
TL;DR
- count and for_each control instance creation; for expressions control data transformation. They solve different problems and should not be treated interchangeably.
- count is positional. Resource identity depends on the index, which makes it fragile when inputs change. It fits only fixed, uniform resources.
- for_each is key-based. Keys become part of the resource address, making it the correct choice for long-lived resources that represent real entities like environments or services.
- for expressions reshape input data into deterministic structures used by for_each, modules, and dynamic blocks. They do not affect the state directly.
- Dynamic blocks exist to generate repeated nested configurations required by provider schemas and should consume pre-shaped data, not embed complex logic.
- At scale, stability comes from explicit keys, simple transformations, and clear separation between data preparation and resource creation; tooling like Firefly helps enforce these patterns and maintain visibility.
Terraform is commonly used to define full environments, compute, networking, identity, and everything around them, across multiple regions and environments. In those setups, the main challenge is not whether Terraform can describe the infrastructure, but whether the configuration stays readable and predictable as the same patterns repeat with small differences. That’s where iteration enters the picture, usually later than it should.
This tends to surface when teams rely on internal modules. A module written to create a single VM works fine initially. Over time, the same module is needed for many VMs that differ only in size, OS, or disk layout. Calling the module repeatedly with slightly different inputs quickly becomes noise. Adding for_each seems like the obvious fix, but that’s where people often run into friction.
A recent Reddit thread on r/Terraform (“help using a for_each in a custom module that contains a list object”) is a good example of this problem in practice. The user had a map describing servers, including VM size, OS, and a list of disk sizes, and wanted to iterate over a custom Azure VM module. The module itself expected a list of managed disk objects. Looping the module was easy. Figuring out how that disk list fits into the loop was not.
The issue wasn’t Terraform doing something unexpected. It was a gap in understanding where iteration applies and where Terraform simply passes data through unchanged. for_each controls how many module instances exist. It does not alter the shape of inputs like lists or objects. Once that boundary is clear, patterns like looped modules with variable disk layouts become straightforward to reason about and safe to scale.
Terraform iteration primitives: instance replication vs data transformation
Terraform has multiple iteration constructs, but they solve different problems. Most confusion comes from treating them as interchangeable. They are not. Some control how many instances exist, others control how input data is shaped. Keeping that distinction clear is what prevents unstable plans and unexpected replacements.
count: index-based instance replication
count creates multiple instances of a resource or module and addresses them numerically. Instance identity is derived from position, not meaning.
Terraform tracks these instances as:
This works only as long as the order and length of var.subnet_ids remain unchanged. If a subnet ID is inserted or removed anywhere except the end of the list, all following indices shift. Terraform then treats those shifts as instance replacement, even though the intent may have been to change a single subnet.
This behavior makes count fragile for infrastructure that evolves over time. It is acceptable when:
- The list is static
- Ordering is intentional
- Replacement is not disruptive
Outside of those cases, count tends to cause unnecessary churn.
for_each: key-based instance replication
for_each creates instances based on keys rather than position. Instance identity is explicit and stable.
Terraform records these as:
As long as the keys do not change, instances remain stable even when others are added or removed. This is why for_each is the preferred mechanism for long-lived resources and module instantiation.
Key choice matters. Keys become part of the resource address. Changing a key is a destroy-and-recreate operation.
for expressions: collection transformation
for expressions do not create resources or instances. They transform collections into new values.
This produces a new map derived from the input list. No state is affected. This is how raw inputs are reshaped into forms suitable for for_each, module inputs, or provider arguments.
for expressions belong in:
- locals
- variable defaults
- outputs
- arguments passed into resources or modules
They are about data, not infrastructure.
Dynamic blocks: repeating nested configuration
When a resource requires repeated nested blocks rather than a list argument, dynamic blocks are used.
Dynamic blocks generate a nested configuration based on a collection. The collection itself is often produced by a for expression. This keeps transformation logic separate from resource structure. When loops generate repeated config, template files structure and best practices covers keeping the templates themselves clean and testable:
- count is positional and brittle
- for_each provides stable instance identity
- for expressions reshape data
- dynamic blocks emit repeated nested configuration
Using each construct for its intended purpose leads to predictable plans and infrastructure that can evolve without surprises.
count vs for_each in GCP
The previous section explained how Terraform models iteration at the language level. The next step is to look at how those constructs expand during planning and how resource addresses are recorded in the state.
The examples below use two GCP configurations that create the same number of compute instances in the same region. The only difference is the iteration mechanism. Comparing the resulting plans makes the impact on resource identity explicit.
Using count: Multiple Instances with Positional Identity
The first deployment uses count to create three compute instances.
When this configuration is planned and applied, Terraform expands the single resource definition into three instances, addressed by index:
You can see this clearly in the plan and apply output as shown below, on running terraform plan:
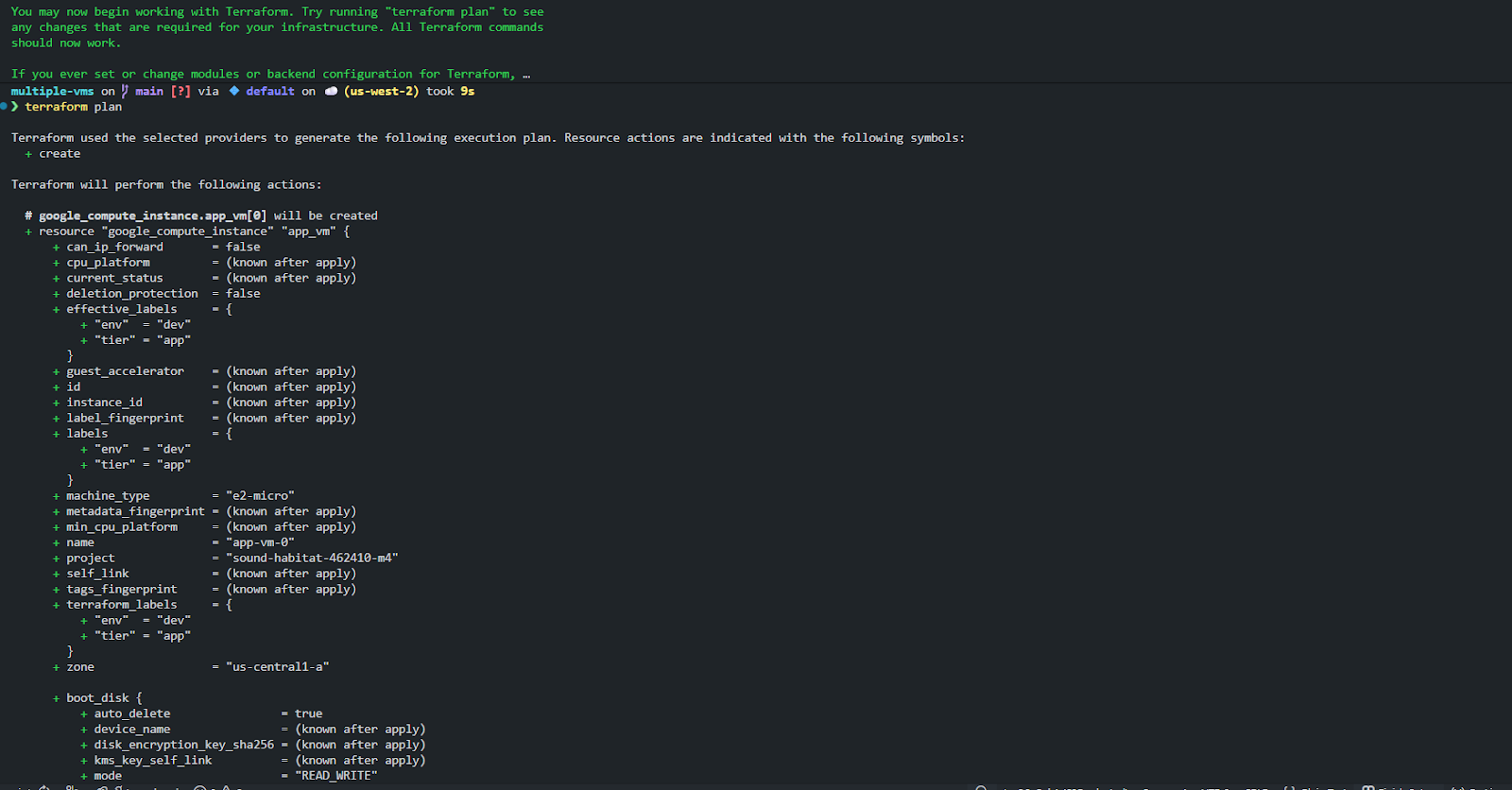
Here, Terraform explicitly shows each indexed instance being created. Each instance is identical apart from:
- the generated name (app-vm-0, app-vm-1, app-vm-2)
- the implicit index Terraform assigns
This works fine as long as:
- all instances are meant to be the same
- the total count is fixed
- ordering never changes
However, each VM's identity exists only because of its position. If you demonstrate this setup to anyone maintaining it later, there is no semantic meaning attached to [1] versus [2]. That becomes important the moment the configuration changes.
Using for_each: Instances with Explicit Identity
The second deployment uses for_each, driven by a map of environments.
Here, Terraform creates one instance per key in var.app_envs. The resource addresses now look like this:
This is visible directly in the plan output, where Terraform references each instance by environment name rather than index, as shown in the snapshot below:
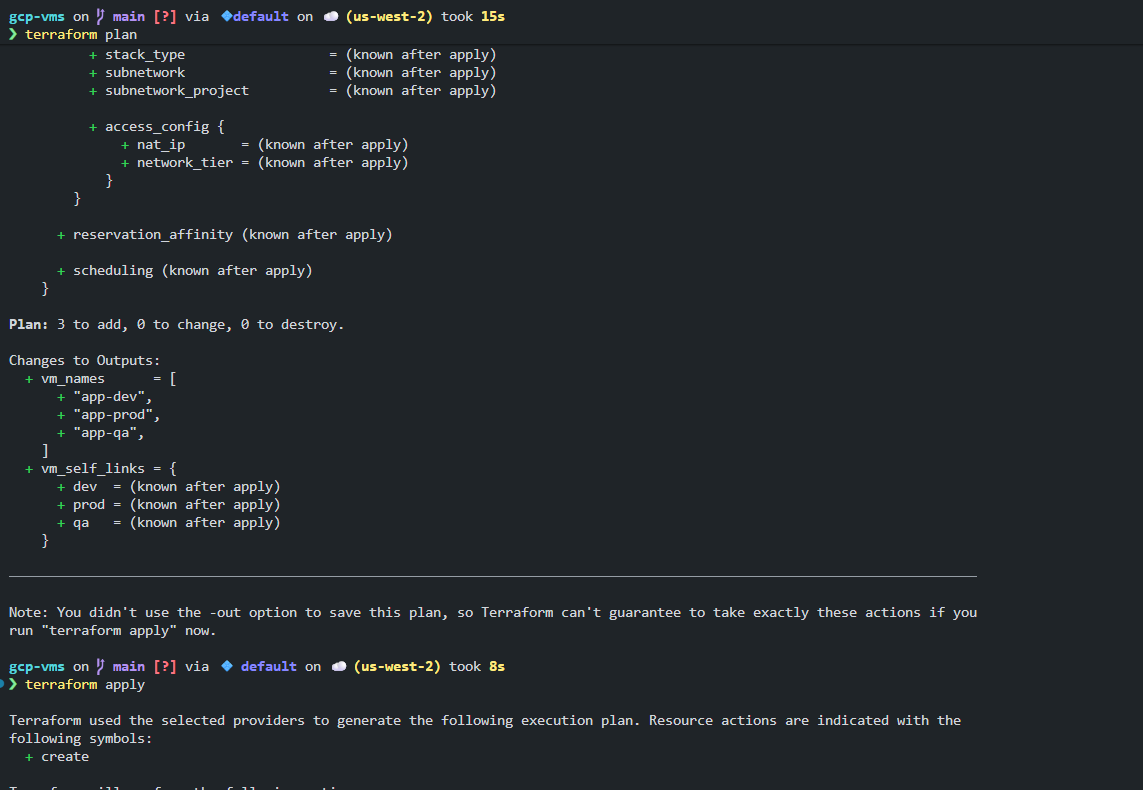
The key is now part of the resource identity. Terraform understands that:
- dev, qa, and prod are independent instances
- removing qa affects only that instance
- adding staging does not shift or replace anything else
You can also see how this clarity carries through to outputs. VM names and self-links are returned as a map keyed by environment, not as an ordered list. Here’s a visual to walk you through the a clear differentiation between count and for_each:
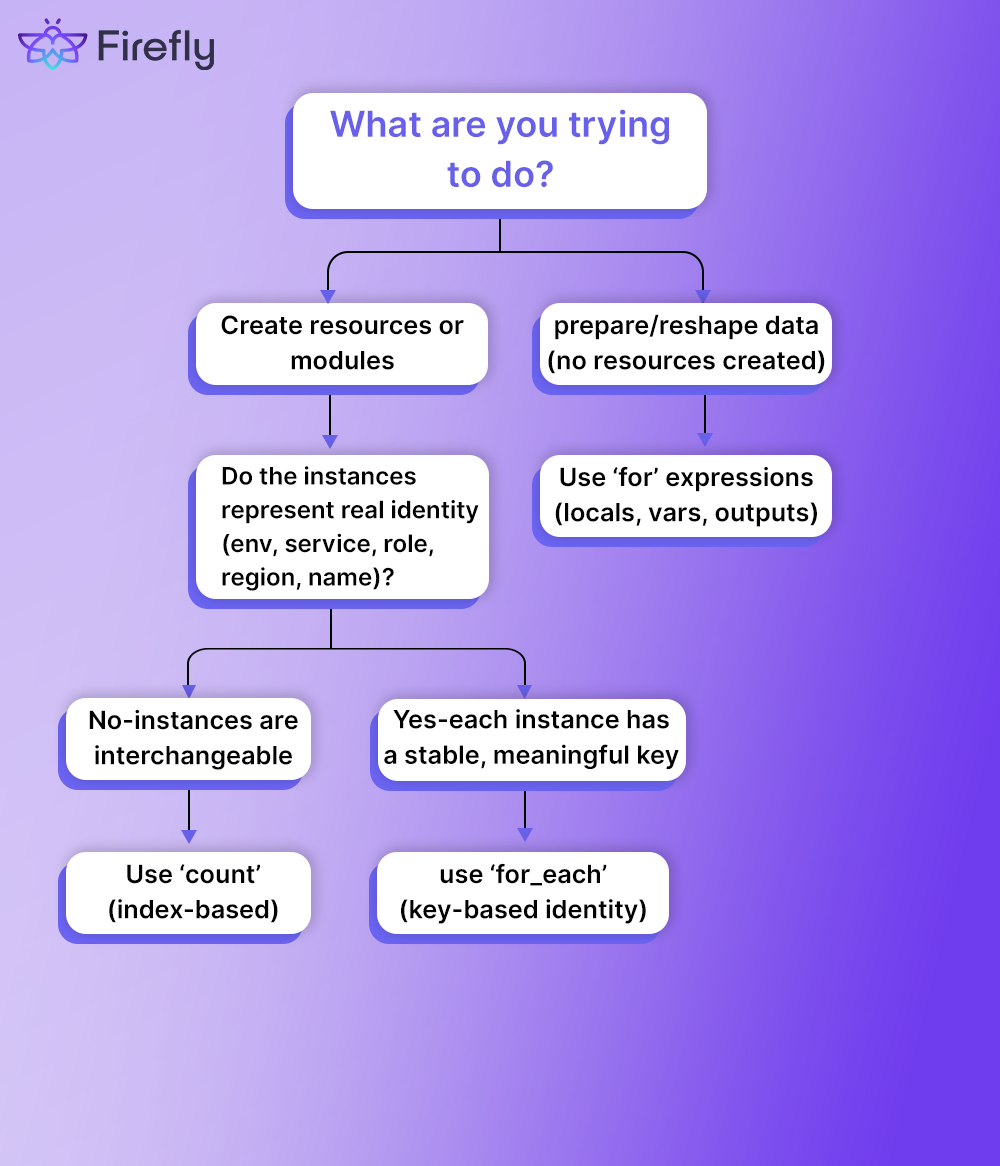
Now what changes operationally?
So both configurations create three VMs. Both plans are correct. The difference shows up when a change is introduced.
With count:
- instance identity is positional
- inserting or removing an element forces Terraform to reinterpret indices
- replacements happen even when intent is small
With for_each:
- instance identity is explicit
- changes are scoped to keys
- plans are easier to review and reason about
This is why count is usually limited to short-lived or truly uniform resources, while for_each becomes the default for anything that represents real-world entities like environments, services, or roles.
Terraform behaves exactly as designed in both cases. The difference is not correctness — it’s how identity is modeled.
- count models quantity
- for_each models identity
Once infrastructure has meaning beyond “N copies of the same thing”, identity matters. The attached plan outputs make that distinction very concrete.
Common Enterprise Use Cases for for Expressions
In larger Terraform codebases, for expressions show up far more often than count. Not because they create infrastructure, but because they allow configuration to stay data-driven. Most enterprise patterns come down to taking structured input and reshaping it into something predictable that resources and modules can consume.
Generating Multiple Similar Resources from Input Data
A common pattern is describing infrastructure as input data rather than resource blocks. Instead of defining each bucket, VM, or IAM binding directly, you define what exists and let Terraform derive how it’s created.
Here, the loop is simple. The more important part is the input shape. for expressions, usually sit one layer above this, preparing or normalizing that input so the resource block stays readable.
Multi-Region and Multi-Environment Expansion
Enterprise environments rarely scale along a single dimension. Regions and environments usually multiply together. A typical input might look like this:
A for expression can generate all valid combinations:
That flattened list can then be turned into a map for for_each:
The key point here is determinism. Keys are constructed explicitly. Ordering does not matter. Adding a new region or environment only affects the new combinations.
Normalizing Infrastructure Across Multiple Clouds
In multi-cloud setups, providers differ, but the intent is often the same: networks, compute, storage, and identity. for expressions help normalize those differences at the data layer.
That data can then drive provider aliases, module selection, or conditional logic without duplicating resource definitions per cloud.
There is a limit to how far this abstraction should go. When provider behavior diverges significantly, forcing a single loop to handle all cases often hurts readability. for expressions are best used to normalize inputs, not to hide fundamentally different infrastructure models.
Advanced for Patterns Seen in Terraform Repos
Once Terraform configurations grow beyond simple loops, patterns start to emerge that aren’t obvious from examples in isolation. These patterns usually exist to balance flexibility with state stability and readability. They work, but they need to be used deliberately.
Nested for Expressions
Nested for expressions are common when infrastructure scales across multiple dimensions: regions, environments, accounts, or tiers.
This kind of structure is justified when the data model itself is multi-dimensional. It becomes a problem when nesting is used to compensate for poorly structured inputs. Readability drops quickly with nesting. When a for expression requires more than one level, it’s usually a signal to:
- move the logic into locals
- split transformations into steps
- add comments explaining intent, not syntax
Why flatten() Becomes Necessary
Nested loops almost always produce nested lists. Terraform resources and for_each do not accept nested lists, so flatten() becomes the bridge.
The key point is that flatten() is not doing logic. It’s a correct structure. If you need more than one flatten() in a chain, the data model probably needs to be revisited.
Designing Stable Keys for for_each
Stable keys are the difference between safe iteration and accidental replacement. Lists rarely make good keys because ordering changes. Maps do, but only if the keys are chosen carefully. Good keys are:
- explicit
- human-readable
- tied to real-world identity
- unlikely to change
Keys derived from array positions, timestamps, or computed hashes tend to cause churn later. Once a resource exists in state, its key is part of its identity.
Filtering with if Conditions
for expressions can filter elements inline using if. This is useful for environment- or region-specific behavior.
Filtering works best when it’s simple and predictable. When conditions start to stack, readability drops, and reviews become harder. In those cases, it’s usually better to split the data beforehand rather than hide logic inside a single expression.
Practical Guidelines for Using Iteration Safely in Terraform
Iteration is not something to be avoided in Terraform. In larger environments, it is unavoidable. What matters is how it is applied. The following guidelines come from patterns that hold up over time, especially in configurations that change regularly.
Prefer for_each with Explicit, Stable Keys
When resources or modules are expected to live for a long time, for_each should be the default. The key used in for_each becomes part of the resource address, so it needs to represent real-world identity, not convenience.
Good keys are:
- explicit and human-readable
- tied to something external and stable (names, IDs, roles)
- unlikely to be renamed casually
Avoid keys derived from:
- list indices
- timestamps
- computed hashes
- concatenations that may change as inputs evolve
If a key change would surprise you in a plan, it’s probably the wrong key.
Keep Data Transformation and Resource Creation Separate
for expressions are for shaping data. for_each is for creating instances. Mixing the two inline makes configurations harder to read and harder to review.
A common and effective pattern is:
- use for expressions in locals to normalize and prepare input
- pass the result directly into for_each or resource arguments
This keeps resource blocks simple and makes it easier to reason about what is being created versus how the input was derived.
Keep for Expressions Boring
Readable Terraform tends to favor multiple simple transformations over one clever expression. Deeply nested for expressions with inline conditionals may work, but they are difficult to debug and review.
If an expression takes effort to mentally execute, it probably belongs in a named local with a comment explaining intent. The goal is not minimal lines of code, but clarity when someone else has to modify it months later.
Assume Inputs Will Change
Lists grow. Maps gain and lose entries. Environments split. Regions are added. Terraform configurations should be written with that in mind.
This means:
- avoiding positional assumptions
- designing keys that survive growth
- expecting that state migrations will occasionally be necessary
Iteration does not remove the need for change management. It makes that need more visible. Testing changes to loop inputs and reviewing plans carefully is part of the normal Terraform lifecycle, not an exception.
Terraform at Scale with Firefly: Codification, Visibility, and Control
Terraform is very good at declaring the desired state and converging infrastructure toward it. Where it becomes harder is everything around that core loop, understanding what already exists, bringing unmanaged resources under control, and keeping visibility as configurations become more dynamic and loop-driven. This is where additional tooling helps, not by replacing Terraform, but by supporting it in environments where scale and iteration are the default.
What Terraform Handles Well
Terraform excels at a clearly defined scope:
- declaring desired state in code
- planning changes before apply
- managing lifecycle and dependencies for resources tracked in state
Within that scope, iteration with for_each, for expressions, and dynamic blocks behaves predictably. Terraform does exactly what it is told, based on the inputs provided. What Terraform does not provide is awareness beyond its configuration and state.
Where Firefly Complements Terraform
Firefly addresses the parts of large environments that exist outside Terraform’s immediate view and helps standardize how Terraform is written and operated.
Codification engine
Firefly’s codification engine discovers existing cloud and SaaS resources and generates Terraform configurations for them, including modules and dependencies. This reduces manual HCL authoring and helps bring legacy or manually created resources into a consistent, data-driven model.
An example of this is using Firefly’s Thinkerbell to generate loop-based Terraform. Given a prompt to create multiple GCP compute instances for different environments:
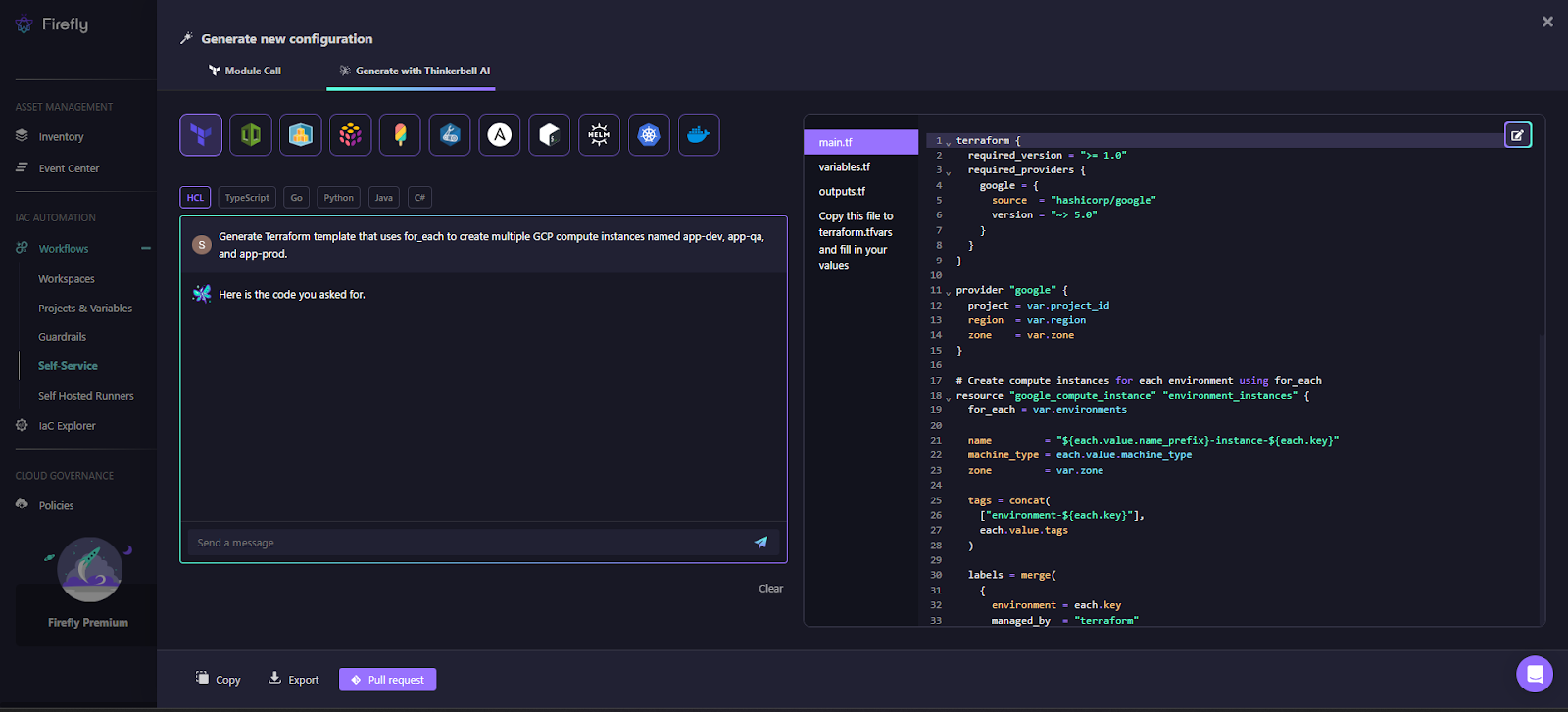
The generated configuration models environments as input data and uses for_each to create instances:
Each environment becomes a stable key, resulting in addresses like:
This approach avoids positional logic entirely. Adding or removing an environment is a data change, not a structural rewrite.
The generated configuration also keeps responsibilities cleanly separated. Instance count is controlled by for_each, while environment-specific behavior is driven by input values. Conditional behavior, such as assigning an external IP, is handled through a dynamic block:
This pattern is predictable, reviewable, and aligns with how provider schemas are designed to be used.
Continuous inventory
Firefly maintains a cross-cloud inventory of multiple IaCs. Here’s how we get all the resources listed:
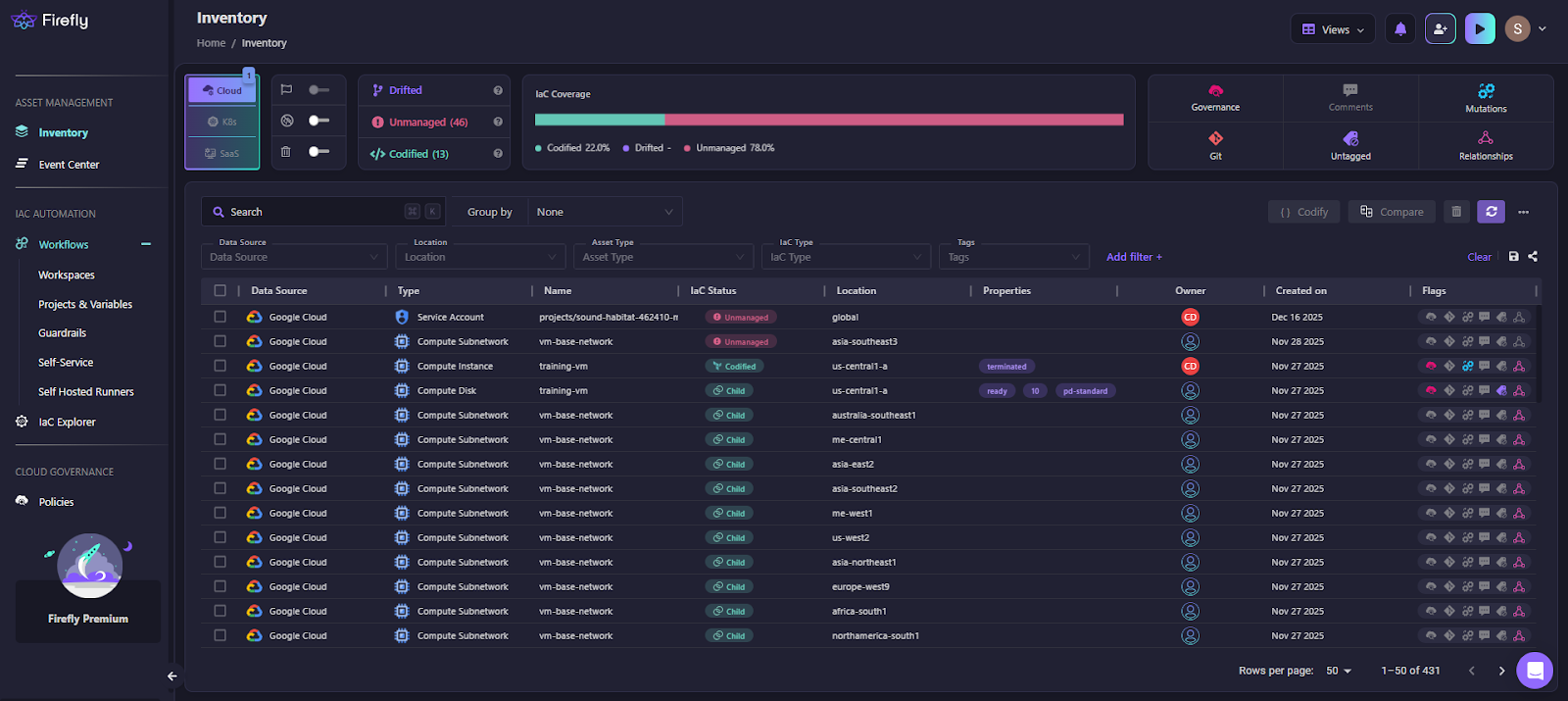
Here’s how Firefly tags all the resources after scanning the integrated clouds, where we have:
- resources managed by Terraform
- unmanaged resources
- resources that have drifted from configuration:
This visibility becomes increasingly important as loop-driven Terraform scales across environments and accounts.
Drift visibility and remediation
As configurations evolve, especially when iteration inputs change, drift can become harder to detect manually. Firefly surfaces drift explicitly and helps teams bring resources back under Terraform management without guessing what changed.
Workflow enforcement
Iteration allows infrastructure to scale quickly. Firefly helps enforce controlled workflows around planning and applying changes, including policy checks before executing Terraform apply. This becomes particularly important when a small input change expands into a large plan due to loops.
Why This Matters for Loop-Heavy Terraform
Loop-driven Terraform is efficient, but it requires strong visibility and guardrails. Firefly complements Terraform by making it easier to understand what exists, how it is managed, and how changes will propagate as iteration scales.
Used together, Terraform handles intent and execution, while Firefly helps maintain consistency and control as infrastructure grows across environments, regions, and providers.
FAQs
What is for_each in Terraform?
for_each creates multiple instances of a resource or module from a map or set. Each instance is identified by a key, and that key becomes part of the resource address in the state.
What are loops in Terraform?
Terraform uses declarative iteration constructs, not imperative loops. count and for_each create instances, while for expressions transform data.
How do you use for_each in Terraform?
Attach for_each to a resource or module and iterate over a map or set. Keys must be stable, as changing a key causes resource replacement.
What does foreach() do?
There is no foreach() function in Terraform. The term usually refers to either the for_each meta-argument or a for expression, which reshapes data but does not create resources.

.avif)
.avif)


.webp)


.webp)















