
TL;DR
- DR is having backups and replicas. DR orchestration is the automated sequence that rebuilds the entire dependency graph, including VPC, IAM, compute, and DNS, in the correct order. Without it, an on-call engineer is improvising that sequence during the outage.
- The database is available in 5 minutes. The application stays down for 2 more hours because nobody automated what comes after the replica promotion.
- The AWS DR Orchestrator Framework covers RDS, Aurora, and ElastiCache failover via Step Functions. Networking, compute, IAM, DNS, and application config are out of scope; that's your problem to solve.
- Drift between your IaC repo and what's actually running is the most common reason recovery fails after the database is already available. Firefly snapshots the live state and converts it to Terraform on restore, so you're rebuilding what was actually running, not what the repo last said.
Most teams running production workloads on AWS have cross-region replication in place, RDS read replicas, Aurora Global Databases, and ElastiCache Global Datastores. What they discover during an actual outage is that replication and recovery are not the same thing. Uptime Institute's 2025 Annual Outage Analysis found that 54% of organizations reported their most recent significant outage cost over $100,000, with 20% exceeding $1 million per incident. Most DR plans stop at "promote the replica," which handles the database and leaves everything else to whoever is on-call.
The problem isn't the database. The database comes back in minutes. The problem is the twelve other things that depend on it: the VPC and subnets that need to exist in the recovery region, the IAM roles that need to be attached to compute, the ECS task definitions that still point to the old database endpoint, the Secrets Manager entries that may not have been replicated, the load balancer that needs healthy targets before Route 53 can be updated. Each of those is a separate failure. Each one keeps the application down even after the database shows as AVAILABLE.
This is the gap that DR orchestration is designed to close, not just promoting a replica, but automating the entire sequence of steps that turn a recovered database into a recovered application. This blog covers how that orchestration works in AWS, where the AWS DR Orchestrator Framework starts and stops, and how to handle the infrastructure layer it doesn't touch.
What Is Disaster Recovery Orchestration? (And Why Failover Isn't Enough)
Disaster recovery orchestration in AWS means automatically restoring a production workload spanning multiple cloud resources after a failure in the correct order.
Here's a typical SaaS product running in AWS, such as multiple services, each with its own failure surface:
- An API running on ECS or EKS
- An Application Load Balancer in front of it
- An Amazon RDS or Aurora database
- Redis on ElastiCache
- IAM roles attached to compute
- Secrets stored in Secrets Manager
- DNS managed in Route 53
If the primary region fails, recovery means rebuilding this entire stack in another region in the correct order. Compute can't start without networking, the application can't connect without IAM and secrets, and traffic can't switch without healthy load balancer targets.
DR orchestration is the automation that enforces that sequence: replica promotion, Terraform apply, ECS task definition update, security group validation, Secrets Manager check, health checks, Route 53 cutover, in order, without a human figuring it out mid-outage.
A failure at any one of these steps leaves the service down, regardless of how healthy the rest of the stack looks.
Restoring the Database to a Writable State
The database comes first because everything else in the stack depends on it. An ECS service that starts before the database is writable will fail its health checks, get marked unhealthy, and get terminated. You'd then need to cycle it again after the database is ready anyway. Getting the database writable before touching anything else avoids that class of failure.
The specific action depends on what you're running. If you're on RDS PostgreSQL or MySQL with a cross-region read replica, promoting that replica stops it from replicating from the primary, accepts writes, and gives it a new endpoint. If you're on Aurora, you fail over the Global Database secondary cluster in the recovery region. If you're on a different engine entirely, SQL Server, Oracle, the promotion mechanism differs, but the outcome is the same: a writable instance in the recovery region with a new endpoint.
That new endpoint is what breaks everything downstream. The ECS task definitions, the application config, and the connection strings in Secrets Manager all of them still point to the old us-east-1 endpoint. The database is writable, but no running service can reach it yet.
Rebuilding Networking and Compute in the Target Region
If the primary region is unavailable, the following may no longer be accessible: VPC, subnets, NAT gateways, load balancers, Auto Scaling groups, Kubernetes worker nodes, and ECS services.
To recover the service, these resources must exist in the secondary region and be configured correctly. VPC CIDR blocks must not conflict. Subnets must align with availability zones. Security groups must allow the correct traffic. IAM roles must exist with the correct policies. Compute must be able to start and attach to the network.
If the compute instance cannot connect to the database, recovery has failed, even if the database is healthy.
This part of the recovery is usually more complex than the database promotion itself.
Redirecting Traffic to the New Region
Even if the database is writable and the compute is running, users will still hit the failed region unless traffic is redirected. That means updating Route 53 records, switching failover routing policies, confirming health checks pass, and verifying target groups are healthy.
Traffic switching must happen after the infrastructure is ready. Switching too early sends users into a broken environment and creates a second failure on top of the original one.
Verifying That the Application Actually Works
This is where most recovery plans stop too early. Resources may show as "healthy" in the AWS console, but the application can still fail because environment variables reference old endpoints, IAM permissions differ in the recovery region, KMS keys are region-scoped and missing, or security groups block east-west traffic between services.
Recovery is complete only when the API connects to the database, secrets can be read and decrypted, background workers process jobs, health endpoints return 200, and users can complete a real transaction.
That validation step must be part of the recovery workflow, not something you run after you think recovery is done.
How Disaster Recovery Orchestration Works (The Architecture)
Those four steps only work if the right pieces are already in place before the outage. Most recoveries fail not because the orchestration logic is wrong, but because the environment was never set up to be recoverable. Here's what has to be true upfront.
1. Verifying That Recovery Is Even Possible
Before any outage, the system must continuously verify that recovery prerequisites exist. Not abstractly, by checking specific configuration states:
- Every production RDS instance has a backupRetentionPeriod > 0
- Multi-AZ is enabled for databases that require high availability
- Read replicas exist in a different region
- Backup retention matches business requirements (7 or 30 days, depending on your SLA)
- ElastiCache clusters are configured for Multi-AZ
- Kubernetes node groups span multiple AZs
- IAM roles required by compute exist in the DR region
- KMS keys required for encryption exist in the DR region
- Restoring from backup is tested on a nightly or weekly schedule. A backup that has never been restored is an assumption, not a recovery point
If even one of these conditions is false, recovery can fail.
Example: If backupRetentionPeriod is set to 0, you cannot restore from a backup. If no cross-region replica exists, you cannot promote during an outage. If KMS keys are region-scoped and not replicated, decryption fails even after the database is restored and shows as available.
Run a DR drill at least monthly, and weekly if your SLA is tight. Promote the replica in the recovery region, apply Terraform, bring up compute, validate the health endpoint, then tear it down. Every gap you find in a drill is a gap you don't find during an actual outage. Track the time it takes end-to-end; that number is your real RTO, not the one in the runbook.
2. Capturing the Actual Cloud State
Most teams assume IaC defines everything running in production. Production environments drift from their IaC definitions constantly.
A security group modified directly in the AWS console. An IAM role adjusted to resolve an urgent permissions issue. A load balancer listener rule was added during an incident. A database parameter changed outside Terraform.
If those changes are not reflected in code, rebuilding from IaC will not recreate the actual production state. You'll get an environment that deploys cleanly but behaves differently, and you'll spend your RTO window finding out why.
State capture means discovering all active cloud resources, recording their current configuration, converting them into deployment-ready IaC, and versioning that state. Without accurate state capture, reconstruction becomes partial, and partial reconstruction is a different kind of failure.
3. Executing Recovery in the Correct Order
Recovery steps cannot be executed in any arbitrary order. There is a strict dependency chain that must be respected.
You cannot launch ECS tasks before subnets exist. You cannot attach security groups before the VPC is deployed. You cannot connect the application before the database is writable. You cannot switch DNS before health checks pass.
A cross-region recovery follows an order like this:
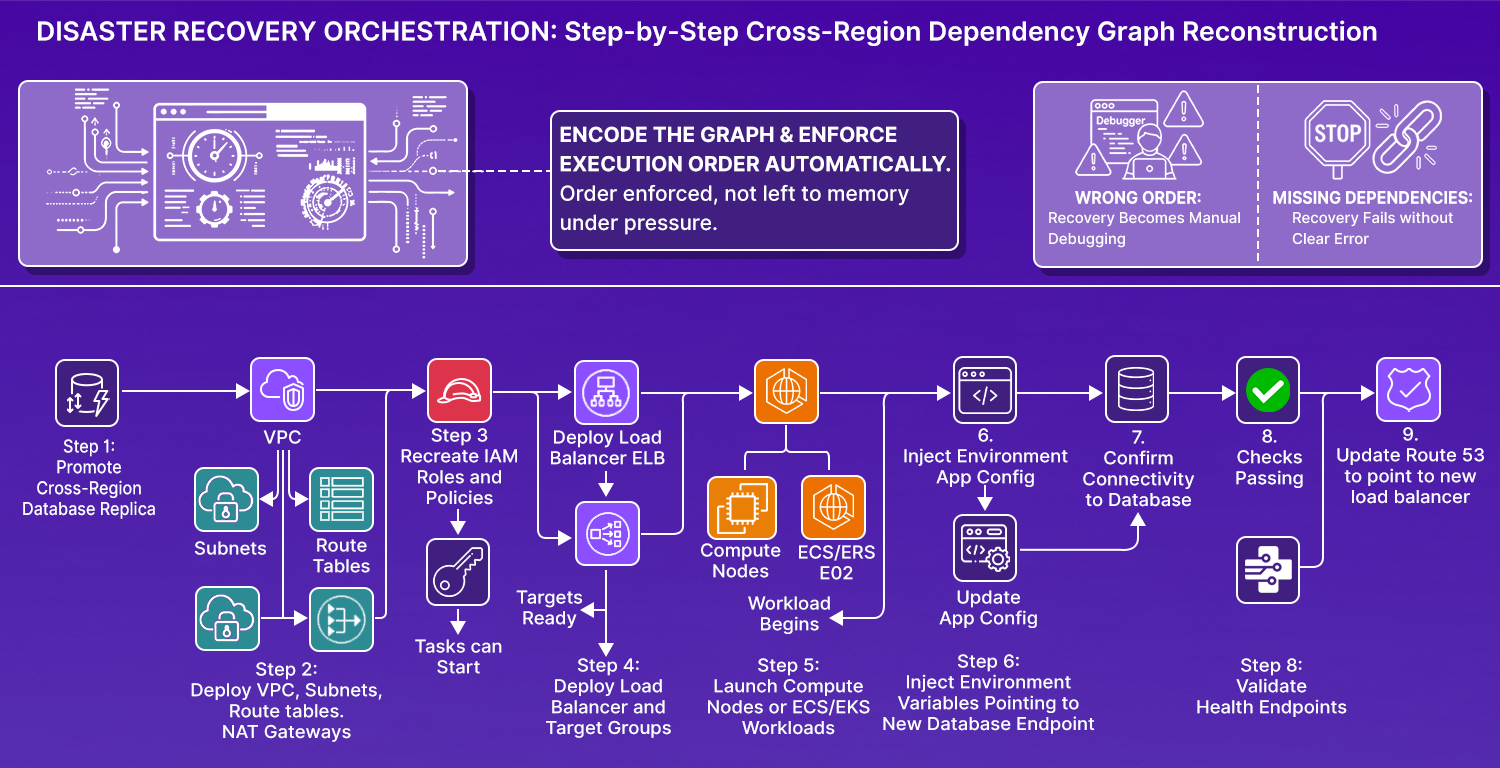
Each step depends on the previous one succeeding. Good orchestration systems encode these dependencies explicitly, so the order is enforced automatically rather than left to whoever is on-call to remember under pressure.
4. Verifying Functional Recovery
The AWS console will show resources as "healthy" even when the application is broken. RDS shows AVAILABLE, but security groups block traffic. ECS tasks show RUNNING, but they cannot decrypt secrets. The load balancer shows targets as healthy, but the API returns 500.
Functional validation must confirm that the application opens a database connection successfully, required secrets can be decrypted with KMS, internal service calls succeed, background workers process jobs, and a test transaction completes end-to-end.
#!/bin/bash
# post-restore-validation.sh
set -e
echo "Starting post-restore validation..."
# 1. Check database connectivity
echo "Testing database connection..."
aws rds describe-db-instances \
--db-instance-identifier production-db \
--query 'DBInstances[0].DBInstanceStatus'
# 2. Validate IAM role permissions
echo "Validating IAM roles..."
aws iam simulate-principal-policy \
--policy-source-arn arn:aws:iam::${ACCOUNT_ID}:role/app-role \
--action-names secretsmanager:GetSecretValue \
--resource-arns arn:aws:secretsmanager:${REGION}:${ACCOUNT_ID}:secret:db-password
# 3. Test application health endpoint
echo "Checking application health..."
RESPONSE=$(curl -s -o /dev/null -w "%{http_code}" https://app.example.com/health)
if [ "$RESPONSE" -ne 200 ]; then
echo "Health check failed with status: $RESPONSE"
exit 1
fi
# 4. Run the smoke test transaction
echo "Running smoke test transaction..."
curl -X POST https://app.example.com/api/test-transaction \
-H "Authorization: Bearer $TEST_TOKEN" \
-d '{"test": true}'
# 5. Verify Secrets Manager access
echo "Verifying secrets accessibility..."
aws secretsmanager get-secret-value --secret-id db-password > /dev/null
echo "Post-restore validation complete."
Infrastructure-level health is not enough. Service-level validation is what actually confirms recovery.
What AWS Actually Orchestrates (And What It Leaves to You)
AWS offers a structured framework, the DR Orchestrator Framework, that automates cross-region database failover and failback for certain managed services. Before integrating it into any recovery plan, you need to know exactly what it handles and where it stops.
What the Framework Does
AWS implements the DR Orchestrator using AWS Step Functions as the workflow engine and AWS Lambda as the action runner. The Step Functions state machines encode the decision logic, and the Lambda functions make API calls via Boto3 to operate the database services.
The framework supports failover and failback for three managed data services:
- Amazon RDS: classic RDS engines with cross-region read replicas
- Amazon Aurora: Global Database secondary clusters
- Amazon ElastiCache: Redis OSS with Global Datastore
Here's how it works. A FAILOVER state machine is invoked with a JSON payload. Step Functions parse that payload and route to sub-flows based on resourceType, for example, PromoteRDSReadReplica, FailoverAuroraCluster, or FailoverElastiCacheCluster. Each sub-flow invokes one or more Lambda functions that:
- Resolve CloudFormation exports via a "Resolve imports" Lambda step
- Call the appropriate AWS APIs to promote the target replica or cluster
- Poll until the promoted resource's status becomes AVAILABLE
The JSON input supports a layer field. All resources in the same layer run in parallel; resources in a higher layer wait until the previous layer completes. This gives you a way to express ordering between database resources without hardcoding sequential waits.
Failback follows the same pattern but includes a rebuild sequence: the FAILBACK state machine deletes the former primary instance, creates a read replica from the new primary back in the original region, and waits until the replica reaches AVAILABLE. AWS recommends taking a manual snapshot before failback and disabling deletion protection to allow the delete/create flow.
What the Framework Does Not Do
The AWS DR Orchestrator Framework does not:
- Recreate or reconfigure networking (VPC, subnets, route tables, gateways)
- Provision or scale compute (EC2, ECS, EKS, Lambda deployments)
- Restore IAM roles, policies, or instance profiles in the DR region
- Update DNS (Route 53 failover records)
- Rewrite application configuration (environment variables, connection strings)
- Validate application functionality end-to-end
Once the database is promoted in the target region, the framework considers its job done. It does not build anything outside the managed database services.
A writable database without an application, networking, or validated configuration does not deliver service continuity. The AWS framework automates the database control plane, not the full recovery stack.
Preconditions You Must Meet Before Relying on This Framework
Three real-world prerequisites must be in place before running FAILOVER:
A cross-region replica or secondary cluster must already exist in the DR region. The state machines do not create replicas from scratch; they assume one is already running. The Step Functions logic also expects CloudFormation export values in the input JSON, so your infrastructure stacks must output the ARNs and identifiers the orchestrator needs to resolve at runtime. Parallel execution of multiple database resources is controlled by the explicit layer field in the input JSON, not by implicit dependency detection.
If these preconditions aren't met, the state machine fails during an outage, which is the worst possible time to discover that.
Disaster Recovery Is a Dependency Graph Problem
Strip away the tooling, and disaster recovery on AWS is a dependency problem. A production workload is a set of resources that depend on each other in a specific order. Map out a common setup, and it looks like this:
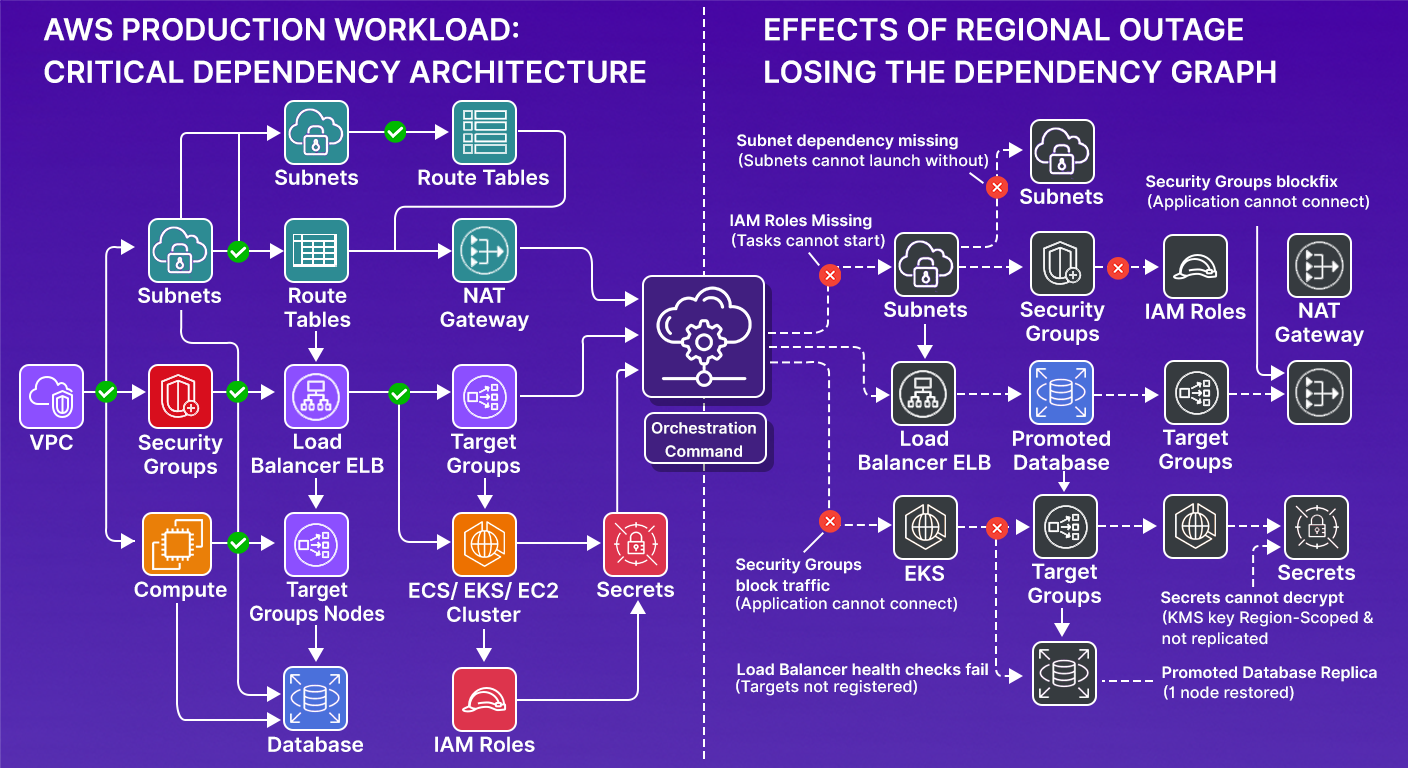
Each node has hard dependencies. Compute cannot launch without subnets. Subnets cannot function without route tables. Tasks cannot start if IAM roles are missing. Applications cannot connect if security groups block traffic. Secrets cannot be decrypted if the KMS key is region-scoped and not replicated to the recovery region. Load balancer health checks fail if targets aren't registered. Database connections fail if the endpoint changes and the application configuration wasn't updated to match.
During a regional outage, you lose most or all of this graph in the primary region.
When you promote a database replica in another region, you restore exactly one node in that graph: the database. Everything else must either already exist in the secondary region or be rebuilt, in the correct dependency order.
This is why "fail over the database" is not a disaster recovery plan. It's one step in a reconstruction of a dependency graph. Orchestration exists to encode that graph and enforce the execution order. If that order is wrong, recovery becomes manual debugging. If dependencies are missing, recovery fails without a clear error.
What the AWS DR Orchestrator Actually Executes Step by Step
Most teams read the AWS documentation, deploy the CloudFormation stacks, and assume the orchestration is wired. But understanding what the state machines actually execute at each step changes how you think about gaps in coverage.
Here's what the FAILOVER state machine input looks like for a multi-database stack:
{
"StatePayload": {
"Layers": [
{
"LayerOrder": 1,
"Resources": [
{
"ResourceType": "RDS",
"ResourceName": "app-db-replica",
"Region": "us-west-2",
"Action": "FAILOVER"
}
]
},
{
"LayerOrder": 2,
"Resources": [
{
"ResourceType": "ElastiCache",
"ResourceName": "app-cache-replica",
"Region": "us-west-2",
"Action": "FAILOVER"
}
]
}
]
}
}
Layer 1 runs first, RDS promotion completes, and reaches AVAILABLE. Layer 2 starts only after Layer 1 finishes, and ElastiCache failover runs. This sequencing matters because your application likely reads from cache before writing to the database, and a cache that tries to connect to a replica that hasn't been promoted yet will fail in ways that are hard to diagnose under outage pressure.
What the state machine does not know: whether the ECS service in us-west-2 has the new RDS endpoint injected into its environment variables. Whether the security group in us-west-2 allows the ECS task to reach the promoted RDS instance on port 5432. Whether the Secrets Manager secret in us-west-2 was replicated from us-east-1 and contains the correct credentials for the promoted database.
Those three gaps are entirely outside the state machine's scope. Each one is capable of keeping the application down after the database reports as AVAILABLE.
The Lambda function that executes PromoteRDSReadReplica calls rds:PromoteReadReplica and then polls rds:DescribeDBInstances until status is available. That is the full scope of what it does. The application layer is yours to handle.
How Firefly Handles the Infrastructure Layer DR Orchestration Leaves Incomplete
AWS handles database promotion. Terraform handles infrastructure rebuilding. But there's a gap between them that most teams don't close: ensuring the infrastructure being rebuilt actually matches what was running in production, not what the IaC repo says was running six months ago. And this has to be done manually by engineers, which is a time-consuming process that directly eats into your restoration window and pushes your actual RTO well past what your SLA promises.
Checking Whether Your Environment Can Actually Recover Before an Outage Hits
Recovery fails most often not because orchestration logic is wrong, but because the environment was never recoverable in the first place. As shown in the resiliency posture below:
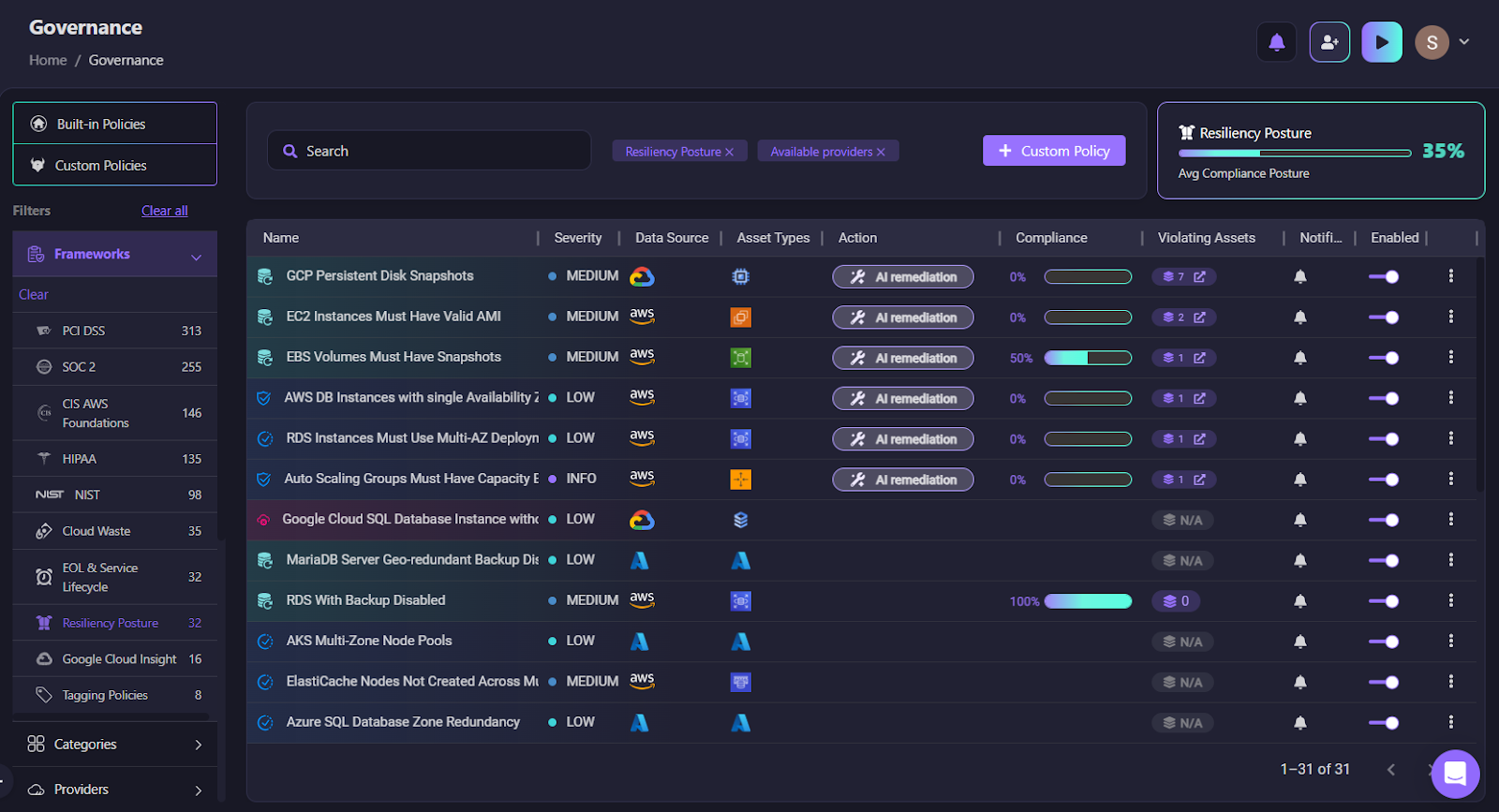
Firefly's governance view includes built-in resiliency policies that validate DR prerequisites directly:
- RDS With Backup Disabled: if backupRetentionPeriod = 0, restore is impossible
- RDS Instances Must Use Multi-AZ Deployment: a single-AZ instance means an AZ failure becomes a full outage
- Aurora Clusters Must Have Multiple Instances: single-instance Aurora cannot fail over
- AWS Auto Scaling Groups with Single AZ: compute recovery in the secondary region becomes fragile
- GKE Multi-Zonal Clusters and Azure SQL Geo-redundant Backup Disabled for multi-cloud environments
These aren't generic compliance checks; instead, they validate whether recovery can actually succeed. CRPM evaluates these continuously across AWS, Azure, and GCP accounts, identifying blockers before an outage, not during one.
Backing Up the Entire Application State, Not Just the Database
Firefly doesn't treat disaster recovery as an account-level backup operation. It treats recovery as an application-scoped operation.
An application is defined using tag selectors, for example, Project = app-infra and Environment = production, as shown in the snapshot below:
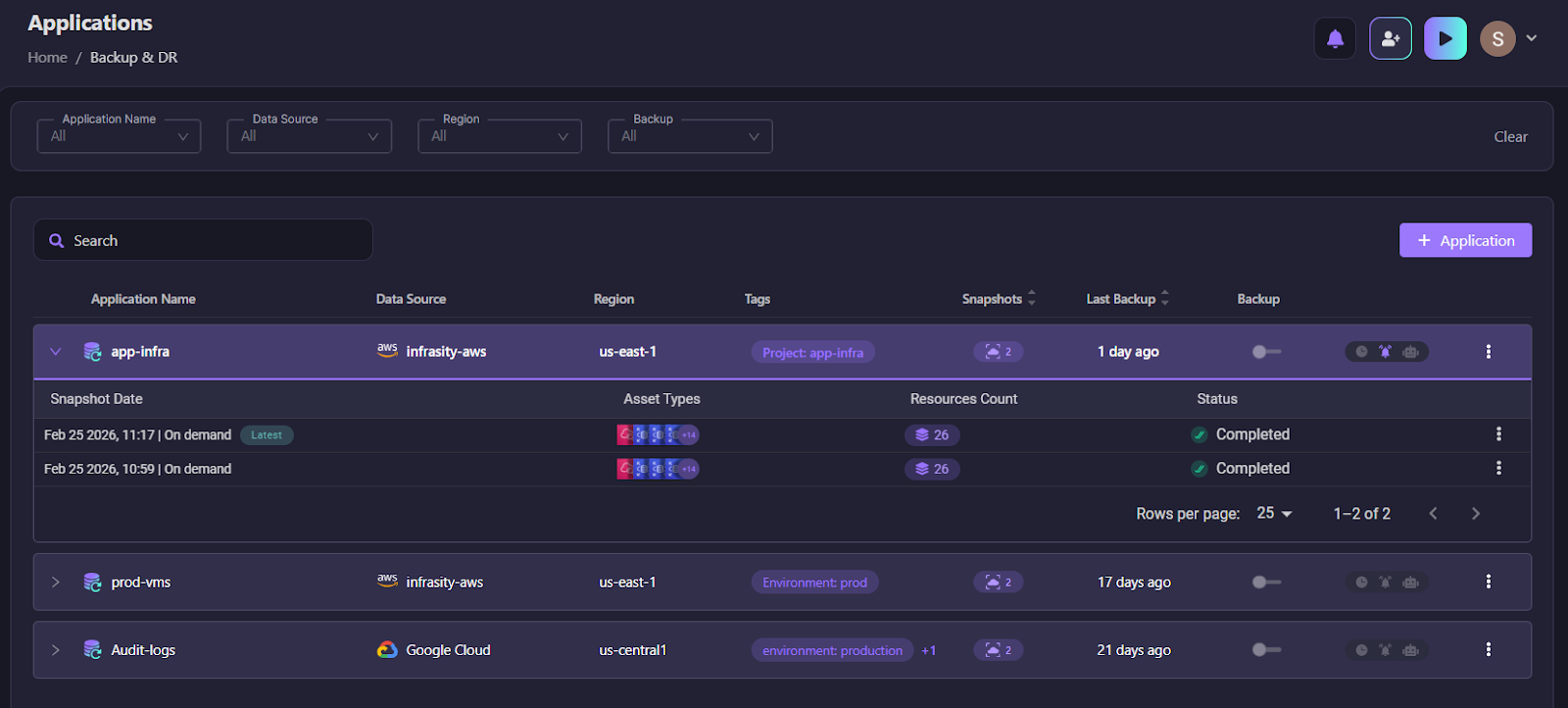
When a snapshot runs, Firefly captures all resources matching the policy scope, their relationships, and their required dependencies. Here’s how we get the relationship graphs of the snapshots in Firefly:
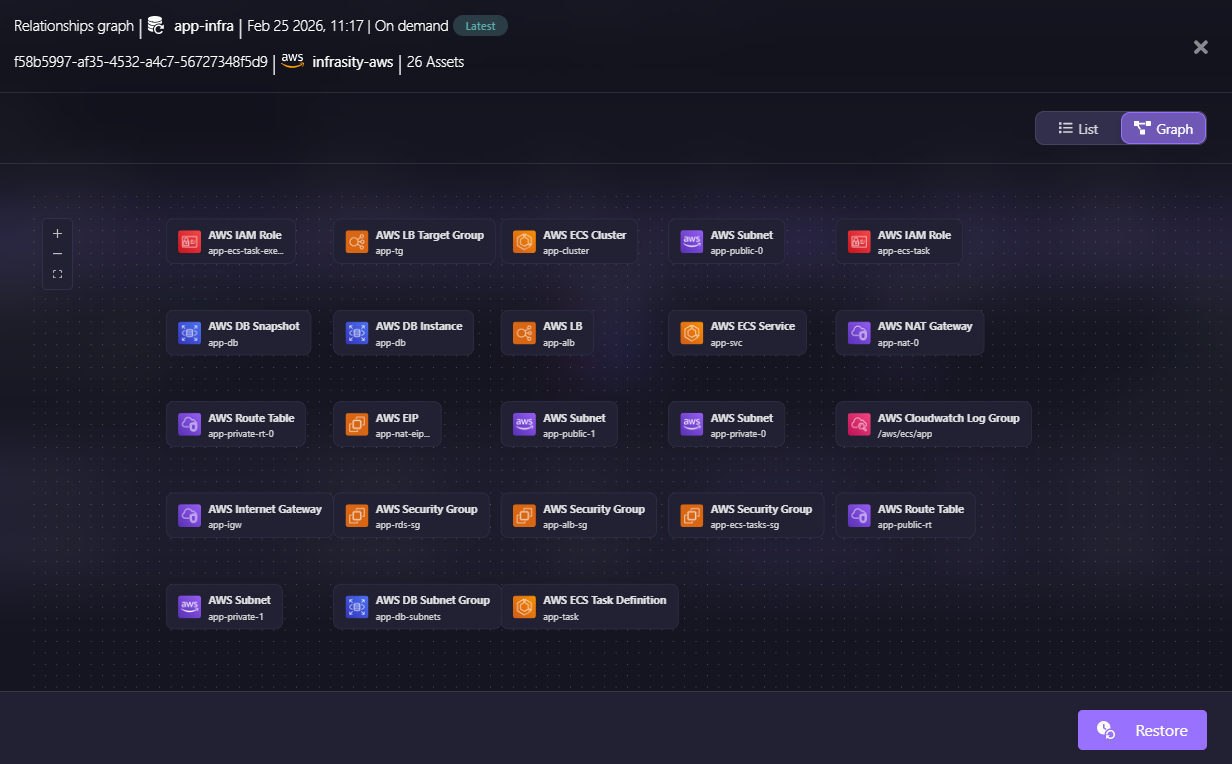
If an EC2 instance matches the policy, Firefly automatically includes the VPC, subnet, security groups, IAM instance profile, and associated networking components.
Snapshots are not binary backups. They are structured representations of the live cloud state at a point in time, including any configuration that has drifted from IaC. Deleted assets and resources in an undetermined state are excluded so only valid, restorable configurations are captured.
The snapshot becomes the recovery source, the actual running state, not the IaC repo that may not have been updated since the last manual console change.
Restore generates Terraform, So Recovery Goes Through Your Existing Git workflow.
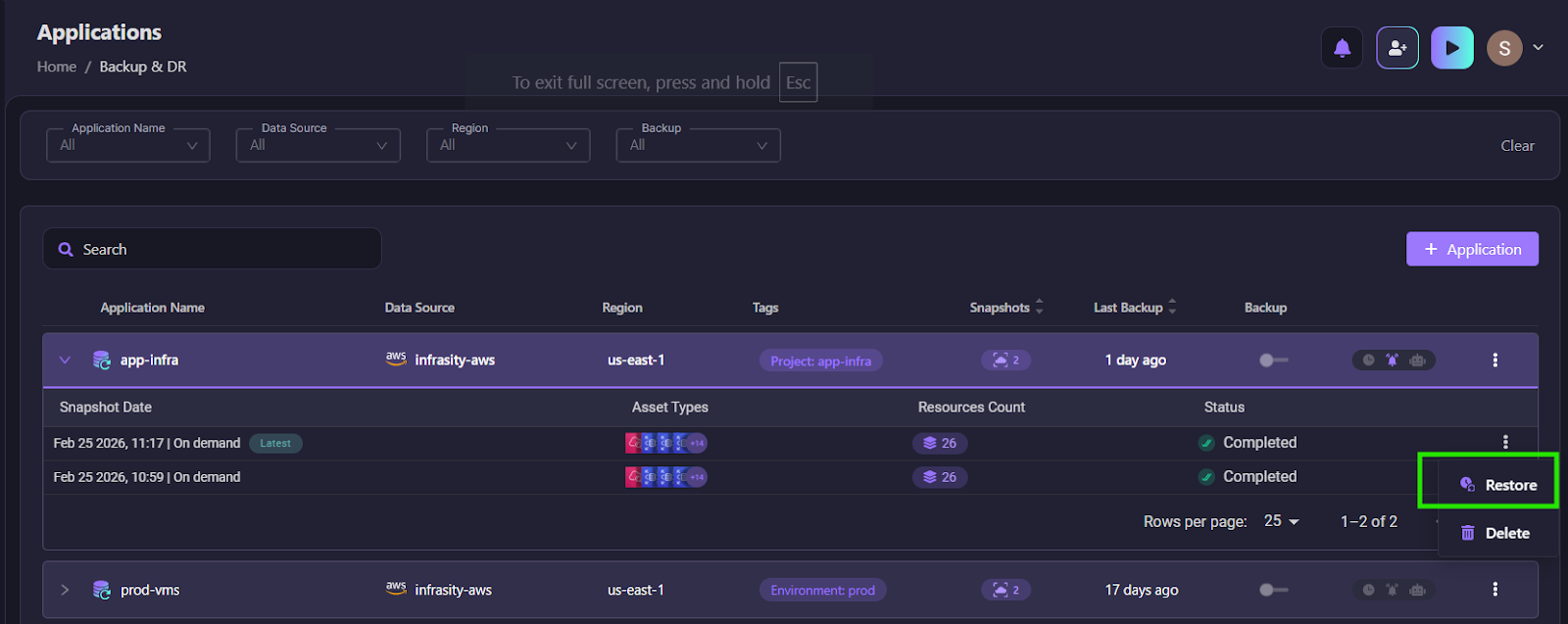
When you select "Restore" on a snapshot, Firefly fetches snapshot resources, processes module definitions, and generates Terraform files: backend.tf, main.tf, provider.tf, variables.tf, outputs.tf, locals.tf.
Firefly does not directly recreate infrastructure via cloud API calls. It converts the snapshot state into a Terraform configuration as shown below:
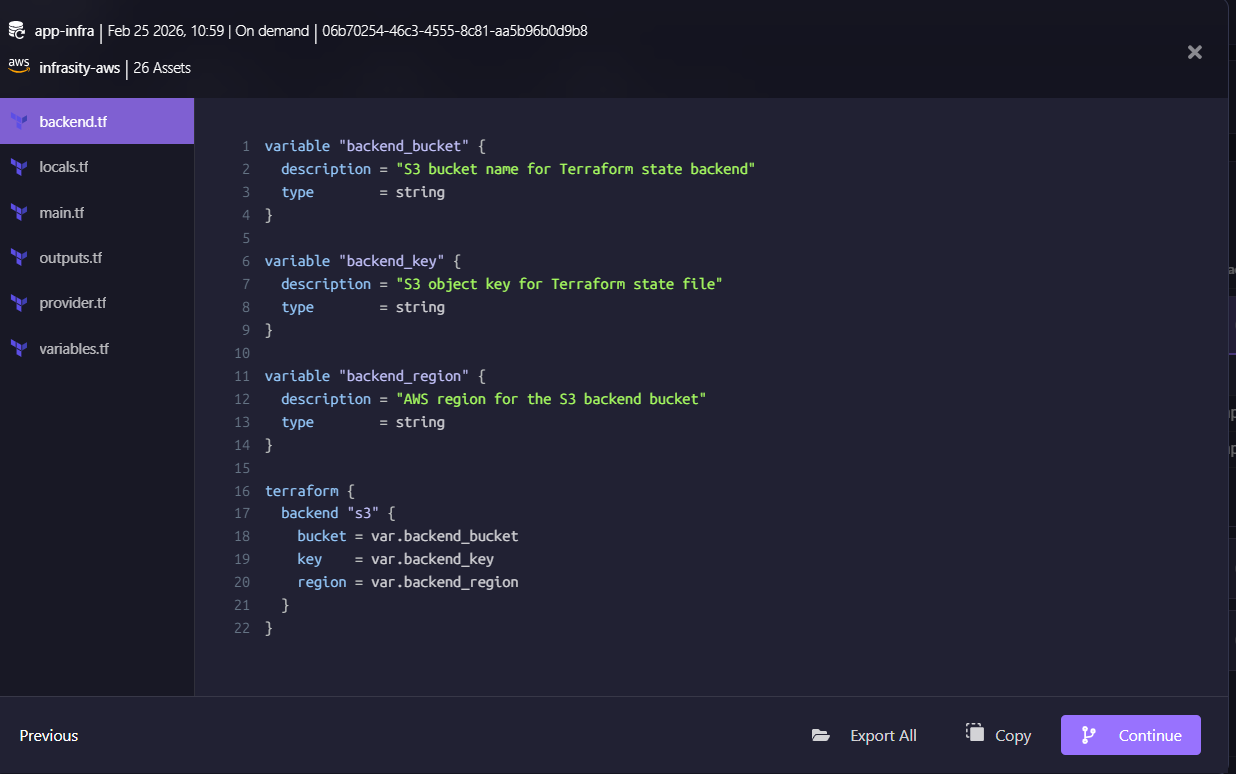
This matters for recovery because changes are reviewable, drift is minimized, and recovery aligns with your existing Git workflows instead of creating out-of-band changes that break IaC compliance going forward.
Every Recovery Is a Reviewed, Auditable Pull Request, Not a Console Click
After Terraform is generated, Firefly integrates with your VCS. A PR is created targeting your main branch, containing the Terraform files, a Firefly bot comment, the snapshot reference ID, and verified commits. Here is how the PR looks:
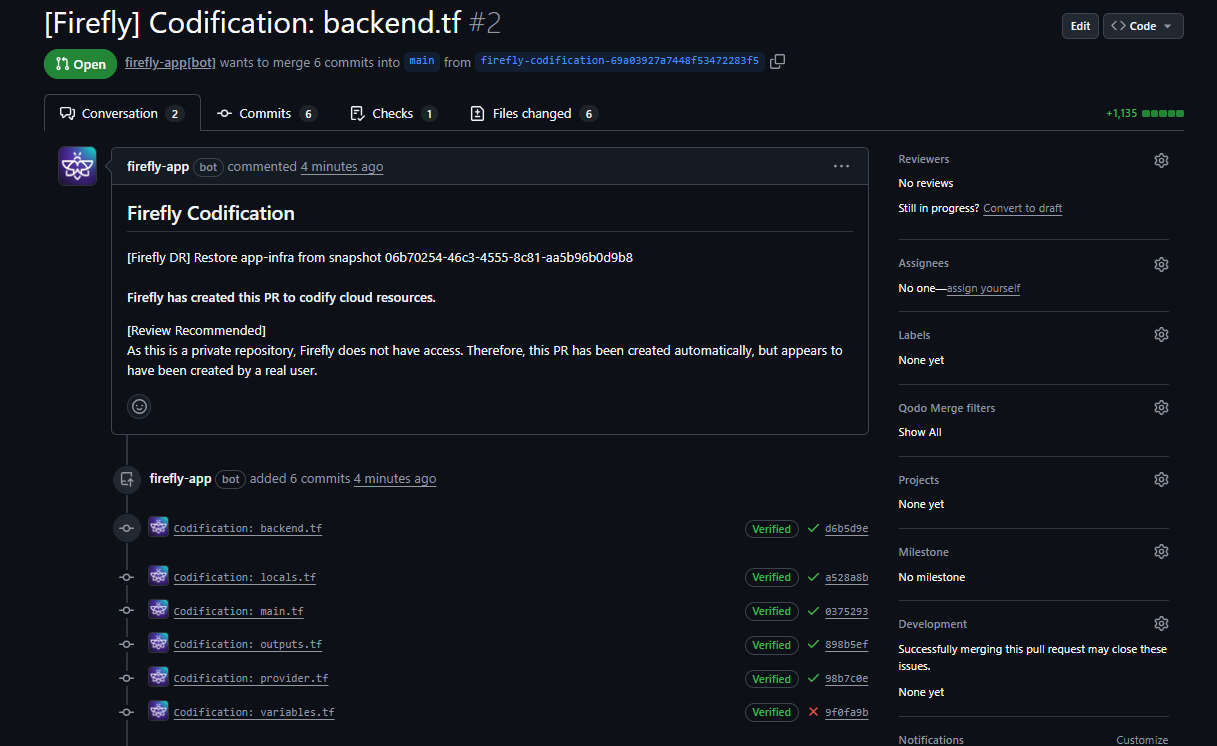
So now the recovery flow becomes:
Snapshot → Terraform generation → PR → Review → Merge → Apply
Instead of clicking restore and mutating a production account directly, you get an audit trail, versioned recovery, and review before execution. In regulated environments, that distinction matters for compliance. In any environment, it means the recovery is reproducible and documented.
The Full Recovery Sequence When AWS DR Orchestrator and Firefly Run Together
In a regional outage, the complete recovery sequence looks like this:
- AWS DR Orchestrator promotes the database replica using Step Functions
- The database becomes writable in the DR region
- Firefly selects the latest application snapshot
- Terraform is generated from the captured live state
- A PR is created and merged
- Infrastructure is applied in the DR region
- Compute services connect to the promoted database using updated endpoints
- Traffic is switched via Route 53
- Service health validated end-to-end
AWS handles database state. Firefly handles infrastructure reconstruction. CRPM ensures the prerequisites were validated before any of this was ever needed.
FAQs
What are the disaster recovery patterns AWS recommends?
AWS defines four DR patterns based on recovery speed and cost. Backup and Restore has the highest RTO but the lowest cost; you restore from backups when needed. Pilot Light keeps minimal resources running in the secondary region, scaled up during failover. Warm Standby keeps a scaled-down but fully functional version of production running in the DR region at all times. Multi-Site Active-Active runs full production capacity in multiple regions simultaneously, giving the lowest RTO. The right choice depends on your RTO and RPO requirements; tighter SLAs cost more to maintain.
What does the AWS DR Orchestrator Framework actually automate?
The framework automates database failover and failback for Amazon RDS, Aurora Global Database, and ElastiCache with Global Datastore. It uses Step Functions as the workflow engine and Lambda as the action runner. It does not provision networking, deploy compute, update DNS, reconfigure application environment variables, or validate end-to-end application functionality. It automates the database control plane, not the full recovery stack.
How do I calculate my real RTO?
Run an end-to-end recovery drill against a staging environment that mirrors your production topology. Trigger replica promotion, apply Terraform in the recovery region, and time every step, promotion, networking, compute, DNS propagation, and health check validation. Add those numbers together. The total is your RTO. If that number exceeds your SLA commitment, you have a gap to close before the next outage closes it for you.
Why does the application stay down even after the database shows as AVAILABLE?
Because AVAILABLE is an RDS status, not an application status, the database accepting connections means nothing if the ECS task environment variables still point to the old us-east-1 endpoint, if the security group in us-west-2 doesn't allow inbound traffic on port 5432 from the application subnet, or if the Secrets Manager secret in us-west-2 was never replicated and the application can't retrieve its credentials. Each of those is a separate failure that the AWS DR Orchestrator has no visibility into.
.webp)


.webp)















