
TL;DR
- Backups alone won't save you during cloud outages. When AWS or Google Cloud goes down, having data backups doesn't help if your VPCs, load balancers, and IAM roles can't be recreated. You need automated infrastructure recovery, not just data recovery.
- IaC makes recovery predictable. Infrastructure-as-Code turns recovery from manual reconstruction into automated deployment. Production and DR environments share the same source of truth, eliminating drift and making your RTO measurable instead of theoretical.
- Multi-cloud needs unified enforcement. Running AWS, GCP, and Azure separately creates blind spots. You need one view to catch missing snapshots, invalid AMIs, and configuration drift across all clouds before disaster strikes.
- CRPM operationalizes resilience. Firefly's Cloud Resilience Posture Management continuously validates which assets are protected, whether infrastructure can auto-recover to another region, and if you'll actually meet your RTO targets, making resilience measurable and enforceable.
A recent discussion on r/devops asked a simple question: who is actually running multi-cloud in production after the latest hyperscaler outages, and who is still just planning for it? That question says a lot.
In a few weeks, multiple large cloud providers experienced regional disruptions. Not small service blips, full control plane issues, networking failures, degraded APIs. When those events happen, multi-AZ inside a single region doesn't save you. Snapshots don't help if you cannot rebuild the surrounding infrastructure. And runbooks don't execute themselves.
Most teams say they are resilient because they enable backups and deploy across Availability Zones. Very few teams test rebuilding a full production stack in another region or another account. Even fewer test it when provider APIs are partially degraded.
Cloud environments drift constantly. Engineers create resources in the console. Replication gets disabled. IAM policies change. Over time, the live environment stops matching the intended architecture. Resilience only works if recovery is executable, not theoretical.
To understand how to fix this, we first need to define what cloud resilience really means.
What Does Cloud Resilience Actually Mean? (It's Not Just Backups)
Cloud resilience means your cloud application environment, everything required to serve user requests, continues operating during infrastructure failures and can recover within defined time limits when parts of it break.
Most teams think they're resilient because they've enabled automated backups and deployed across multiple Availability Zones. But when AWS us-east-1 went down in December 2021, or when Google Cloud experienced that 3-hour global outage in June 2025, having backups didn't help teams whose entire infrastructure, VPCs, load balancers, IAM roles, and DNS, was hardcoded to a single region.
Your "environment" includes more than just data:
- VPC, subnets, routing tables
- Load balancers and target groups
- Compute instances or container clusters
- Databases and caches
- Object storage buckets
- DNS records and traffic routing
- The Infrastructure-as-Code and automation that provisions all of it
If any one of those layers fails and your users can't access your application longer than your defined recovery time, your system isn't resilient, even if the database backup completed successfully.
Let's break down what each component of resilience actually requires.
What Cloud Failures Should I Actually Plan For?
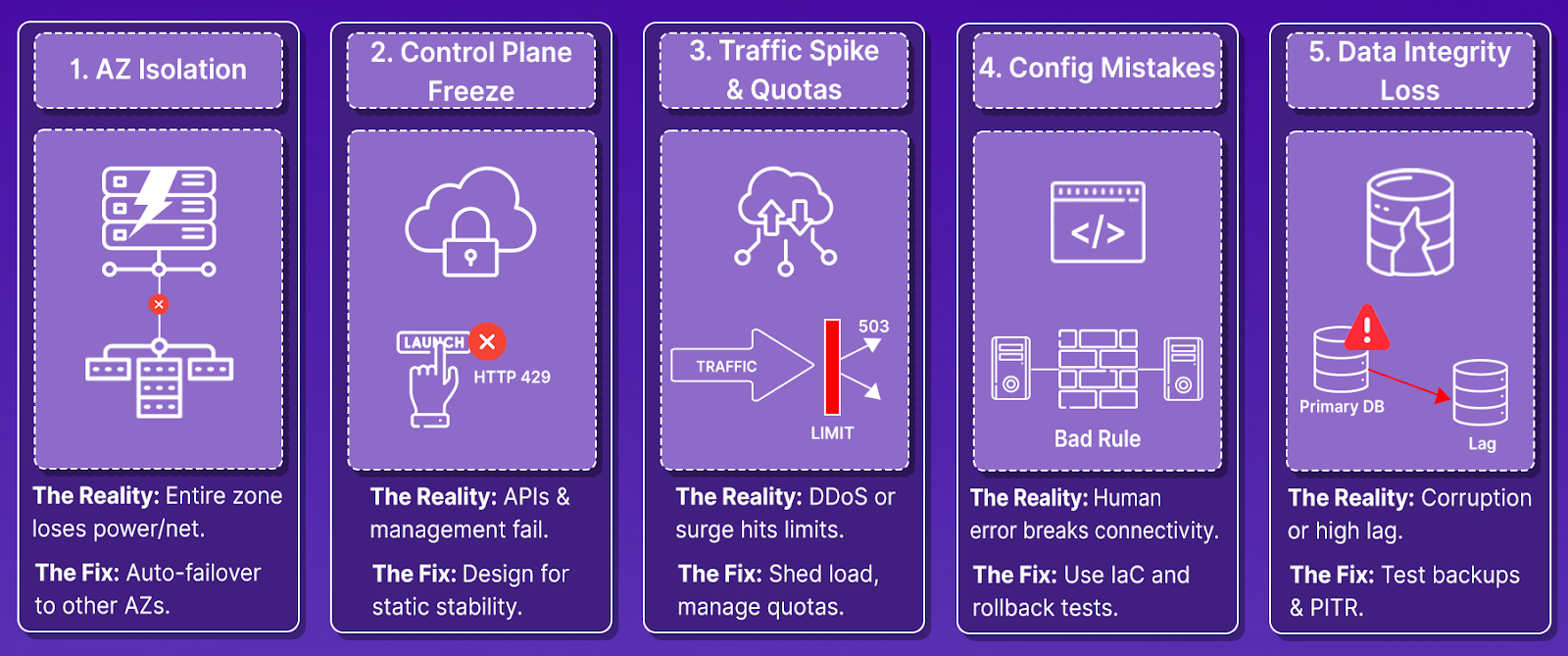
Instead of abstract "high availability," your architecture should explicitly handle these real scenarios:
Availability Zone failures:
- An entire AZ losing power (happened to AWS us-east-1a in 2015)
- Network partitions isolate an AZ from others
- Disk failures affecting multiple instances simultaneously
Regional control plane degradation:
- API throttling is preventing you from launching new instances
- IAM service is returning errors during authentication
- CloudWatch/monitoring APIs are becoming unavailable
- The June 2025 Google Cloud outage, where API management failed globally
Data layer incidents:
- Database primary crashing mid-transaction
- Replication lag exceeding acceptable thresholds
- Someone accidentally disabled automated backups
- Corruption requiring a point-in-time restore
Capacity and traffic issues:
- Marketing campaign tripling expected traffic
- DDoS attack exhausting connection limits
- Auto-scaling is hitting regional instance quotas
- Database running out of IOPS or connections
Configuration mistakes:
- Security group change blocking database access
- Route table update breaking subnet connectivity
- IAM policy change revoking necessary permissions
- DNS TTL preventing traffic shift during failover
These aren't edge cases to consider "someday." Your recovery procedures should have documented, tested responses for each scenario.
How To Keep an App Running When an Availability Zone Goes Down?
Availability means your application endpoints continue responding even when infrastructure components fail.
In practice, that means:
- Application instances are deployed across multiple AZs
- A load balancer performs health checks and removes unhealthy targets automatically
- Databases are configured with Multi-AZ failover
- There are no single-instance bottlenecks in networking or compute
For example, if AZ-A becomes unreachable, the load balancer routes traffic only to instances in AZ-B and AZ-C. The user should not notice. If shutting down one AZ causes downtime, your architecture still has a single point of failure. Availability is about isolating failure domains and ensuring traffic automatically shifts to healthy capacity.
Are My Backups Actually Restorable in Another Region?
Durability ensures that your data survives hardware failure, human error, and regional outages.
This includes:
- Automated database backups with defined retention
- Cross-region snapshot copies for critical systems
- Replication between primary and standby databases
- Versioning for object storage
- Regular restore testing
For example, if a region becomes unavailable, you should be able to restore the most recent snapshot in another Region. The acceptable amount of lost data defines your RPO (Recovery Point Objective). If you have never restored from your backups in a different Region, you are assuming durability, not proving it. Durability is about verified data recovery, not just backup configuration.
What Happens When Traffic Suddenly Doubles?
Scalability protects you from load-related failures.
This means:
- Auto Scaling Groups add capacity based on CPU, memory, or request count
- Managed databases' scale read replicas under heavy query load
- Queues buffer traffic to prevent overload
- Capacity limits are understood and tested
For example, if a marketing campaign doubles traffic, your system should scale without requiring someone to log into the console and manually add instances. Resilience assumes unpredictable traffic and removes manual intervention from scaling paths.
Can I Rebuild My Entire Production Stack from Code Alone?
Recoverability is the most overlooked part of resilience. It means you can recreate the entire environment, including networking, compute, databases, IAM policies, and routing, using automation from another region or account.
This requires:
- Infrastructure-as-Code as the source of truth
- Version-controlled deployment definitions
- Automated database promotion or restore procedures
- Scripted DNS failover or global traffic routing
For example, if an entire Region becomes unavailable, recovery should look like this:
- Promote a cross-region database replica.
- Deploy infrastructure in a secondary Region using IaC.
- Restore application configuration.
- Update DNS or global routing to shift traffic.
- Validate application health.
If that process cannot be executed from automation, recovery will depend on memory and manual effort under pressure. Recoverability is the difference between "we have backups" and "we can restore service."
What Are RTO and RPO?
Resilience is not a design principle; it is a measurable target.
RTO (Recovery Time Objective): Maximum acceptable downtime. RPO (Recovery Point Objective): Maximum acceptable data loss, measured in time. Every workload should have defined RTO and RPO targets.
For example:
- Payments API: RTO = 5 minutes, RPO = near zero.
- Internal reporting tool: RTO = 4 hours, RPO = 1 hour.
Once defined, these must be validated through controlled recovery drills.
If your rebuild process takes 90 minutes but your RTO is 30 minutes, your system is not resilient, regardless of how clean the architecture diagram looks.
Can We Prove Our Resilience Assumptions? A Drift Validation Test
Most production environments don't break all at once; they quietly get less resilient through small changes that no one tracks.
A manager asks to cut costs: RDS backup retention drops from 7 days to 1. No PR, no alarm. A developer launches a quick EC2 for testing and forgets to terminate it. Someone disables Multi-AZ "temporarily" to save money and never re-enables it.
Three weeks later, the dashboards are green, the architecture diagram still says "resilient," but the actual environment is a different story.
We ran this exact scenario to show what terraform plan catches, and what it silently misses.
Baseline: Resilience Defined in Code
We deployed the following stack entirely via Terraform:
- VPC spanning two Availability Zones
- Application Load Balancer across two public subnets
- Auto Scaling Group with two instances across private subnets
- RDS instance with Multi-AZ enabled
- Automated backups with 7-day retention
- Security group trust path: App SG → DB SG
After terraform apply, the environment was fully codified and aligned with documented resilience assumptions: high availability at compute and database layers, defined RPO (7-day retention), and deterministic rebuild capability via Terraform state.
At this point, resilience assumptions were valid.
Injecting Controlled Drift
We then introduced changes manually in the AWS console, without touching Terraform code.
Drift 1: Backup Retention Reduced
RDS backup retention was changed from 7 days to 1 day. The RPO assumption was silently degraded with no alarms triggered.
Drift 2: Multi-AZ Disabled
Multi-AZ deployment was turned off. The database became single-AZ, and high availability was removed. The architecture diagram still showed HA, but reality no longer matched.
Drift 3: Unmanaged Compute Introduced
A new EC2 instance was launched manually in the same VPC, subnet, security group, and AMI, but not attached to the Auto Scaling Group.
Validating instance membership confirmed the gap:
# ASG-managed instances
i-0648ec4d76a5abc41
i-030eeeacba4a3b5b4# All running instances
i-01e927639ac757e9e ← unmanaged
i-0648ec4d76a5abc41
i-030eeeacba4a3b5b4Running terraform state list, the unmanaged instance did not appear. That means it would not be recreated during recovery. IaC coverage was incomplete. This is recoverability drift.
What Terraform Detected, And What It Didn't
Running terraform plan correctly detected:
~ backup_retention_period = 1 -> 7
~ multi_az = false -> true
However, Terraform did not detect:
- That RPO was now violated
- That high availability was removed
- That an unmanaged instance existed outside the state
- That recoverability assumptions were compromised
Terraform detected a configuration mismatch. It did not evaluate resilience posture. That distinction is critical.
What a Manual Resilience Audit Now Requires
To re-validate resilience after this drift, we had to manually inspect:
This is for one workload in one AWS account. Multiply that across 40 workloads, 3 AWS accounts, and 2 additional cloud providers, and manual resilience validation becomes an operational burden that does not scale.
What This Test Revealed
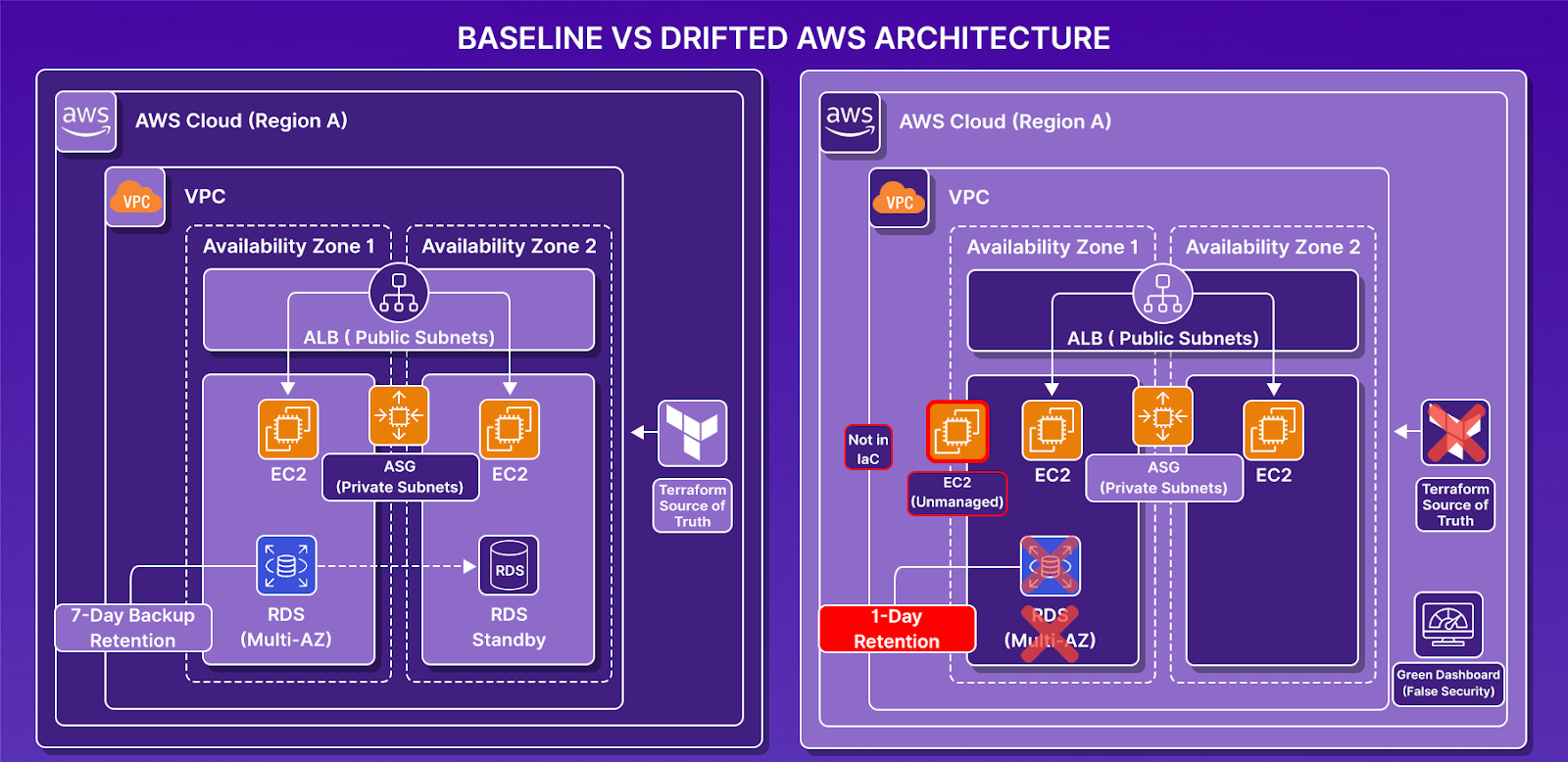
Even though everything started resilient and codified:
- RPO silently degraded from 7 days to 1 day with no alert
- Database high availability was removed, architecture diagram still showed HA
- Unmanaged compute outside IaC, invisible to Terraform, invisible to recovery
- Terraform state no longer represents the full environment
Resilience did not fail catastrophically. It degraded incrementally. And nothing enforced those assumptions continuously.
Infrastructure-as-Code guarantees reproducibility of declared resources. It does not guarantee complete infrastructure coverage, continuous RTO/RPO alignment, detection of unmanaged assets, or enforcement of resilience policies.
You don't lose resilience suddenly. You lose it gradually and only discover it during an incident.
If validating resilience for a single workload takes ~35 minutes of manual inspection, how do you continuously enforce backup policies, AMI integrity, IaC coverage, and drift detection across AWS, GCP, Azure, and Kubernetes clusters? This is where Cloud Resilience Posture Management moves resilience from a periodic audit to continuous enforcement.
How Does Infrastructure-as-Code Make Recovery Faster?
An Infrastructure-as-Code approach changes the recovery model fundamentally. The problem with manual recovery isn't just effort; it's drift. Production environments change constantly: new services deploy, IAM policies tighten, security groups update, autoscaling thresholds tune, and replication settings adjust. Unless your DR environment continuously mirrors these changes, it drifts from production reality. That drift is invisible until recovery day, when your RTO assumptions collapse under operational pressure.
When infrastructure is defined in version-controlled modules, production and recovery environments are built from the same source of truth. Networking, compute, IAM, load balancers, and databases are not recreated manually; they are deployed through automation.
In a regional failure scenario, recovery follows a controlled execution path:
- Infrastructure is deployed in the secondary region using the same IaC modules as production.
- A cross-region database replica is promoted, or a tested snapshot restore process is triggered automatically.
- Application configuration is applied through version-controlled pipelines.
- Traffic routing is updated using scripted DNS failover or global load balancing.
- Health checks validate service readiness before full cutover.
Because these steps are automated and repeatable, they can be tested in controlled drills. Recovery time can be measured precisely. RTO and RPO targets can be validated instead of estimated.
Recovery becomes a deployment workflow rather than a manual reconstruction exercise.
The fundamental difference: Traditional disaster recovery protects data assets and relies on documentation to restore service. IaC-first resilience ensures infrastructure is reproducible, recovery procedures are automated, configuration drift is detected, and failover paths are regularly tested.
Backups restore the data state. Infrastructure-as-Code restores the operational environment. Cloud resilience requires both, but without automated infrastructure recovery, data protection alone does not guarantee service continuity.
But here's the challenge: in a multi-cloud enterprise running AWS, GCP, and Azure simultaneously, how do you ensure resilience policies are enforced consistently across all providers? How do you detect when a disk in GCP lacks snapshots, or an EC2 instance in AWS is running an invalid AMI, or resources drift from their IaC definitions? Manual audits across cloud consoles don't scale, and that's where Firefly's Cloud Resilience Posture Management (CRPM) operationalizes resilience.
How Does Firefly's CRPM Enforce Resilience Across Multi-cloud?
In a multi-cloud enterprise environment, resilience isn't just about enabling Multi-AZ on one database in AWS. It's about continuously validating availability, durability, and recoverability across AWS, GCP, Azure, OCI, and Kubernetes clusters, at scale.
Cloud Resilience Posture Management (CRPM) is a continuous process that monitors and improves your cloud environment's ability to withstand failures and cyber threats. It blends best practices from Disaster Recovery, Cloud Security Posture Management (CSPM), and Cloud Automation to ensure cloud applications can withstand disruptions and recover automatically.
The goal: proactively and reactively assess and strengthen resilience through automated discovery, validation, and remediation.
CRPM answers the questions every CIO, Platform Owner, and SRE should be able to answer instantly:
- Which cloud assets are backed up, and which aren't?
- Can the infrastructure that powers cloud applications automatically be recovered into another region or account?
- Are backups aligned with enterprise policy and recovery objectives?
- What's the application's dependency on specific regions, services, or accounts?
- Are there configuration drifts that risk secondary or recovery sites?
- Is there a full change log for the cloud infrastructure to share with auditors post-incident?
What Cloud Failures Should I Actually Plan For: When AWS US-East-1 went down in October 2025, or Google Cloud experienced that 3-hour global outage in June 2025, organizations with "best-in-class" backup tools found themselves helpless. They had their data safely backed up, yet their applications were offline. Backup without infrastructure recovery is not truly resilient and does not enable business continuity.
Firefly's CRPM sits above native cloud features and enforces resilience at the governance, codification, and recovery layers.
How To Check the Resilience Posture Across Multiple Clouds?
Without a unified view, resilience becomes fragmented. A misconfigured database in GCP is just as risky as one in AWS, but most teams audit each cloud separately, if they audit at all.
Here's how Firefly centralizes resilience posture visibility across all your clouds:
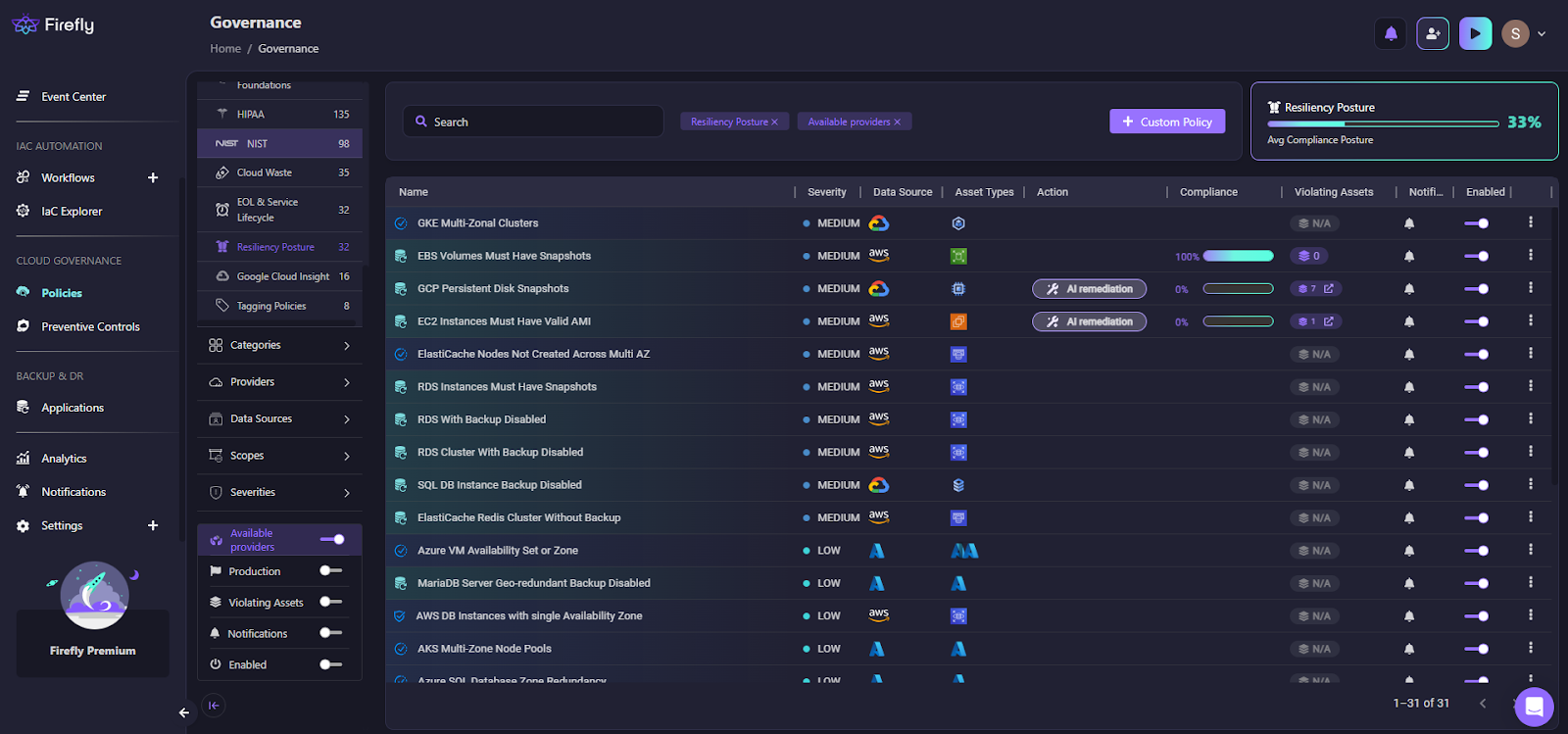
This dashboard shows:
- Resiliency Posture score (33% in this example) - quantified across all clouds
- Policy-based compliance visibility - which policies are violated and where
- Cross-cloud evaluation - AWS, GCP, Azure violations in one view
- Severity categorization - prioritize critical issues first
- Violating asset counts - exact number of resources at risk
How is this important for cloud resiliency?
Instead of logging into AWS Console, then GCP Console, then Azure Portal to check backup configurations:
- You see where your environment fails to meet availability or backup requirements across all providers
- You can quantify posture degradation with a single resilience score
- You can prioritize remediation by severity, regardless of which cloud the resource lives in
- You identify resilience blind spots before they cause outages
Without Firefly:
- You'd rely on manual audits per cloud provider
- There would be no single resilience score across your estate
- Misconfigurations across providers would remain siloed and invisible
- AWS backups might be configured correctly, while GCP snapshots are missing entirely
In enterprise environments, fragmented visibility is the first cause of resilience failures. When us-east-1 goes down, and you try to failover to GCP, discovering that GCP resources lack proper snapshots isn't a recovery plan; it's a crisis.
How To Make Sure Every Disk Has a Backup Snapshot?
Resilience depends heavily on durability controls. Here is how Firefly enforces snapshot requirements in GCP:
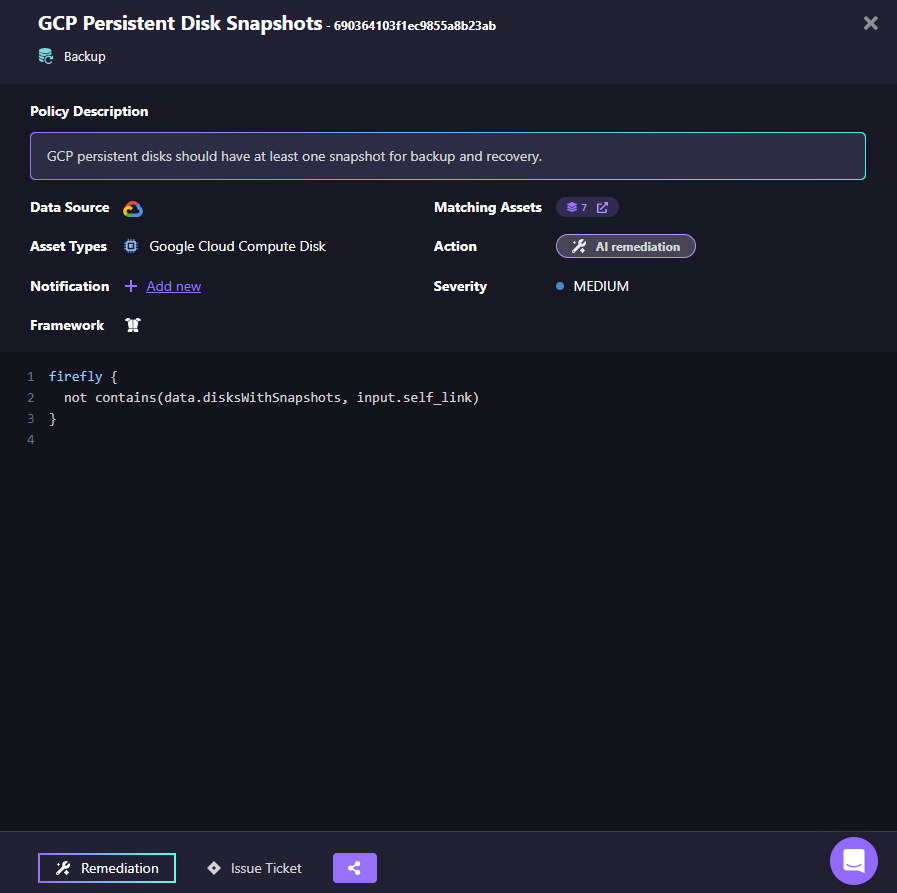
This policy states: GCP persistent disks must have at least one snapshot for backup and recovery. Under the hood, the policy checks whether the disk's self_link exists in a snapshot dataset.
This is not documentation. It is executable logic.
From a resilience perspective:
- Any disk without a snapshot immediately violates RPO assumptions.
- Enterprises running workloads across regions can enforce backup consistency.
- Snapshot gaps are detected before failure happens.
Without Firefly:
- A disk created manually in GCP could run for months without backup.
- During a region outage, that disk's data would be unrecoverable.
- RPO assumptions would silently fail.
Resilience is only as strong as the weakest unprotected disk.
Why Can't I Rebuild My EC2 Instances After a Regional Outage?
Recoverability depends on reproducible computing. Here's how Firefly enforces AMI validity in AWS:
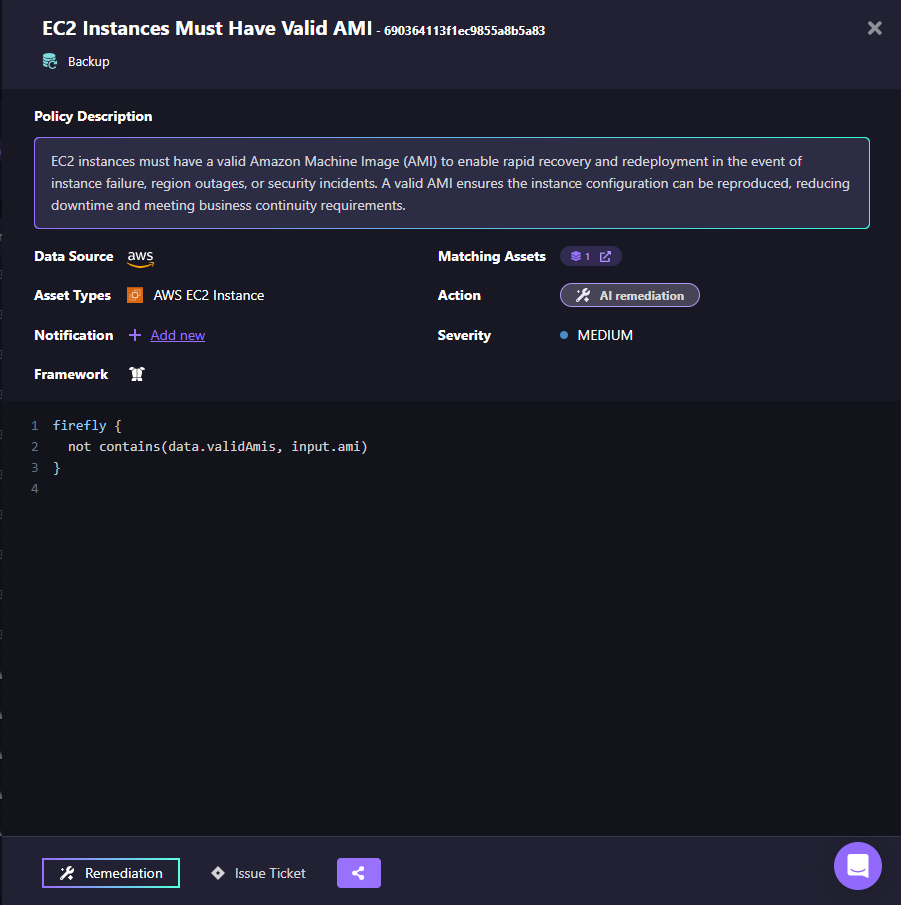
This policy ensures:
- EC2 instances are built from approved AMIs.
- Images are standardized and version-controlled.
- Recovery instances can be redeployed predictably.
Why this matters technically:
During a region outage, you cannot rebuild instances if:
- AMIs were manually created and never versioned.
- Instances drifted away from standardized images.
- Golden images were not tracked.
With Firefly:
- Invalid AMIs are flagged.
- Recovery readiness is continuously validated.
- Rebuild assumptions remain intact.
Without Firefly:
- Instances may rely on snowflake configurations.
- Recovery becomes a manual rebuild of the instance state.
- RTO increases unpredictably.
Backups restore data. Valid AMIs restore compute deterministically.
How Much of The Infrastructure Is in Code?
Resilience fails when infrastructure exists outside code. Here's how Firefly shows Infrastructure-as-Code coverage:
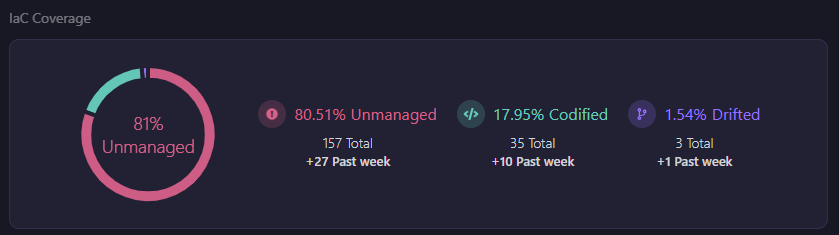
This view highlights:
- Codified vs Drifted vs Unmanaged resources
- IaC coverage percentage
- Resource-level classification
In a multi-cloud enterprise, this is important. If 20% of resources are unmanaged:
- They cannot be redeployed automatically.
- They may not exist in DR regions.
- They may bypass resilience policies.
Without codification:
- Recovery depends on engineers remembering console changes.
- DR drills expose missing resources.
- Outage time increases due to manual recreation.
Firefly ensures that what exists in production also exists in version-controlled infrastructure definitions. That is the foundation of executable recovery.
How To Manage Disaster Recovery Across Multi-clouds?
Enterprises rarely run a single cloud.
They run:
- AWS for core services.
- GCP for analytics or ML.
- Azure for certain enterprise workloads.
- Kubernetes clusters across providers.
Resilience must span all of them.
Firefly provides:
- Centralized policy enforcement.
- Unified resilience posture scoring.
- Cross-cloud IaC alignment.
- Drift detection across providers.
- Automated remediation workflows.
Without this layer:
- Each cloud is governed separately.
- DR readiness varies per platform.
- Failover plans depend on provider-specific manual steps.
- RTO and RPO are theoretical rather than validated.
What's the Difference Between Resilient Architecture and Operational Resilience?
Cloud providers give you building blocks for availability.
Firefly ensures those building blocks are:
- Configured correctly.
- Enforced continuously.
- Aligned with Infrastructure-as-Code.
- Measurable across multi-cloud estates.
- Executable during real incidents.
If Firefly were not present:
- Drift would accumulate silently.
- Backup gaps would go unnoticed.
- AMI inconsistencies would break rebuild assumptions.
- A multi-cloud posture would fragment.
- Recovery would rely on manual intervention.
With Firefly:
Resilience becomes:
- Observable
- Enforced
- Codified
- Automatable
- Testable
That is the difference between having resilient architecture and having operational resilience.
FAQs
What is meant by resiliency in cloud computing?
Resiliency in cloud computing is your application's ability to continue operating during infrastructure failures and recover within defined time limits. It's not just backups—it means your entire environment (VPCs, load balancers, compute, databases, IAM, DNS) can survive failures and be rebuilt automatically. True resiliency ensures users can access your application even when an Availability Zone fails or a region experiences API degradation.
What is resilience in AWS?
Resilience in AWS means architecting applications to withstand failures using Multi-AZ deployments, RDS failover, Auto Scaling Groups, and cross-region backups. AWS provides the building blocks, but you're responsible for configuring them correctly, codifying infrastructure in Terraform or CloudFormation, and testing that recovery actually meets your RTO targets.
What is resilience in Azure?
Resilience in Azure involves using Availability Zones, Availability Sets, Azure Site Recovery, and geo-redundant storage for regional redundancy and disaster recovery. Like AWS, Azure provides the tools, but achieving true resilience requires Infrastructure-as-Code (Terraform, Bicep, ARM templates), regular DR testing, and validating backups are restorable in alternate regions.
What is the difference between scalability and resiliency?
Scalability handles increased load by adding resources—answering "Can we handle 10x more traffic?" Resiliency handles failures—answering "Can we stay online when us-east-1 goes down?" You can have a highly scalable application that completely fails during a regional outage if it's not resilient. Both are essential: scalability handles growth, resiliency handles disasters.
.webp)


.webp)















