TL;DR
- Backups + IaC don't coordinate recovery. You can have RDS automated backups and Terraform modules, but still fail recovery because networking comes up after services start, DNS points to the failed region, or IAM roles aren't created before containers try to assume them. DR platforms orchestrate the sequence.
- IaC reflects declared state, not runtime reality. Your Terraform repo might not include the IAM inline policy added during last week's S3 access fix, or the RDS parameter increased under load. DR platforms continuously capture the state of working infrastructure, including console changes and operational fixes.
- Cloud provider services restore resources, not systems. AWS Backup restores an RDS snapshot. It doesn't rewire VPCs, security groups, load balancer target groups, or Route53 records. DR platforms restore the dependency graph, the relationships between resources that make applications work.
- Recovery readiness is invisible until tested. 2026 Forrester/DRJ survey: only 37% felt prepared for site failures, 32% had readiness dashboards, 59% update DR plans once yearly. DR platforms are validated continuously.
You can have perfect snapshots and still end up with a production environment that cannot serve traffic.
Look at this sysadmin thread:
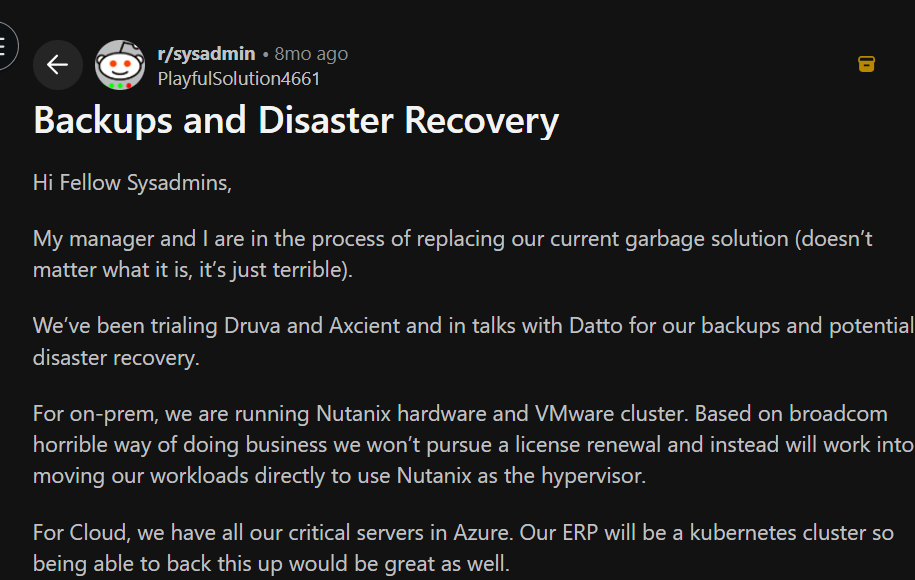
The Sysadmin's checklist covers: automated restore testing, integrity checks, native Nutanix VM backup and restore, the ability to restore into Azure and fall back to on-prem, DRaaS options, no hardware appliances, and lower cost. They trialed several vendors, and each one was missing something important.
This is where many disaster recovery strategies break down. Backups, replication, and Infrastructure as Code are necessary, but they don't automatically restore a working application environment. Networks, IAM policies, load balancers, secrets, and service dependencies all have to be restored and configured correctly. If DNS still points to the failed region, or application services start before their database endpoints or secrets are available, the infrastructure may be restored, but the application still won't handle requests.
A cloud disaster recovery platform acts as the control plane that coordinates these pieces: infrastructure state capture, dependency-aware orchestration, traffic failover, and recovery validation. It captures the actual infrastructure state, sequences recovery steps, validates the environment, and automates failover, so you restore systems, not just resources.
What Is a Cloud Disaster Recovery Platform?
A cloud disaster recovery platform is software that coordinates how an entire cloud environment is restored after a failure. Instead of focusing on backing up individual resources, it manages the process of rebuilding and bringing a system back to a usable state.
Examples of cloud disaster recovery platforms include Zerto, Veeam Cloud, Cohesity, Rubrik, Azure Site Recovery, AWS Elastic Disaster Recovery, and Firefly's CAIRS (Cloud Application Infrastructure Recovery Solution). Each platform handles different aspects of the recovery workflow; some focus on VM replication, others on Kubernetes workloads, and some on infrastructure-as-code-based recovery.
In most of the architectures, an application is not a single server. A typical e-commerce platform includes ECS containers behind an Application Load Balancer, RDS databases for transactions, DynamoDB for product catalog, S3 for images, SQS queues for order processing, IAM roles for service authentication, and VPCs with public/private subnets. A SaaS analytics platform might use Kinesis streams for data ingestion, EMR clusters for Spark jobs, S3 data lakes, Redshift for queries, and EKS for the application layer.
Each of these components has dependencies. If they are restored in the wrong order or with incorrect configuration, the system will not operate correctly, even if the data is intact.
A disaster recovery platform handles that coordination through four main functions:
1. Infrastructure State Capture
A DR platform continuously records the state of infrastructure resources across cloud accounts and regions. This includes compute instances, networking configuration, identity policies, storage volumes, and other services that make up the runtime environment.
The goal is to maintain a deployable representation of the environment so it can be recreated during a recovery event. This state capture complements Infrastructure as Code repositories by reflecting the actual running infrastructure, including console changes and manual fixes, rather than only what is defined in source control.
2. Recovery Orchestration
Restoring infrastructure is rarely a single operation. Systems must be brought back online in the correct sequence:
- Networking and security groups must exist before compute resources attach to them
- Databases must be reachable before application services attempt connections
- Load balancers and DNS must be updated only after backend services are healthy
A disaster recovery platform automates these steps so the recovery process follows a predictable execution order.
3. Failover and Traffic Control
Traffic routing is critical. Even if a system is successfully restored in another region or account, users will not reach it until traffic is redirected.
DR platforms coordinate updates to DNS records, load balancer configurations, and routing policies so traffic can be shifted to the recovery environment once it is ready.
4. Recovery Readiness Validation
A major problem with many DR strategies is that they are rarely tested. Backups may exist, but teams do not always know if recovery will meet the required recovery time objective (RTO) or recovery point objective (RPO).
A disaster recovery platform continuously checks whether the environment can meet those targets. This includes verifying replication status, identifying resources that are not protected by backups, and running periodic recovery simulations.
What's the Gap Between Cloud Provider Services and complete cloud DR?
Cloud providers like AWS, Azure, and Google Cloud offer strong services for data replication, backups, and resource restoration. AWS has Elastic Disaster Recovery and AWS Backup. Azure has Site Recovery. Google Cloud has a backup and DR service.
The gap: Native cloud DR services restore individual resources. Application recovery requires coordinating those resources together.
What native cloud DR services handle:
- AWS Elastic Disaster Recovery replicates EC2 instances and EBS volumes to a staging area
- AWS Backup takes point-in-time snapshots of RDS, DynamoDB, EFS, and other AWS resources
- Azure Site Recovery orchestrates VM failover between Azure regions or from on-premises to Azure
- Google Cloud Backup and DR protect VMs, databases, and applications with backup policies
What requires additional coordination:
- Dependency sequencing: Ensuring VPCs, security groups, and IAM roles exist before services start
- Cross-resource relationships: Rebuilding security group rules, IAM instance profiles, and load balancer target group registrations
- Application-level validation: Verifying health checks pass and API dependencies are available before routing traffic
- Cross-account or multi-cloud recovery: Recreating networking, IAM policies, and dependencies in different accounts or cloud providers
Example scenario: An RDS snapshot is restored in us-west-2 during a region outage. The database exists, but ECS tasks point to the old us-east-1 endpoint, security groups don't allow traffic from new subnet ranges, IAM roles lack cross-region permissions, and Route53 still points to us-east-1. Each resource can be restored independently, but application recovery requires coordinating how they connect.
Why IaC Alone Doesn't Solve Disaster Recovery
Given these gaps in native cloud services, many teams turn to Infrastructure as Code as their disaster recovery solution. If cloud providers can't coordinate infrastructure rebuild, couldn't we just use Terraform or Pulumi to redeploy everything?
Most teams managing cloud infrastructure today rely on Infrastructure as Code. Tools like Terraform, Pulumi, and Crossplane allow infrastructure to be defined in code and deployed through automated pipelines.
From a disaster recovery perspective, IaC solves an important problem: it makes infrastructure reproducible.
A typical DR workflow with IaC might involve deploying the same VPC structure, subnets, security groups, and compute resources in a secondary region. If the primary region fails, those same configurations can be applied to bring up the infrastructure elsewhere.
IaC Provisions Infrastructure, But Doesn't Capture Runtime State or Orchestrate Recovery
However, Infrastructure as Code primarily focuses on provisioning infrastructure, not on coordinating recovery events.
When an incident occurs, teams still need to handle operational steps such as:
- Restoring database snapshots or promoting replicas
- Ensuring services come online in the correct order
- Updating DNS records and load balancer targets
- Validating that dependencies like secrets and IAM roles are available
- Reconciling differences between the IaC configuration and the actual production environment
Example scenario: Your Terraform repo defines an ECS cluster with IAM roles. During production, someone added an inline IAM policy via console to fix S3 access. Later, RDS max_connections was increased manually under load. Your IaC doesn't capture these runtime changes. When you run terraform apply for recovery, it reverts to the declared state, and production breaks.
IaC provides the blueprint for rebuilding infrastructure, but disaster recovery involves sequencing multiple systems and services during an outage. For that reason, IaC often becomes one component within a broader disaster recovery strategy rather than the complete solution by itself.
How Is a DR Platform Architecture Different?
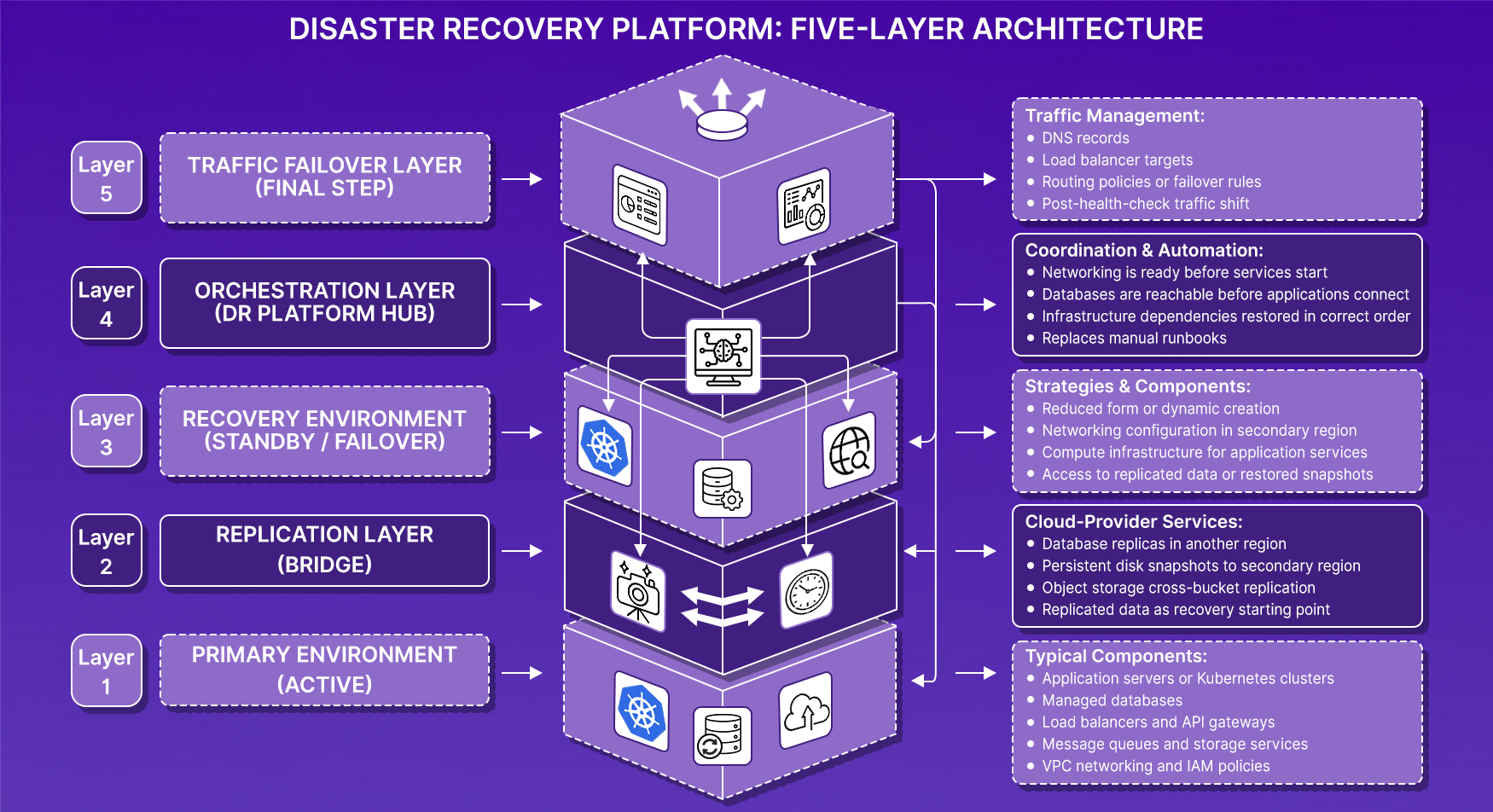
In most cloud environments, disaster recovery is built as a layered architecture. Each layer handles a different part of the recovery process.
Layer 1: Primary Environment
Where production workloads normally run. This may be a single cloud region or multiple regions. Typical components:
- Application servers or Kubernetes clusters
- Managed databases
- Load balancers and API gateways
- Message queues and storage services
- VPC networking and IAM policies
All user traffic is routed to this environment during normal operation.
Layer 2: Replication Layer
Protects the underlying data and infrastructure state. Cloud providers handle this through services such as database replication, storage snapshots, and cross-region backups. For example:
- Database replicas are maintained in another region
- Persistent disk snapshots copied to secondary regions
- Object storage replicating across buckets
If the primary region becomes unavailable, this replicated data becomes the starting point for recovery.
Layer 3: Recovery Environment
The infrastructure that will run the workload if the primary environment fails. Depending on the recovery strategy, this environment may already exist in a reduced form (pilot light or warm standby), or it may be created dynamically during recovery.
Typical components:
- Networking configuration in the secondary region
- Compute infrastructure for application services
- Access to replicated databases or restored snapshots
The goal is to recreate the same runtime environment in a different location.
Layer 4: Orchestration Layer (Where DR Platforms Fit)
The orchestration layer coordinates the recovery process. Instead of manually executing steps like restoring databases, deploying infrastructure, and updating traffic routing, a disaster recovery platform automates these actions in a controlled sequence.
This layer ensures:
- Networking is ready before services start
- Databases are reachable before application instances connect
- Infrastructure dependencies are restored in the correct order
Without orchestration, these steps often rely on manual runbooks during incidents.
Layer 5: Traffic Failover Layer
Even if the recovery environment is operational, users will not reach it until traffic is redirected. The traffic failover layer manages:
- DNS records
- Load balancer targets
- Routing policies or failover rules
Once the recovery environment passes health checks, traffic can be shifted from the primary region to the recovery region.
Where Disaster Recovery Platforms Fit
Disaster recovery platforms operate primarily at the orchestration and coordination layer. They connect the underlying replication services, infrastructure deployment tools, and traffic routing systems into a single recovery workflow.
This coordination is what allows entire application environments to be restored consistently rather than relying on manual intervention during an outage.
How Does Firefly's Cloud Automation Platform Enable Infrastructure Recovery?
Native cloud services handle the replication and backup layer of disaster recovery. They ensure copies of data exist and that resources such as disks, databases, or VMs can be restored.
What they typically do not manage is the full process of restoring a working application environment. That process involves rebuilding infrastructure, restoring services in the correct order, validating the environment, and then shifting traffic.
The gaps that remain:
- Declared vs. runtime state: Your Terraform repo shows what's in Git, but doesn't capture the IAM inline policy added during last week's incident or the RDS parameter tuned under load. Recovery needs the actual working configuration, not just what's version-controlled.
- Dependency orchestration: Native tools restore individual resources (an RDS snapshot, an EC2 instance), but don't sequence them. If your ECS service starts before the database is reachable, or IAM roles don't exist before containers try to assume them, recovery fails even though resources exist.
- Recovery readiness validation: Most teams discover their cross-region certificates weren't provisioned, or replication lag is too high to meet RPO, during an outage, not before.
- Cross-account and multi-cloud coordination: Restoring workloads into a different account or region requires recreating networking, IAM, and dependencies in the target environment. Native tools don't coordinate this rebuild across boundaries.
Firefly is an agentic cloud automation platform that automates cloud resilience with Infrastructure-as-Code. For disaster recovery, Firefly addresses these gaps through two key solutions:
- Cloud Application Infrastructure Recovery Solution (CAIRS) - Rebuilds complete applications and infrastructure within minutes by deploying Infrastructure-as-Code across regions and accounts.
- Cloud Resilience Posture Management (CRPM) - Continuously validates recovery readiness, exposing which resources are protected, where dependencies exist, and whether RTO/RPO targets are achievable.
Together, these capabilities operate at the orchestration layer, connecting replication services, infrastructure deployment, and traffic routing into a single recovery workflow.
Capturing Infrastructure State with Application Snapshots
In most IaC-managed environments, the declared state in Git doesn't always match production reality. Teams apply emergency fixes through the console, adjust database parameters under load, or add inline IAM policies during incidents. Over time, these operational changes drift from what's version-controlled.
Firefly continuously captures infrastructure state across cloud accounts and regions, storing it as deployment-ready Terraform modules. Instead of relying solely on what's committed to Git, Firefly records what's actually running in production.
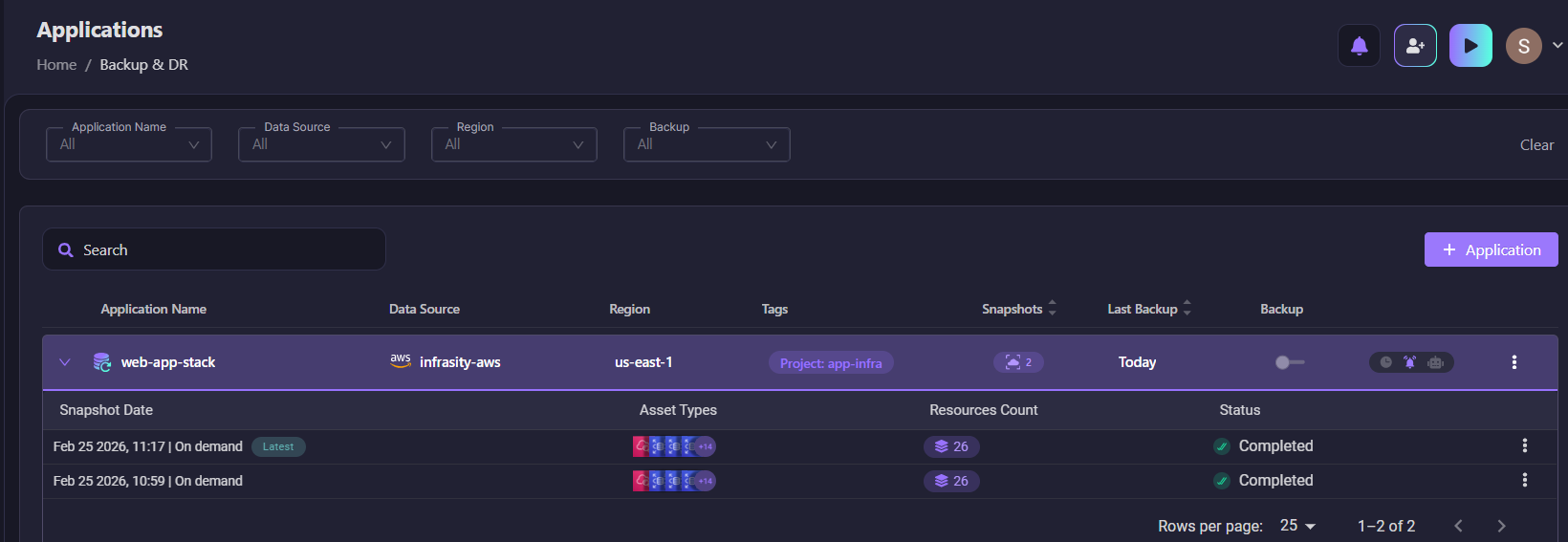
The Applications dashboard shows all protected applications with their backup status. The web-app-stack application is configured with data source infrasity-aws, region us-east-1, and tagged with Project: app-infra. It has 2 snapshots captured with the last backup completed today.
When you define an application using tags (like Project: app-infra), Firefly doesn't just snapshot the tagged resources. It scans the relationships between those resources to detect everything required for the application to function, even if those dependencies aren't explicitly tagged.
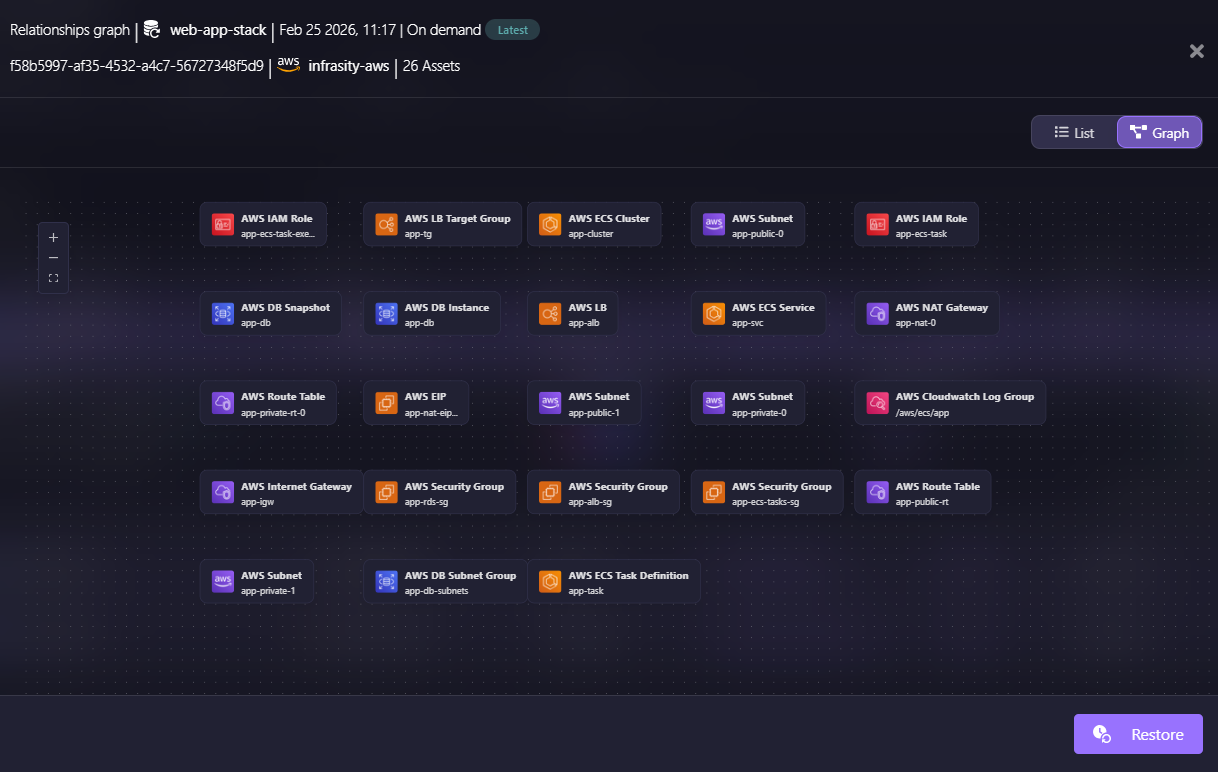
This relationship graph visualizes the 26 assets captured in the snapshot. The graph includes the ECS cluster, load balancer, database instance, NAT gateway, security groups, subnets, IAM roles, and CloudWatch log groups, all automatically detected through relationship scanning.
For example, if your ECS service is tagged as part of the application, Firefly automatically includes the VPC it runs in, the security groups it references, the IAM roles it assumes, the load balancer target groups attached to it, the NAT gateways required for outbound connectivity, and the CloudWatch log groups collecting its logs.
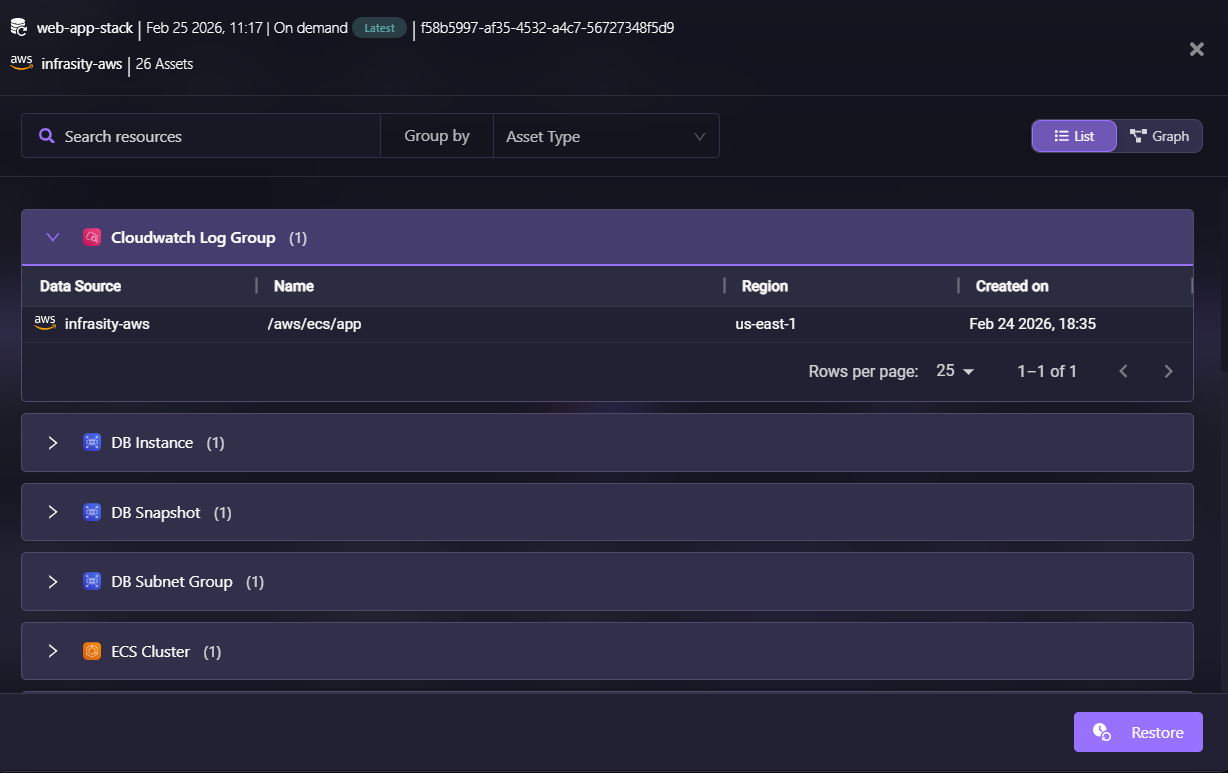
The snapshot detail view groups resources by type: CloudWatch Log Group, DB Instance, DB Snapshot, DB Subnet Group, ECS components, networking resources, and IAM roles. This makes it easy to verify that all necessary infrastructure components are captured.
The applications list shows asset types included in each snapshot when hovering over the icons, providing quick visibility into backup scope without drilling into details.
Orchestrating Recovery with Generated Terraform
During an outage, recovery isn't just about restoring individual resources. It's about rebuilding infrastructure in the correct order so dependencies are satisfied before services start.
As shown in the snapshot below, Firefly generates Terraform modules from captured snapshots. These modules define the full infrastructure graph, networking, IAM, compute, databases, and load balancers, with dependency relationships preserved.
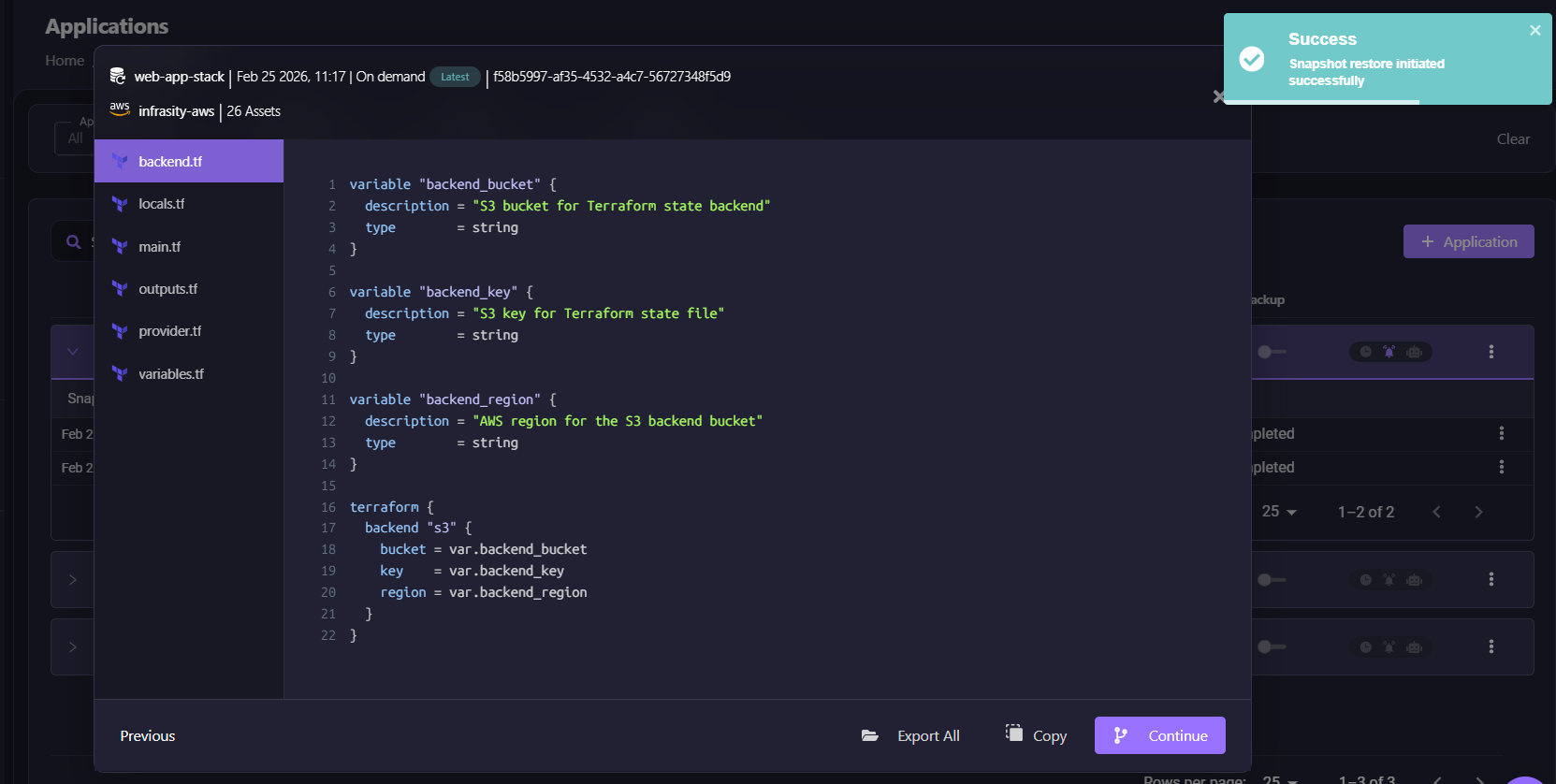
When initiating a restore, Firefly generates deployment-ready Terraform code from the captured snapshot. The interface shows the generated files: backend.tf, locals.tf, main.tf, outputs.tf, provider.tf, and variables.tf. The code includes complete infrastructure definitions with S3 backend configuration, variable references, and resource declarations. Teams can export all files, copy the code, or continue with the automated restoration workflow.
The generated Terraform ensures recovery happens in sequence: networking and IAM configuration are restored first, then infrastructure resources like clusters are brought online, databases and storage are connected, application services are started with health checks, and finally, traffic routing is updated once the environment is ready.
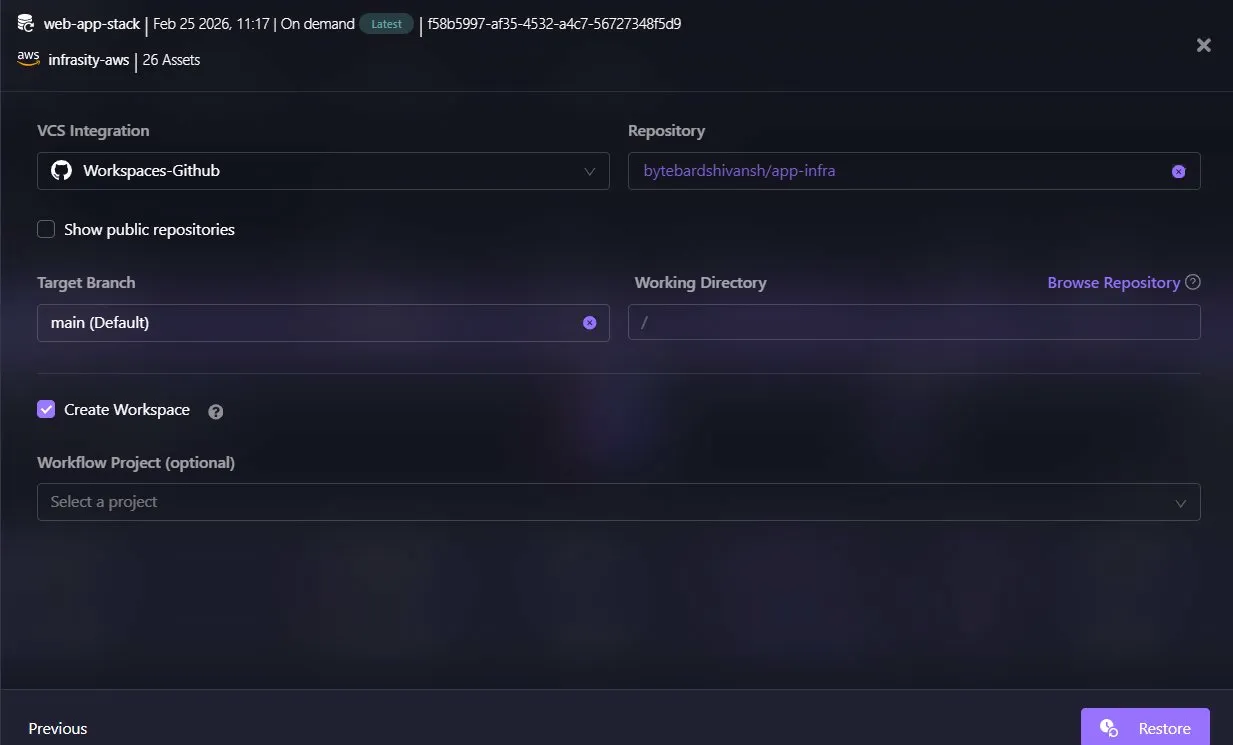
Firefly integrates with version control systems to support GitOps workflows. The restore configuration connects to GitHub (Workspaces-Github), targets the repository (bytebardshivansh/app-infra), and can create pull requests to the main branch. This allows the generated Terraform code to be committed to version control, reviewed via pull request, and deployed through existing CI/CD pipelines, ensuring recovery follows the same operational model as normal infrastructure changes.
Detecting Drift and Rolling Back to Known-Good States
Infrastructure drift complicates recovery. If production has diverged from IaC definitions due to manual changes, running terraform apply during recovery might revert critical operational fixes.
Firefly continuously monitors infrastructure configuration and detects drift between the declared configuration and the running environment. If a configuration issue causes instability, teams can roll back infrastructure to a previously known-good state using versioned snapshots.
Validating Recovery Readiness Before Outages
Most teams discover recovery gaps during an outage: the AMI was deleted, cross-region certificates weren't provisioned, or replication lag is too high to meet RPO targets.
Firefly's Cloud Resilience Posture Management (CRPM) provides continuous visibility into the resilience posture of the environment. It analyzes infrastructure configurations and identifies resources that are not covered by backups or replication, infrastructure components that introduce single points of failure, and configurations that may prevent recovery from meeting RTO or RPO targets.
This allows teams to address resilience gaps before an outage occurs.
Enabling Cross-Account and Multi-Cloud Recovery
Organizations often operate multiple cloud accounts, regions, or even multiple cloud providers. Recovery strategies may involve restoring workloads to another region or account to isolate failures.
Because Firefly stores infrastructure snapshots as Terraform modules, environments can be recreated across accounts or regions as needed. When a restore is triggered, Firefly generates and deploys the Terraform module in the target account or region, recreating all application resources and their dependencies.
This provides flexibility when designing recovery strategies and helps organizations avoid being restricted to a single recovery location.
How Does a DR Platform Compare to Native DR and IaC?
| Capability | Native Cloud DR | IaC Tools | DR Platform |
|---|---|---|---|
| Data replication | Yes | No | Uses native replication |
| Infrastructure provisioning | Limited | Yes | Yes |
| Dependency orchestration | Limited | No | Yes |
| Networking failover automation | Partial | No | Yes |
| Cross-cloud recovery | No | Complex | Yes |
| Recovery readiness monitoring | No | No | Yes |
| Drift-aware rollback | No | Manual | Yes |
| Captures runtime state (not just declared state) | No | No | Yes |
So, now it is clear that:
- Native disaster recovery services from providers like AWS, Azure, and Google Cloud ensure that data and infrastructure resources can be replicated or restored.
- Infrastructure as Code tools such as Terraform, Pulumi, and Crossplane make it possible to recreate infrastructure environments programmatically.
- A disaster recovery platform sits above these layers. It coordinates recovery workflows, ensures infrastructure dependencies are handled in the correct order, manages traffic failover once the recovery environment is ready, and captures working runtime state, including console changes.
This coordination layer enables teams to restore complete application environments rather than restoring individual resources one by one.
FAQs
What is the difference between backup and disaster recovery?
Backups protect data (database snapshots, file versioning, disk images). Disaster recovery restores entire systems, including networking, identity, compute, dependencies, and traffic routing. You can have perfect backups and still fail to recover if VPCs, security groups, IAM roles, and load balancers aren't restored in the correct order.
Do I need a disaster recovery platform if I use Terraform?
Terraform defines infrastructure declaratively but doesn't coordinate recovery events. During incidents, teams still need to restore database snapshots, ensure services start in the correct order, update DNS records, and reconcile differences between declared state (in Git) and runtime state (with console changes). A DR platform orchestrates these operational steps.
What is the difference between a DR platform and AWS Elastic Disaster Recovery?
AWS Elastic Disaster Recovery replicates server disks to another region and launches recovery instances. It focuses on individual resources (VMs, disks). A DR platform coordinates the full application environment: networking, IAM, load balancers, DNS, service dependencies, and traffic failover. It works across multiple cloud providers and accounts.
How does a DR platform help with compliance and RTO/RPO targets?
A DR platform continuously validates recovery readiness: which resources lack backups, whether replication is healthy, and if configurations prevent meeting RTO/RPO targets. Instead of discovering gaps during an outage, teams can identify and fix issues proactively.

.avif)
.avif)


.webp)


.webp)















