, 90% of practitioners say their IaC orchestration falls short. Nearly half make production changes outside IaC at least a few times a week. One in three has experienced a production incident caused by infrastructure drift.
Agentic IaC exists to close that operational gap. Instead of waiting for an engineer to notice a problem, investigate the cloud environment, generate the Terraform fix, validate it, and run remediation manually, the system continuously operates that observe-detect-remediate loop on its own. The question is what infrastructure and control layers are required to make that work safely in production.
The Agentic IaC Loop: Observe, Detect, Plan, Validate, Apply, Confirm
Every agentic IaC system, whether a coding agent wired to a Terraform runner or a dedicated platform, executes the same underlying loop:
1. Observe: Read live cloud state: actual resource configurations, IDs, dependency relationships, and cost data from AWS/Azure/GCP APIs. Not a snapshot from the last Terraform refresh. The current state of every resource in the account is updated continuously.
2. Detect: Compare live state against declared Terraform state. A Security Group rule opened in the console, a VM resized outside Terraform, a resource provisioned manually with no state entry, a tag missing from a resource that policy requires it on — all of these show up as divergence here.
3. Plan: Generate the Terraform change that closes the gap. For a drifted Security Group: update the ingress block. For an unmanaged EC2 instance: generate the full resource block, the import block, and every dependent resource (IAM Role, VPC, Subnet, Network Interface, EBS volume) resolved automatically, not manually traced across four console tabs.
4. Validate: Run every generated change through policy rules before apply. Cost rules: Does this increase monthly spend beyond the threshold? Security rules: Does this open a port that compliance requires to be closed? Resource rules: Does this delete a protected resource? Tag rules: Does every resource in this plan carry the required tags? Changes that fail get blocked or routed to a human approval gate, not applied.
5. Apply: Execute terraform plan to surface the blast radius, then terraform apply, either autonomously for low-risk changes or after a human approves via PR comment or Slack, depending on the configured workflow.
6. Confirm: Check that the applied change produced the expected state. Log every action: what ran, what changed, who approved, and what the outcome was. Feed the result back into step 1.
The loop runs continuously. A script runs when triggered and stops. If a Security Group drifts at 3 am and no one triggers the script until Monday morning, the drift remains open for 60 hours. The loop detects and remediates it within minutes of the console change, with no human in the initiation path.
Now let's look at what happens when the agentic loop doesn't exist, and an engineer has to run each step manually, mid-incident.
When an Incident Exposes How Much of Your Infrastructure Was Never in Code
Scenario: A connectivity issue surfaces in production. Requests to the checkout service are timing out. An engineer opens a ticket and starts investigating, not a planned codification effort, just a routine support dig.
Step 1: The investigation starts with the VPC
The engineer pulls up the VPC (vpc-03824eb...) in the AWS console to check routing. While reviewing it, they notice resources attached to the VPC that aren't referenced anywhere in Terraform: a Subnet, a Default Network ACL, DHCP Options, and a Route Table. The VPC itself has no aws_vpc resource block in the state file. It was provisioned manually 18 months ago, and Terraform has been working around it ever since.
Step 2: Pulling the VPC thread unravels the application stack
The engineer follows the Subnet to find what's running inside it. There's an EC2 instance, checkout-vm, also unmanaged. Clicking in reveals more: a Launch Template, an IAM Instance Profile, an IAM Role, two Security Groups, a Network Interface, and an EBS volume. Eleven resources, none in Terraform state, all running in production.
The connectivity issue is still unresolved. Three hours into dependency mapping. Original problem untouched.
Step 3: Codifying manually while an incident is open
To make any infrastructure change safely, adjust a Security Group rule or modify the Route Table, the resource needs to be under Terraform management first; otherwise, the change goes in via the console and creates more drift. So codification starts mid-incident: look up resource IDs across EC2, IAM, VPC, and networking consoles (each using a different ID format, ARN for IAM roles, resource ID for security groups, allocation ID for network interfaces), write each aws_*resource block, write each import block, run terraform import per resource, run terraform plan, fix attribute mismatches, run plan again until zero diff.
The connectivity issue was a misconfigured Security Group rule. It took 20 minutes to fix once the resource was under Terraform. The other three hours were spent discovering and codifying infrastructure that should have been in code from the start, but nothing surfaced until an incident made the gap visible.
An agentic IaC loop running continuously before the incident would have flagged checkout-vm and its eleven dependencies as unmanaged during the last inventory scan. The engineer would have started at the Security Group rule, not spent three hours finding it.
Two Ways Agentic IaC Works
Agentic IaC isn't a single product category. It emerges from two different directions, and understanding the difference matters for knowing what you're actually getting.
Path 1: AI Coding Agents With Live Cloud Context (Claude Code + Firefly MCP)
Out of the box, coding agents like Claude Code, Cursor, or GitHub Copilot work with .tf files in the IDE. It generates Terraform when prompted, but it has no view of what's actually running in the cloud account. Ask it "list all running VMs in my AWS account," and it can't answer, because it has no access to live cloud state.
Connect Firefly's MCP server to Claude Code, and that changes. Here's what an actual session looks like:

One prompt. Live cloud state, actual instance IDs, AZs, public IPs, and IaC status, pulled directly from Firefly's inventory. The agent identifies that both checkout-vm instances are unmanaged and flags them as codification candidates, without the engineer having to open a single AWS console tab.
From here, the engineer can ask Claude Code to codify either instance, and Firefly's codification-api___codify-asset tool generates the complete Terraform config with import blocks pre-filled with the real instance ID (i-01db882bd4eb265b2), all dependent resources resolved, and the HCL ready for PR.
The gap that made Path 1 reactive, with no live cloud state, is closed by the MCP connection. The engineer still initiates each query, but the answers come from what's actually running, not from a stale .tf file or training data.
Path 2: A Platform That Runs the Full Loop Continuously
Autonomous agentic behavior, the kind where drift is detected at 3 am without anyone noticing and remediated before the on-call engineer is paged, requires the platform itself to run the full loop without a human in the initiation seat. That means five capabilities running continuously:
- Perception: Continuous scanning of live cloud APIs, not a Terraform refresh on demand, but a real-time inventory that updates as resources change.
- Planning: Comparing live state against Terraform state to identify what's drifted, what's unmanaged, what violates policy, and what sequence of changes closes each gap.
- Reasoning: Evaluating each proposed change against cost rules, security policies, blast radius constraints, and tag requirements before deciding whether to apply autonomously or route to a human approval gate.
- Tool calling: Executing Terraform plan and Terraform apply, opening PRs to Git, posting Slack notifications, triggering CI/CD pipelines, and generating remediation steps.
- Memory: Maintaining full deployment history, drift event logs, and policy evaluation records across every workspace, so every decision has context from prior state.
The two paths aren't mutually exclusive. Teams use Claude Code with Firefly MCP for interactive, engineer-initiated queries and codification; Firefly's platform runs the continuous autonomous loop when nobody is watching. Both rely on the same six-step cycle; the difference is who initiates it.
How Firefly Implements the Agentic Loop with One Platform, Not Five Dashboards
Without a unified platform, answering a single question like "which resources should I codify first?" requires an engineer to open the Inventory to see 5,644 resources, 432 unmanaged, 79.6% outside Terraform, as shown in the snapshot below:

Then switch to Event Center to find which of those 432 have active ClickOps changes, then switch to Governance dashboard to check which ones are violating policy, then manually correlate the three lists in a spreadsheet to produce a priority order:

That's before writing a single line of Terraform. The "AWS Subnet Without VPC Flow Logs Enabled" policy flags 54 violating assets, but without cross-referencing Inventory and Event Center, there's no way to know which of those 54 are actively being changed by hand, which are already codified, or which sit in a VPC where a single aws_flow_log resource would cover all of them at once. The engineer makes a guess, picks a resource, and starts the manual codification process, the same 30–60 minutes per resource, per dependency, per ID lookup that the incident scenario showed.
The same pattern repeats for every investigation. "What caused the service interruption?" means opening Event Center, filtering by timeframe and action type, finding the relevant events, then opening Inventory to check IaC status for each affected resource, then opening Governance to check for policy violations, three tabs, manual correlation, no guarantee the engineer has connected the right dots. And if a Security Group was changed in the console three days ago, but nobody queried Event Center that day, the drift sits undetected until something breaks.
Firefly implements all six steps of the agentic loop on a single platform: Inventory, Codification, Drift Detection, Workflows, Guardrails, and Event Center, connected by a single, continuously-updated inventory of every resource and dependency. Here's where each agentic property actually lives in the platform:
- Perception: Firefly's inventory scanner continuously reads live cloud state across AWS, Azure, GCP, and Kubernetes. The 432 unmanaged resources and 54 subnet violations aren't discovered when an engineer opens a dashboard; they're known the moment they exist, because the scanner runs continuously regardless of whether anyone is looking.
- Planning: When the AI SRE correlates ClickOps frequency against unmanaged resource status and policy violations, it's doing what a human analyst would do manually across three dashboards, except it's doing it in response to a single prompt, with the full dataset, in seconds. The prioritized codification plan is the output of planning: which resources to address, in what order, and why.
- Reasoning: Guardrail rules evaluate every Terraform plan output before apply runs. The system reasons: Does this change increase monthly spend beyond the threshold? Does it open a port that compliance requires to be closed? Does it delete a protected resource? Changes that fail get blocked or routed to a human approval gate; the system makes a decision, not just a flag.
- Tool calling: When a Workflow triggers Terraform plan on a PR, applies on merge, opens a PR to GitHub with 315 lines of codified Terraform, or posts a Slack notification for an approval gate, those are tool calls. When the Firefly MCP server calls inventory-api___search-inventory twice to cross-reference subnets against flow log resources, then returns the Terraform for_each remediation pattern, that's tool calling from the IDE.
- Memory: Every plan, every apply, every drift event, every Guardrail evaluation, and every remediation is logged in Event Center. When the AI SRE investigates "what happened in the last 3 days," it's reading from that memory, the full history of what the system observed, decided, and did, not reconstructing it from scratch.
The engineer doesn't switch dashboards. They either query the AI SRE in natural language from inside the platform, or query the Firefly MCP server from their IDE in Claude Code or Cursor. Both surfaces expose the same agentic loop; the difference is where the engineer is sitting.
Inside the platform with Firefly’s AI SRE Agent
Firefly's AI SRE is a chat interface that queries across all five views simultaneously. Instead of opening the Governance page to find subnet violations, then opening Inventory to check IaC status, and then opening Event Center to check ClickOps history, the engineer types a single prompt and gets a fully cross-referenced answer. Referring to the snapshot below:

On the prompt "Based on recent manual changes, identify the top 10 resources to codify into Terraform first", AI SRE correlates ClickOps frequency from Event Centre against unmanaged resource status from Inventory and policy violations from Governance to return a risk-ranked codification plan: sound-habitat-462410-m4 GCP project at Critical (4 IAM changes in 6 minutes = active security risk), allow-http firewall rule at Critical (unmanaged firewall allowing HTTP = attack vector), all_billing_data BigQuery dataset at High (financial data integrity risk), and vm-base-network subnets at Medium across 20+ regions (high blast radius, module opportunity). Each entry includes the specific risk, the ClickOps frequency that drove the ranking, and the reason to prioritize it over everything else in the backlog. Without the AI SRE, producing this same list requires an engineer to manually pull ClickOps logs, cross-reference against the unmanaged inventory, check each resource against policy violations, and rank by risk, a process that takes hours and still depends on the engineer knowing what to look for.
Ask "Investigate what happened in the last 3 days that caused the service interruption", and the AI SRE pulls events from Event Center, cross-references ClickOps activity against resource state from Inventory, and returns a structured investigation: 6 VCS events on byteBardShivansh/app-infra triggered by firefly-app[bot], 8 production S3 buckets with public access flagged as the critical security issue, bucket names and regions listed. Without the AI SRE, the same investigation means opening Event Center, filtering by date and action type, identifying relevant events, opening each affected resource in Inventory, checking IaC status, opening Governance for policy violations, three dashboards, manual correlation, and no guarantee the engineer has connected the right events to the right resources.
From the IDE with Firefly MCP
For engineers who prefer to stay in their IDE, Firefly's MCP server (https://mcpv2.firefly.ai/mcp) connects Claude Code, Cursor, and Claude Desktop to the same Firefly data, including Inventory, Governance, Event Center, Codification, and Audit logs, as a natural language interface. One Claude MCP add command:
Without MCP, an engineer asking "which AWS subnets are running without VPC Flow Logs?" has to open the Governance page, find the "AWS Subnet Without VPC Flow Logs Enabled" policy, click through to 54 violating assets, then cross-reference each one against Inventory to see IaC status, then manually figure out that enabling flow logs at the VPC level (17 resources) is cheaper and covers all 54 subnets at once, rather than creating 54 individual subnet-level flow logs. That's a 30–45 minute investigation before writing the first line of Terraform.
With MCP, the engineer types "fetch the AWS Subnets running without VPC Flow Logs enabled" in Claude Code:
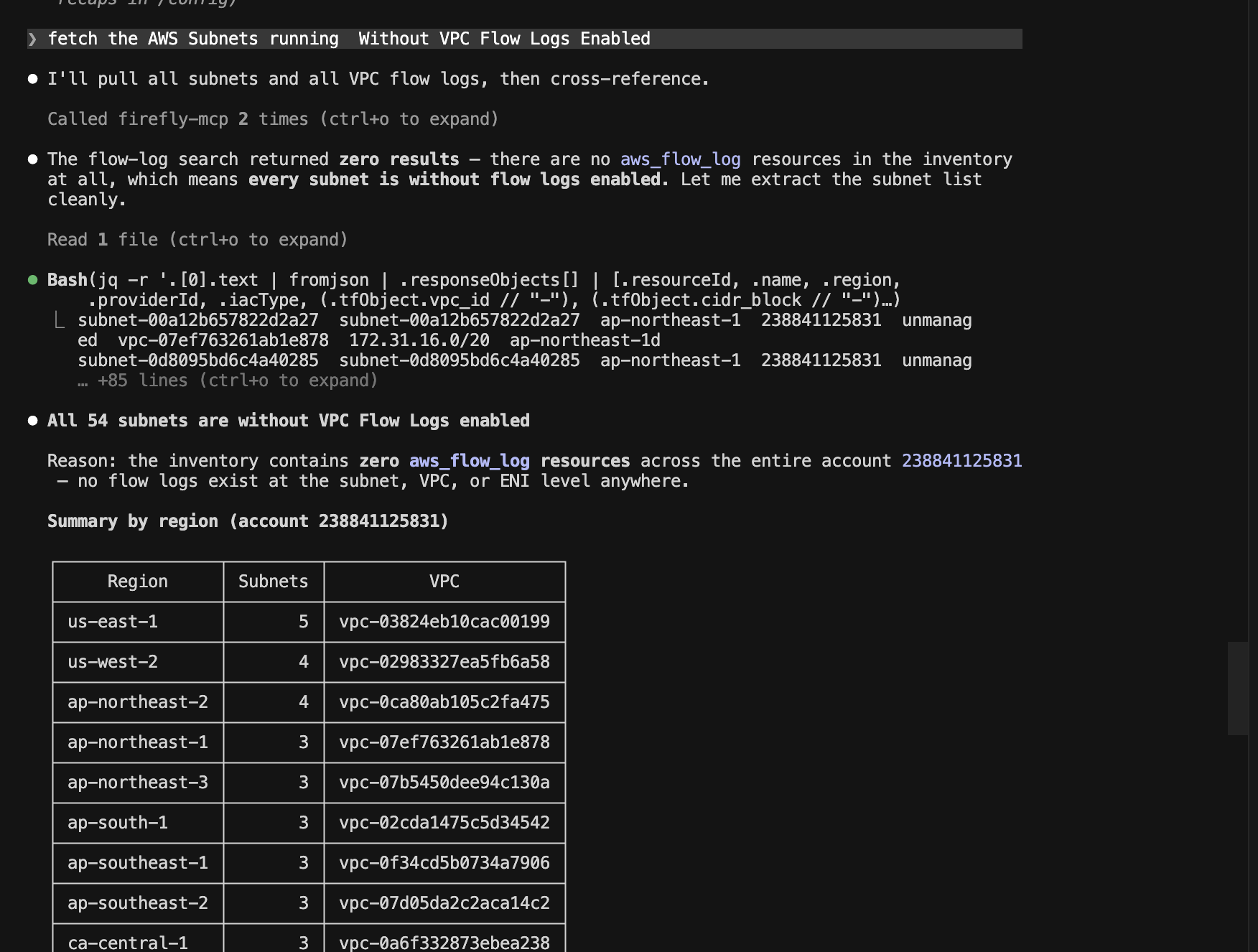
And the agent calls inventory-api___search-inventory twice, cross-references the results, and returns: all 54 subnets across 17 default VPCs in account 238841125831 have no aws_flow_log resources at any level. Region breakdown with actual VPC IDs. Recommended remediation: 17 VPC-level aws_flow_log resources instead of 54 subnet-level ones. Terraform for_each pattern generated inline, ready to adapt.
Ask "create a Terraform module for the vm-base-network subnets across all regions", and Firefly's codification-api___codify-asset generates main.tf, variables.tf, outputs.tf, provider.tf, and example.tf with the full dependency chain (google_project → google_compute_network → google_compute_subnetwork), import blocks pre-filled with actual resource IDs, and a ready-to-use module call for africa-south1 with instructions to replicate across all 20+ regions. The engineer opens a PR from the IDE. Without MCP, the same module requires manually looking up every resource ID across GCP console tabs, writing the dependency chain from scratch, writing import blocks in the correct format for each resource type, and running Terraform import per resource until the plan returns zero diff.
What do the two Agents replace
Both AI SRE and Firefly MCP eliminate the five-dashboard context switch, the manual process of opening Inventory, Event Center, Governance, Workflows, and IaC Explorer separately, correlating the results by hand, and then starting to write Terraform. The platform runs the continuous autonomous loop regardless: scanning inventory, detecting drift, evaluating plans against Guardrail rules, executing Workflows on merge, and logging every action to Event Center. The engineer queries the results in whichever surface they're already in.
Before any of that runs autonomously, the governance layer needs to be in place. Guardrail rules define which resource types the agent can modify. Blast radius limits require explicit human approval for deletions and replacements. Approval gates block apply to high-risk changes until a human approves via PR comment or Slack. Audit logs in Event Center record every action, what was run, what was changed, who approved, and what the outcome was. An AI agent with Terraform access and no guardrails can execute Terraform destroy across production resources in seconds. Firefly's 2026 report documents exactly this happening to a team that skipped this layer.
FAQs
What is an agentic cloud?
An agentic cloud is a cloud environment where AI agents continuously monitor, manage, and remediate infrastructure without waiting for a human to initiate action. The agent perceives live state, plans the corrective Terraform change, validates it against policy, applies it, and confirms the outcome, on its own, within defined guardrails.
Will AI replace Terraform?
No. Terraform, OpenTofu, Pulumi, and similar frameworks remain the execution layer. AI agents generate, validate, and apply Terraform; they don't replace it. The 2026 data puts Terraform usage at 73% with no sign of collapse. What AI changes is the manual work that happens between the IaC code and the live cloud: drift detection, dependency discovery, policy evaluation, and remediation authoring.
What does "agentic" mean in AI?
An agentic AI system is one that pursues a goal continuously rather than responding to prompts one at a time. A standard tool waits for input, produces output, and stops — the human decides what happens next. An agentic system observes its environment, determines what needs to change, takes the sequence of actions required, checks the result, and repeats, without a human initiating each step. In infrastructure terms: the agent reads live cloud state, identifies drift or policy gaps, generates the corrective Terraform, validates it, applies it, and starts the next cycle.
What are the 5 types of agents in AI?
Simple reflex agents respond to current inputs based on rules with no memory of prior state. Model-based reflex agents maintain an internal model of the environment to handle situations that current inputs alone don't cover. Goal-based agents evaluate actions against a defined goal and choose the sequence most likely to achieve it. Utility-based agents optimize toward a utility function, weighing trade-offs between outcomes. Learning agents improve decision-making over time based on feedback from prior actions. Most production agentic IaC systems today operate as goal-based or utility-based agents, pursuing a defined infrastructure state within cost and policy constraints.
.webp)


.webp)















