
TL;DR
- AWS outages usually don’t destroy data; they disrupt the infrastructure on which applications depend, including networking, IAM, load balancers, and service coordination.
- Backups and snapshots restore storage, not the full environment, so applications cannot recover until the infrastructure state is rebuilt correctly.
- All AWS disaster recovery strategies assume that infrastructure can be recreated accurately, whether during recovery from a failure or in a pre-provisioned secondary region.
- Recovery time increases when the infrastructure state is incomplete or drifted from IaC, especially after console changes or incident fixes that were never captured in code.
- Firefly reduces recovery time by making infrastructure state visible, codified, and reproducible, allowing teams to rebuild application environments through code and existing CI/CD workflows.
In a documented AWS outage, the root cause was traced to an internal system that monitors the health of network load balancers inside the EC2 internal network. Traffic stopped routing correctly, multiple services failed, and even after AWS restored service availability, systems such as AWS Config and Redshift continued to process backlogs for hours. The data itself was not lost, but the infrastructure needed to serve that data was unstable.
For customers, this creates a recovery problem that backups do not solve. Snapshots preserve storage, but they do not preserve infrastructure state. During recovery, teams still need to rebuild IAM roles, networking, service dependencies, and configuration changes that may never have been captured in code. If the running state differs from what exists in Terraform or CloudFormation, recovery becomes manual and error-prone.
Ken Birman, a computer science professor at Cornell, highlighted this after AWS outages: AWS provides the tools, but fault tolerance is the customer’s responsibility, including maintaining backups and the ability to recover outside a single failure domain. That observation points to a practical reality: recovery depends on how accurately infrastructure can be reconstructed, not just on whether data exists. This blog focuses on that infrastructure recovery gap and how it can be addressed.
What Disaster Recovery Means in the AWS Cloud
Disaster recovery in AWS is often treated as a backup problem. Teams enable snapshots, replication, and retention policies. That protects data, but it does not define how a system is recovered.
When a failure happens, restoring data is usually straightforward. The harder step is restoring everything that makes the data usable. Databases and volumes depend on VPCs, routing, security groups, IAM roles, load balancers, and service configuration. If those pieces are missing or incorrect, the system cannot come back online even if the data is intact.
Recovery slows down when the infrastructure state is incomplete. Some resources exist only in the console. Some changes were made during incidents and never written back to code. The IaC in Git represents how the system should look, not how it actually looked at the time of failure. Rebuilding infrastructure then becomes manual work under time pressure.
Disaster recovery in AWS, therefore, requires two things: restored data and the ability to accurately recreate infrastructure. Infrastructure as Code is the mechanism AWS expects teams to use for this, but it only works when the code reflects the deployed environment. Backups preserve data. Recovery depends on whether the infrastructure can be rebuilt correctly and quickly.
AWS-Native Disaster Recovery Strategies
AWS groups disaster recovery strategies by how much infrastructure is available in a secondary Region before a failure occurs. Each option is designed to balance cost, complexity, recovery time, and operational effort. The main difference between strategies lies in when infrastructure is created: before or after a failure.
Backup and Restore
Backup and restore is the simplest disaster recovery approach.
Data is protected using services like EBS snapshots, RDS automated backups, DynamoDB point-in-time recovery, S3 versioning, or AWS Backup. Copies are usually stored in another Region. During recovery, data is restored first, and infrastructure is created afterward.
Typical recovery flow:
- Restore databases, volumes, or objects from backups
- Create networking, IAM, and compute resources
- Deploy application services and connect them to restored data
This approach has the lowest ongoing cost and works well when longer recovery times are acceptable. Recovery speed depends on how quickly infrastructure can be recreated and how complete the deployment automation is.
Pilot Light
Pilot light keeps a minimal version of the environment running in a secondary Region.
Usually this includes:
- Core data stores or replication targets
- Basic networking and IAM configuration
- Enough setup to support a controlled scale-up
Most application components are not running, but their configurations are ready to be deployed. During a failure, additional infrastructure is brought online to reach full capacity.
This reduces recovery time compared to backup and restore. It relies on consistent configuration and automation between Regions so that scaling up behaves predictably.
Warm Standby
Warm standby runs a full copy of the production environment in another Region, but at reduced capacity. Key characteristics:
- All services are deployed and running
- Capacity is intentionally lower than production
- Scaling and traffic shifting are part of the recovery process
Because the environment is already active, recovery is faster and easier to test. The trade-off is a higher cost, since resources are running continuously.
Multi-Site Active/Active
Multi-site active/active runs production workloads across multiple regions simultaneously.
Traffic is distributed across Regions using services like Route 53 or AWS Global Accelerator. Data is replicated continuously to keep Regions in sync.
This approach minimizes downtime during regional failures but introduces additional operational considerations, such as data consistency and coordinated deployments. Even with active/active setups, infrastructure still needs to be rebuilt when a Region is fully lost and brought back.
Common Assumptions Across All Strategies
All AWS disaster recovery strategies assume:
- Infrastructure can be created using automation and code
- Dependencies between services are understood
- Recovery workflows are tested ahead of time
The strategy determines how much infrastructure is already available when a failure occurs, not whether infrastructure recovery is needed. That shared assumption becomes important when looking at real outage scenarios.
Lessons from AWS Outages That Required Disaster Recovery
In AWS outages, data is often available early, but applications only recover after networking, IAM, and service dependencies are rebuilt. As shown in the snapshot below, failures typically propagate from identity and routing layers downward, while applications fail last and recover only after upstream dependencies stabilize:
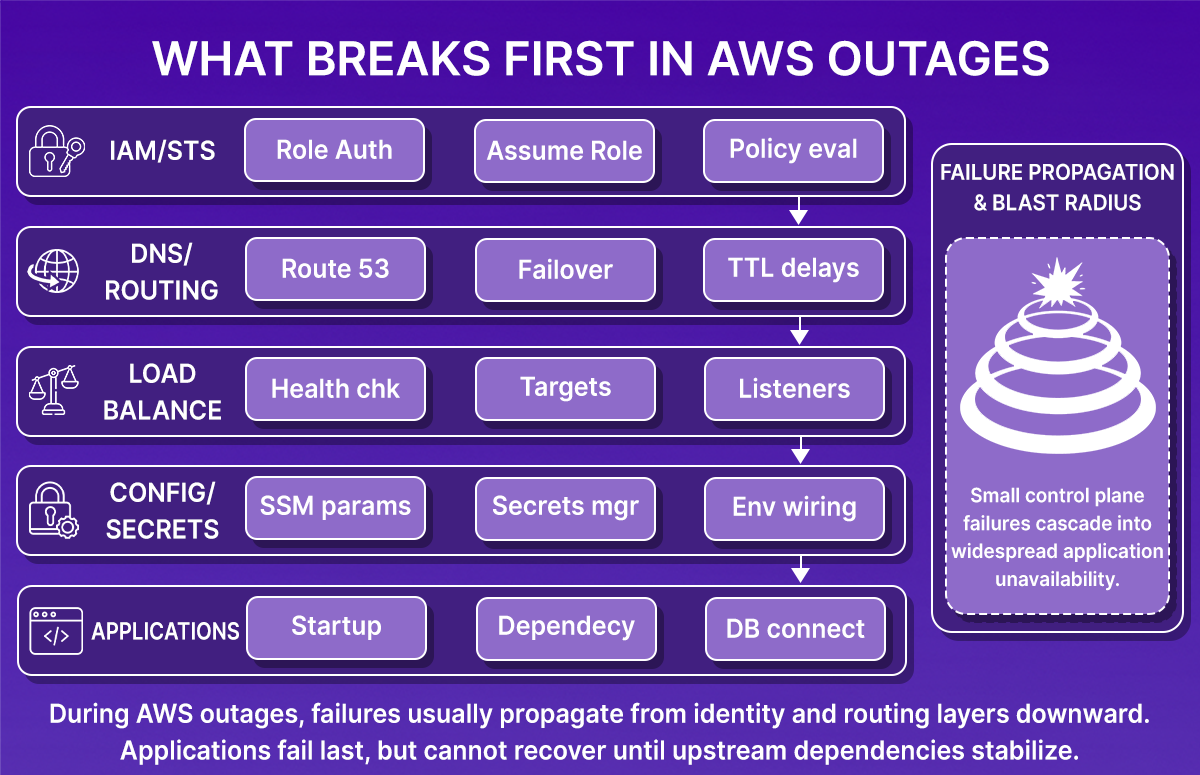
Across these incidents, a few recurring issues explain why recovery takes longer than expected:
Control-plane failures block recovery actions
Several AWS outages were caused by issues in systems that manage infrastructure rather than customer workloads directly. These systems control load balancer health, routing updates, scaling actions, and service configuration.
When these systems are slow or unavailable:
- Traffic does not route correctly
- Scaling changes fail to apply
- New resources take longer to become usable
Even when compute and storage are healthy, applications cannot recover until these control systems are stable again.
Data can be restored before applications can run
In many outages, snapshots and backups remain usable. Databases can be restored and volumes can be recreated.
What blocks application recovery is usually a missing or incomplete infrastructure:
- IAM roles or policies are not applied
- Security groups or routing rules block traffic
- Load balancers are unhealthy or misconfigured
- Services cannot connect to dependencies
Until these pieces are rebuilt, restored data cannot be used by the application.
Service dependencies fail together
Applications rely on multiple AWS services at the same time, including IAM, networking, DNS, configuration, and compute.
During outages, these services do not fail in isolation. A delay in one dependency can prevent others from starting, even when individual services appear healthy. Recovery often stalls because services are waiting on each other.
Region-level failures reduce recovery options
When an entire region or a core AWS service is affected, all workloads in that region are impacted at once. High availability inside a region helps with localized failures, but it does not help when the region itself is unstable.
In these cases, recovery depends on whether workloads can be rebuilt in another environment instead of waiting for the original region to fully recover.
Untested recovery paths slow response
Outages also expose whether recovery paths were tested in advance.
Recovery is slower when:
- Teams do not know which services must start first
- Infrastructure creation relies on manual console steps
- Dependencies are unclear or undocumented
- Recent changes were never captured in code
Teams that have tested recovery paths move faster because they can execute known steps instead of figuring things out during the outage.
What AWS Disaster Recovery Requires Beyond Backups
AWS provides strong DR building blocks: snapshots, replication, multi-AZ services, and region failover patterns. To get predictable recovery times, teams should plan how those primitives fit into their operational model. Below are the key areas to watch and the practical steps to address them.
Resource-level protection vs. infrastructure intent
AWS protects individual resources (snapshots, AMIs, S3 objects). That’s reliable and expected.
What to plan for:
- Capture how resources are connected (network topology, IAM bindings, load balancer wiring).
- Keep those relationships codified so you can recreate them with confidence.
Actionable step: store topology and dependency information alongside your IaC (modules, variables, and documented run orders).
Keep IaC as the source of truth, and verify it
IaC is the right mechanism to recreate environments, but it must match the running environment.
Common operational realities:
- Console changes, automated resource creation, or emergency patches can cause drift.
- Drift doesn’t mean IaC is irrelevant; it means you must detect and reconcile it.
Actionable step: run regular drift detection and require that any console or emergency change be captured back into code and the CI/CD pipeline.
Recreating deleted or modified resources reliably
Backups let you restore storage and data. Recreating the exact infrastructure configuration requires recorded intent.
What helps:
- Versioned IaC templates (with module versions and pinned provider/plugin versions)
- Exported metadata (tags, ARNs, parameter names) that tie backups to their infra definitions
Actionable step: include metadata capture in your backup process so restores can reference the right IaC inputs.
Rollbacks and known-good states
AWS does not automatically produce a “previous infrastructure snapshot” for you; teams need a reproducible rollback plan.
What helps:
- Store historical IaC revisions in Git (with clear tagging for production releases)
- Keep Terraform state or CloudFormation templates in a retrievable form that maps to releases
Actionable step: define and test rollback playbooks that use specific Git commits and state snapshots to restore a known-good environment.
Visibility into changes and who did what
Effective recovery relies on quick answers to “what changed” and “who changed it.”
What helps:
- Centralized event logs (CloudTrail, CI/CD logs) correlated with deployment records
- A single audit view that links code commits, PRs, and applied changes
Actionable step: standardize tagging and deployment metadata so audit trails tie back to code and runbooks.
How to combine AWS features with operational practices
AWS’s DR primitives work best when combined with disciplined processes and a few complementary capabilities:
- Treat DR as code: include recovery steps in the same repo as your deployments.
- Test recovery regularly: run failover drills and validate the entire sequence (network, IAM, services, data).
- Automate verification: use smoke tests and health checks that run after a restore.
- Capture runtime metadata: include ARNs, tags, parameter names, and secrets pointers in backups.
- Use tooling to bridge gaps: tools that codify running resources, detect drift, and generate recovery IaC make the process repeatable.
AWS provides durable, scalable building blocks for disaster recovery. To meet tight RTOs, you must also ensure those building blocks are organized into reproducible, testable recovery workflows. That combination, AWS primitives, code, testing, and automation, is what produces predictable recoveries.
Rethinking Disaster Recovery as Infrastructure Recovery
Disaster recovery is not just about getting backups. It’s about putting the system back so those backups can be used.
You must be able to:
- Recreate the network and routing the app needs.
- Restore IAM roles, policies, and service permissions.
- Recreate load balancers, listeners, and health checks.
- Re-deploy services in the correct order.
- Reconnect services to secrets, parameters, and DNS records.
If any of those are missing or wrong, restored databases and disks won’t serve traffic.
Three practical requirements make recovery predictable:
- Capture the exact infrastructure state (not just resource names).
- Version that states so you can target a known-good point.
- Automate rebuilds so the same steps run reliably under pressure.
These are the things you need before you run a restore. The next section shows how Firefly helps capture, version, and automate those rebuild steps alongside AWS.
Rebuilding an AWS Environment After Using Firefly
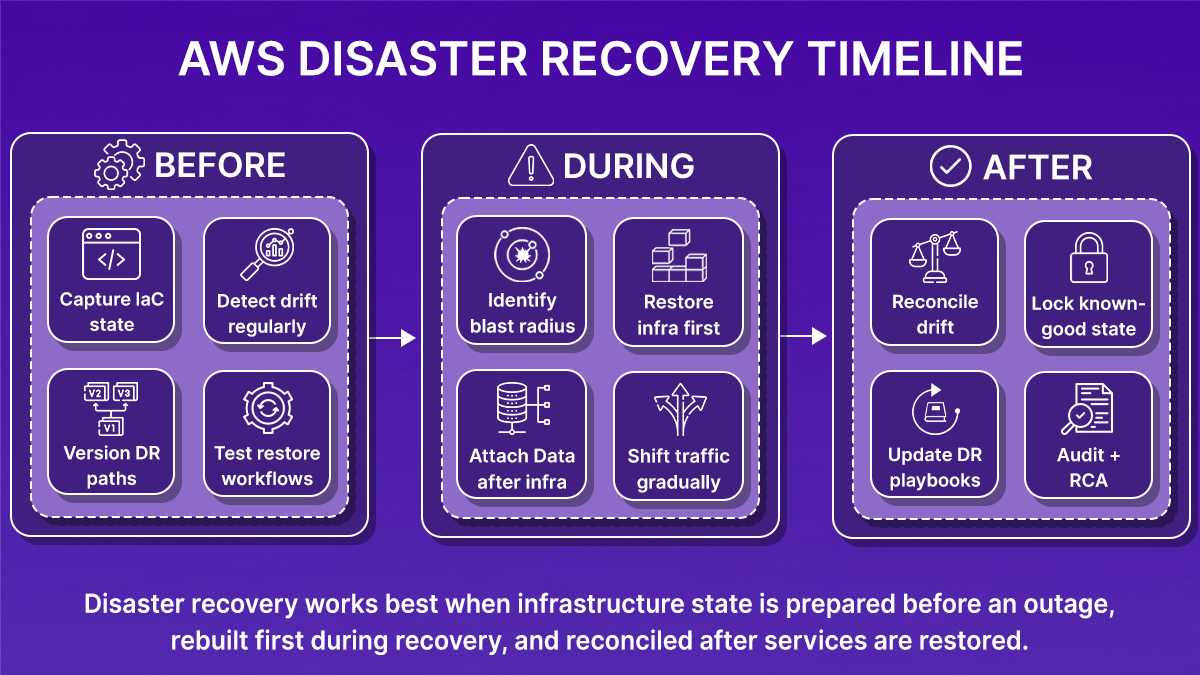
After an outage, the first problem is not backups. It’s understanding what actually existed before things broke.
Most teams start by answering basic questions:
- Which resources were part of this application?
- Which of them were created via Terraform and which weren’t?
- What changed recently?
- What do we need to rebuild first to get traffic flowing?
This is where recovery usually slows down. Firefly fits into this phase by turning a running AWS account into something you can reason about and rebuild.
Seeing the full environment before making changes
Before any restore or redeploy, you need a reliable view of what exists across accounts and regions. Not just EC2 or RDS, but the full set of infrastructure tied to an application.
As shown in the snapshot below:
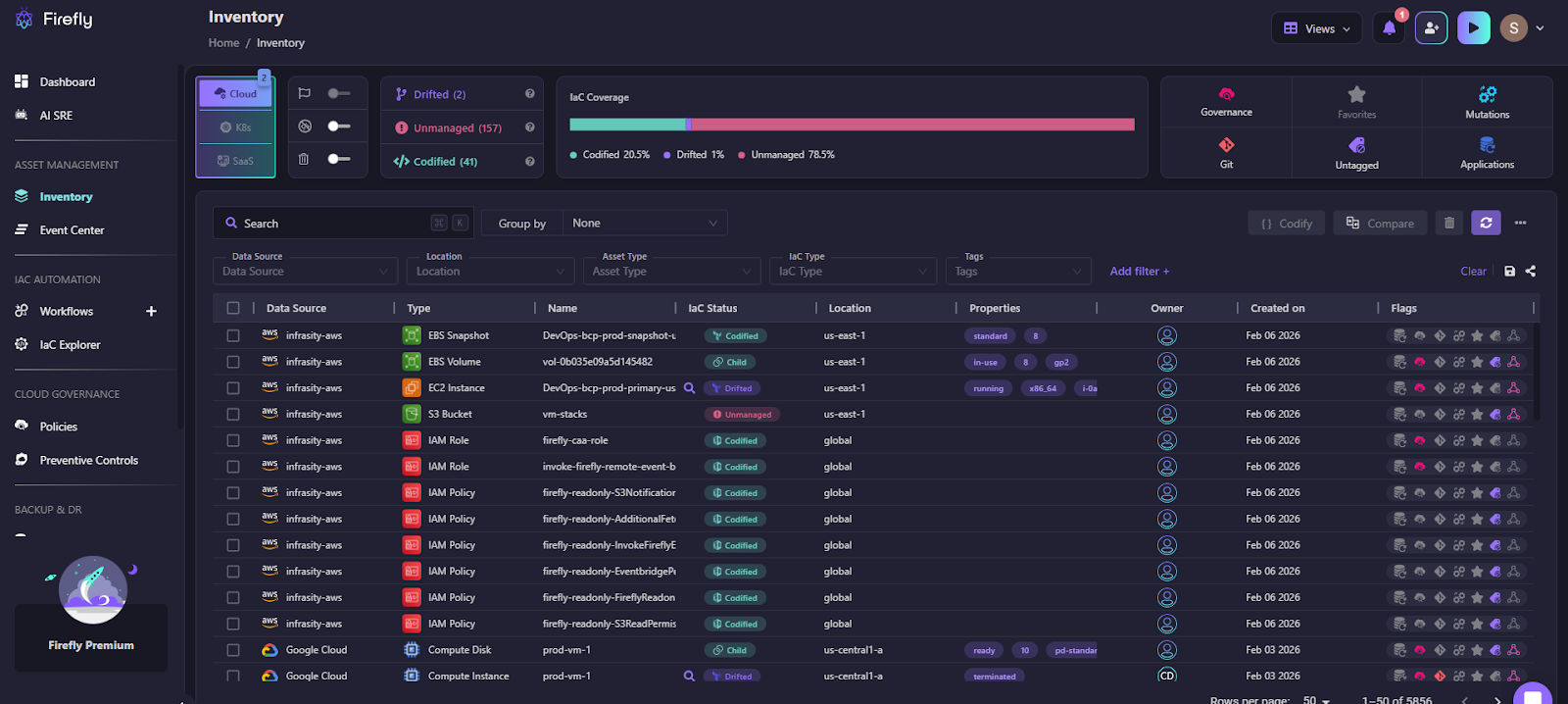
Firefly provides a consolidated inventory view that shows:
- All discovered resources
- Which ones are covered by IaC and which are not
- When the environment was last scanned in the IaC explorer, as shown below:
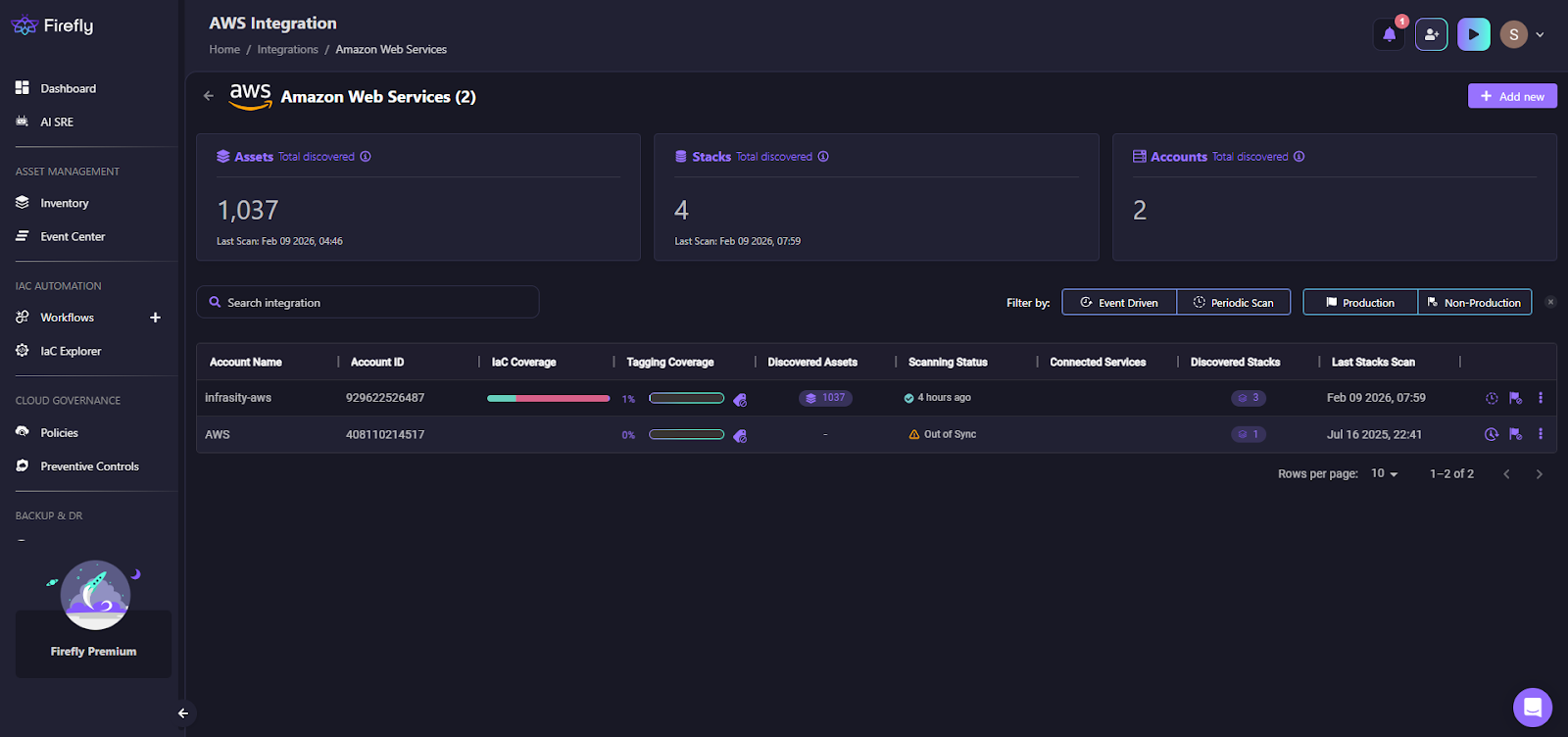
This gives teams a starting point before they touch backups or run Terraform.
Turning running resources into something rebuildable
In many environments, parts of the infrastructure were never written in code. Some were created in the console. Others were added during incidents.
During recovery, that missing code becomes a problem.
Firefly helps by generating Infrastructure as Code from what is currently running. The goal is not to refactor or optimize. It’s to capture the current state so it can be recreated elsewhere if needed.
At this stage, teams are focused on:
- Capturing exact configuration values
- Preserving dependencies
- Making the environment reproducible
For example, here’s how Firefly codifies the unmanaged resources flagged as done in the snapshot below:
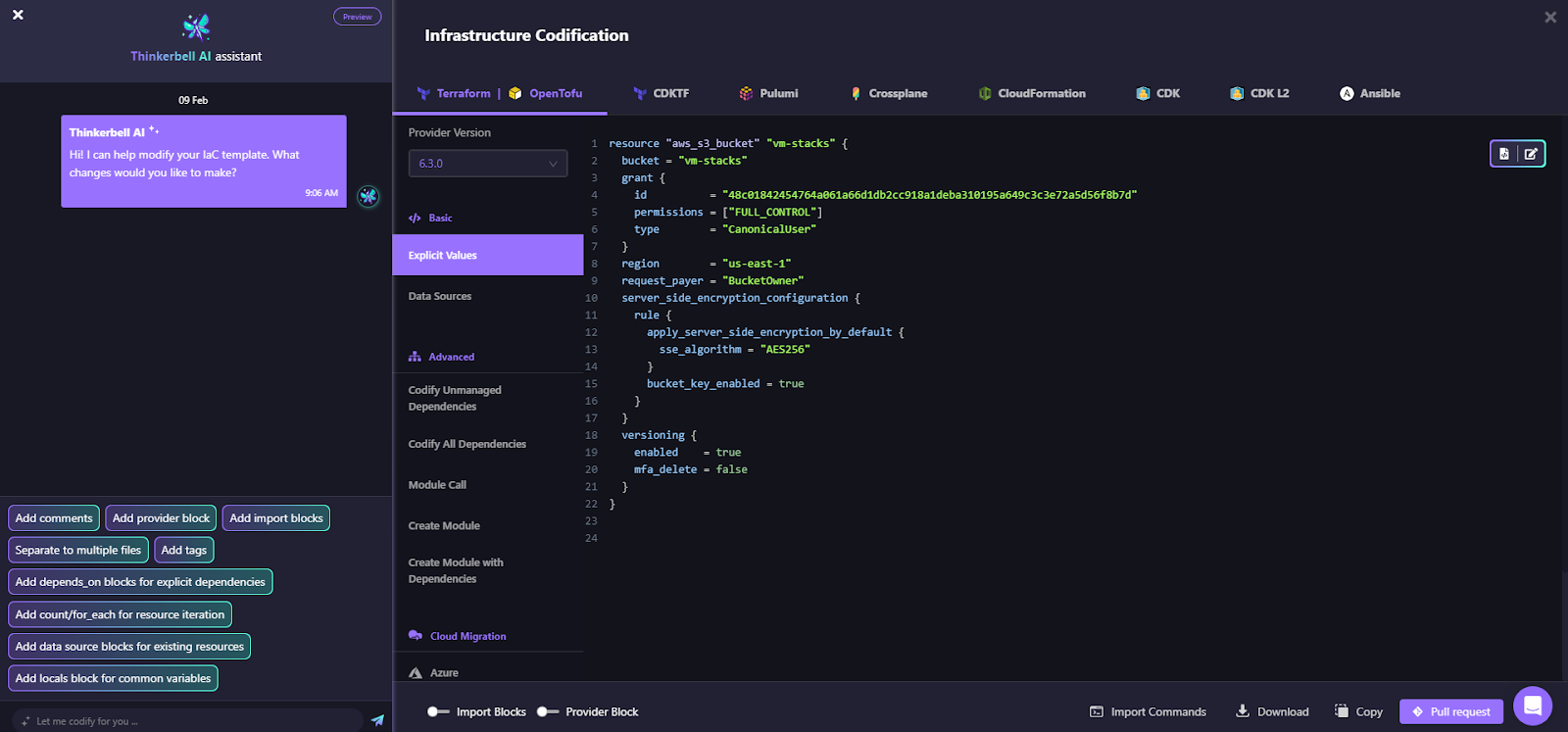
Here, an unmanaged S3 bucket named vm-stacks is defined, and the code can be versioned simply by raising a PR after it is defined.
Restoring an application, not individual resources
AWS backups work at the resource level. But when teams restore, they need everything an application depends on, compute, networking, security rules, and data, all together.
To make sure nothing is missed, Firefly scans the relationships between resources rather than relying on tags alone. This way, if a security group, subnet, or IAM role is required for the application to run but was never tagged as part of it, Firefly still catches it and includes it in the restore.
The goal is simple: when a restore is triggered, the application comes back up fully functional, not partially, because a dependency was overlooked
Catching drift before it breaks recovery
Recovery plans assume the infrastructure code matches what was running. Drift breaks that assumption.
During recovery, drift usually shows up as:
- Terraform applies failing
- Security rules not matching expectations
- Resources are coming up, but not behaving correctly
Firefly highlights configuration differences between code and runtime state and shows exactly what changed. This lets teams fix drift before they attempt a rebuild.
Using the same workflow for recovery as for deployment
Manual recovery steps don’t scale under pressure.
Firefly integrates recovery into the same Git and CI/CD workflows teams already use:
- Infrastructure changes are generated as code
- Changes go through pull requests
- Restores are applied through pipelines
This keeps recovery repeatable, reviewable, and auditable, without inventing a new process during an incident.
Takeaway:
During AWS outages, teams don’t fail because backups are missing. They lose time because the infrastructure state is unclear, drifted, or scattered across tools.
Firefly fits into disaster recovery by reducing uncertainty:
- What existed
- What changed
- What needs to be rebuilt
- How to do it safely using code
It doesn’t replace AWS recovery services. It makes them usable under high pressure.
FAQs
What’s the difference between DRP and BCP?
A Disaster Recovery Plan (DRP) focuses on restoring IT systems, infrastructure, and data after a failure. A Business Continuity Plan (BCP) focuses on keeping the business operating during disruption, including people, processes, and communication. DRP is a part of BCP, not a replacement for it.
Which AWS backup tool is best for disaster recovery?
There is no single best AWS backup tool for disaster recovery. Teams typically combine AWS Backup, EBS snapshots, RDS backups, and S3 replication based on the workload. These tools protect data, but disaster recovery also requires rebuilding infrastructure and dependencies.
Which AWS service is used for disaster recovery?
AWS does not provide a dedicated disaster recovery service. Disaster recovery is built using multiple services like AWS Backup, Route 53, multi-AZ/multi-region setups, and IaC tools. The recovery strategy depends on how these services are designed and automated together.
Is Azure better than AWS for disaster recovery?
Neither AWS nor Azure is inherently better for disaster recovery. Both offer similar backup, replication, and multi-region capabilities. Recovery success depends more on architecture, automation, and testing than on the cloud provider itself.

.avif)
.avif)


.webp)


.webp)















