
TL;DR
- AI governance is no longer just about model reviews and compliance documentation. Effective governance spans three layers: infrastructure governance, AI program governance, and production governance.
- The five platforms reviewed take different approaches to the problem: Firefly focuses on cloud infrastructure governance, Credo AI on governance workflows and inventories, Holistic AI on governance plus enforcement, Monitaur on model risk management, and Fiddler AI on production observability and agent monitoring.
- As AI systems become cloud-native applications running on platforms such as SageMaker, Vertex AI, and Azure AI Foundry, governance increasingly includes infrastructure controls, data access, deployment guardrails, and runtime oversight, not just model behavior.
- There is no universal "best" AI governance platform. The right choice depends on the organization's primary governance gap, whether that is compliance management, model risk oversight, production monitoring, agent governance, or cloud infrastructure governance.
A thread on r/AI_Agents asked a question most enterprise teams quietly sit with: "Is anyone actually enforcing AI governance, or just writing policies?" The post drew 124 comments from engineers describing the same gap, governance programs that exist as PDFs while agents paste customer logs into ChatGPT, wire LLMs into Slack bots, and connect to internal CRM systems with no controls in place.
As the original poster put it: "A policy can say 'don't send sensitive data,' but the workflow itself doesn't know what data is sensitive, what the agent is allowed to use, or when a human should approve an action."
That gap, between a governance document and enforced runtime controls, is exactly what AI governance platforms are built to close. Governing AI in 2025 means covering three distinct layers: the cloud infrastructure where AI workloads run, the AI program layer (model inventories, risk classification, compliance workflows, and validation), and the production layer (continuous monitoring of model behavior, agent actions, and LLM response quality under live traffic).
This post covers five platforms that each govern a different part of that stack, what each one actually does, where it's strongest, and which problem it's best suited to solve.
How Do You Govern AI Systems in Production?
Discussions about AI governance focus on LLM models' specific issues, such as prompt-injection testing, toxicity and bias evaluations, hallucination benchmarking, red-team exercises, model cards, risk assessments, and sign-off workflows involving security, legal, compliance, and business stakeholders. These controls are important, but governance failures rarely originate from models alone.
A customer-facing AI application can complete every pre-deployment review and still violate governance requirements because it runs in a cloud environment with public storage, missing audit logs, overly permissive IAM roles, or no disaster recovery controls.
Likewise, an organization can continuously monitor model behavior in production while having no visibility into the AI systems individual teams are deploying. Both are governance failures.
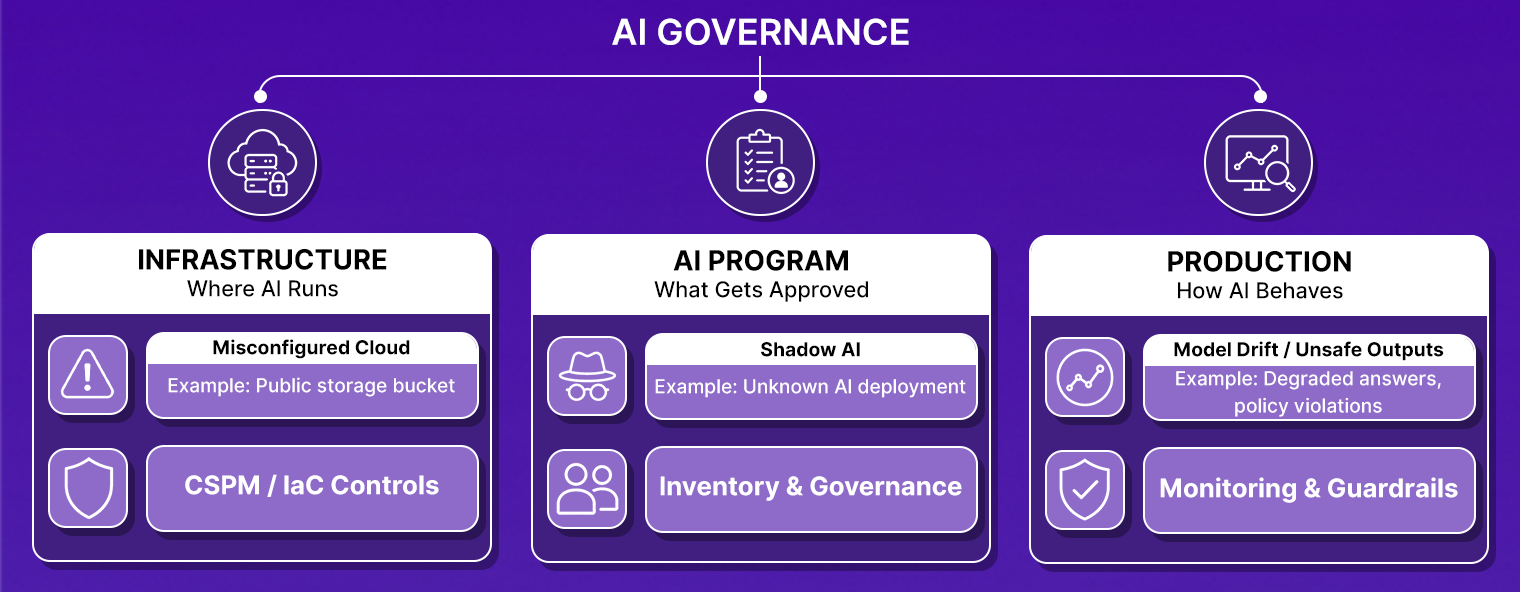
Now, AI governance spans three layers.
- Infrastructure governance focuses on the environment running AI workloads. This includes infrastructure-as-code policy enforcement, cloud configuration management, service control policies (SCPs), network segmentation, encryption controls, identity and access management, audit logging, secrets management, disaster recovery, and continuous drift detection. If the infrastructure hosting an AI system violates security or compliance requirements, the AI system itself is not governed, regardless of how thoroughly the model has been reviewed.
- AI program governance focuses on inventory, risk management, and organizational oversight. The objective is to maintain a complete record of every AI model, application, agent, and third-party AI service operating within the enterprise. This layer includes AI asset inventories, data lineage tracking, ownership assignment, use-case registration, risk classification against frameworks such as the EU AI Act, NIST AI RMF, and ISO 42001, pre-production validation, exception management, stakeholder approvals, and evidence collection for audits. The primary challenge is preventing shadow AI and ensuring governance teams know what is being deployed before it reaches production.
- Production governance focuses on how AI systems behave after deployment. Offline evaluation results rarely survive contact with real users. Input distributions shift, retrieval systems degrade, agent workflows encounter unexpected edge cases, and model outputs diverge from benchmark performance. This layer includes statistical drift detection, LLM-as-judge evaluations on production traffic, retrieval quality monitoring, agent trace analysis, root-cause investigation, runtime policy enforcement, and automated guardrails that prevent unsafe outputs or unauthorized actions.
The mistake many organizations make is treating these layers as separate initiatives. A model that passes every safety evaluation but runs in a misconfigured cloud environment creates governance risk. A well-monitored production system deployed without formal review creates governance risk. A compliant approval process that fails to detect shadow AI creates governance risk.
The AI governance platforms in this guide each address different parts of this stack. The more important question is not which platform has the most features, but which governance layer currently represents the largest operational and compliance risk.
How Do You Govern AI Workloads Running in the Cloud?
The way organizations deploy AI has changed. Most enterprise AI systems are no longer standalone models managed by a centralized data science team. They are cloud-native applications built from foundation models, vector databases, orchestration frameworks, APIs, and cloud services operating across multiple environments.
As AI workloads moved into platforms such as Amazon SageMaker, Azure AI Foundry, Vertex AI, and Databricks, governance expanded beyond model evaluations and documentation. The infrastructure hosting those workloads became part of the governance scope.
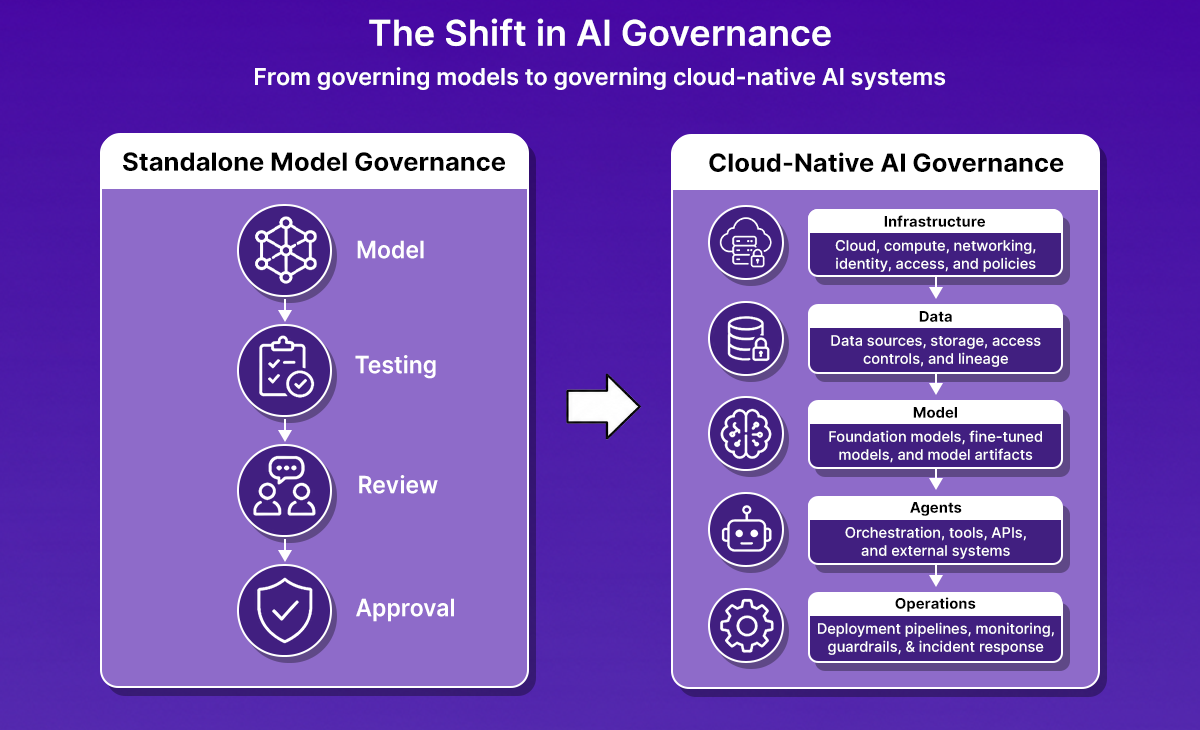
Consider two common enterprise requirements.
The first is a security requirement: AI workloads must use encrypted storage for training data, model artifacts, and attached volumes. The second is an operational requirement: inference endpoints must be deployed only on approved instance families that align with organizational standards for cost, performance, or platform operations.
In AWS environments, these requirements are often implemented through Service Control Policies (SCPs). One policy can deny the creation of SageMaker notebook instances or training jobs unless a KMS encryption key is specified. Another can restrict SageMaker endpoint deployments to approved instance families such as Graviton-based instances.
Neither policy evaluates model accuracy, bias, toxicity, or hallucination rates. Both are governance controls because they enforce organizational requirements on how AI systems are deployed and operated.
This pattern appears across modern AI environments. Governance controls increasingly span IAM policies, SCPs, Kubernetes admission controllers, infrastructure-as-code policy frameworks, network controls, data access controls, logging requirements, and deployment pipelines. The governance boundary extends beyond the model to include the infrastructure, services, and operational processes that support it.
This shift is a consequence of how AI systems are built today. A customer support copilot might combine a foundation model, a vector database, multiple APIs, enterprise data sources, and cloud infrastructure managed by different teams. An agent may interact with CRM systems, ticketing platforms, internal databases, and external services during a single execution.
As a result, governance questions increasingly extend beyond model behavior:
- What infrastructure is hosting the workload?
- Which identities and roles can access it?
- What data sources can it retrieve from?
- What actions can agents perform?
- Which deployment controls are enforced before production rollout?
- How is compliance evidence collected and retained?
These questions sit at the intersection of AI, cloud infrastructure, security, and platform engineering. That is why many modern AI governance platforms have evolved beyond model registries and compliance workflows. The most mature platforms provide visibility and control across the broader AI stack, including infrastructure, data access, deployment processes, runtime operations, and model behavior.
The challenge is that AI governance is not a single product category. A platform designed for regulatory workflows may offer limited production observability. A runtime monitoring platform may provide little support for infrastructure governance. Cloud-native governance tools often solve a different set of problems than platforms built around model risk management.
That makes platform selection less about finding the "best" vendor and more about identifying the governance gap that needs to be addressed.
The six platforms below represent different approaches to AI governance, spanning infrastructure governance, AI program governance, and production governance.
The 5 Leading AI Governance Platforms
.png)
1. Firefly AI
Firefly AI is a cloud infrastructure automation and governance platform for DevOps and platform engineering teams managing multi-cloud estates. Unlike the other four platforms on this list, Firefly governs infrastructure configurations, IaC deployments, and cloud operations, not AI models or LLM outputs. Its Thinkerbell AI agents automate remediation within those infrastructure boundaries. Gartner recognized Firefly in the 2025 Hype Cycle for Backup and Data Protection Technologies under Cloud Application Infrastructure Recovery Solutions (CAIRS). Customers include Paramount, HPE, Cisco, and Carnival Cruise Lines.
Key Features
- Cloud asset inventory: Unified real-time registry of every resource across AWS, Azure, GCP, Kubernetes, and SaaS; every configuration change and drift event is captured automatically, not at the next scheduled scan
- Continuous compliance scanning: Evaluates infrastructure against 600+ policies covering SOC 2, PCI DSS, HIPAA, ISO 27001, NIST, and DORA; violations are flagged immediately with context on the specific resource and policy breached
- IaC governance with GitOps: Every Terraform, OpenTofu, Pulumi, CloudFormation, and Crossplane deployment is validated against governance policy before it reaches production, blocking non-compliant changes at the PR stage using guardrails.
- Thinkerbell AI agents: Operate with full context of the infrastructure estate; detect drift, generate IaC fix PRs, execute CLI-based remediation, and rebuild environments during incidents, subject to configurable human approval gates
- Disaster recovery codification: Full environment state captured in IaC so infrastructure can be rebuilt from code after a cloud intrusion or catastrophic misconfiguration, without manually reconstructing resource configurations from memory
For Platform Engineering Teams Managing AI Workloads
DevOps and platform engineering teams in organizations subject to continuous compliance requirements (SOC 2, PCI DSS, HIPAA), managing multi-cloud or hybrid infrastructure estates, where manual policy enforcement creates audit gaps and delayed remediation.
Hands On: Evaluating 533 Live AWS Policy Violations and Blocking Default VPC Deployments Before Any Resource Is Created
AI governance platforms focus on model inventories, risk assessments, and compliance workflows. Firefly approaches governance from the infrastructure layer, focusing on the cloud environments where AI systems run.
As organizations deploy AI workloads through services such as Amazon SageMaker, Vertex AI, Azure AI Foundry, and Kubernetes, infrastructure misconfigurations become governance issues. Public storage, overly permissive IAM roles, missing audit logs, and weak network controls can create compliance and security risks regardless of how thoroughly a model has been evaluated.
When an AWS account is connected, Firefly evaluates it against 533 built-in policies spanning CIS, SOC 2, HIPAA, PCI DSS, NIST, resiliency, and cloud governance standards.
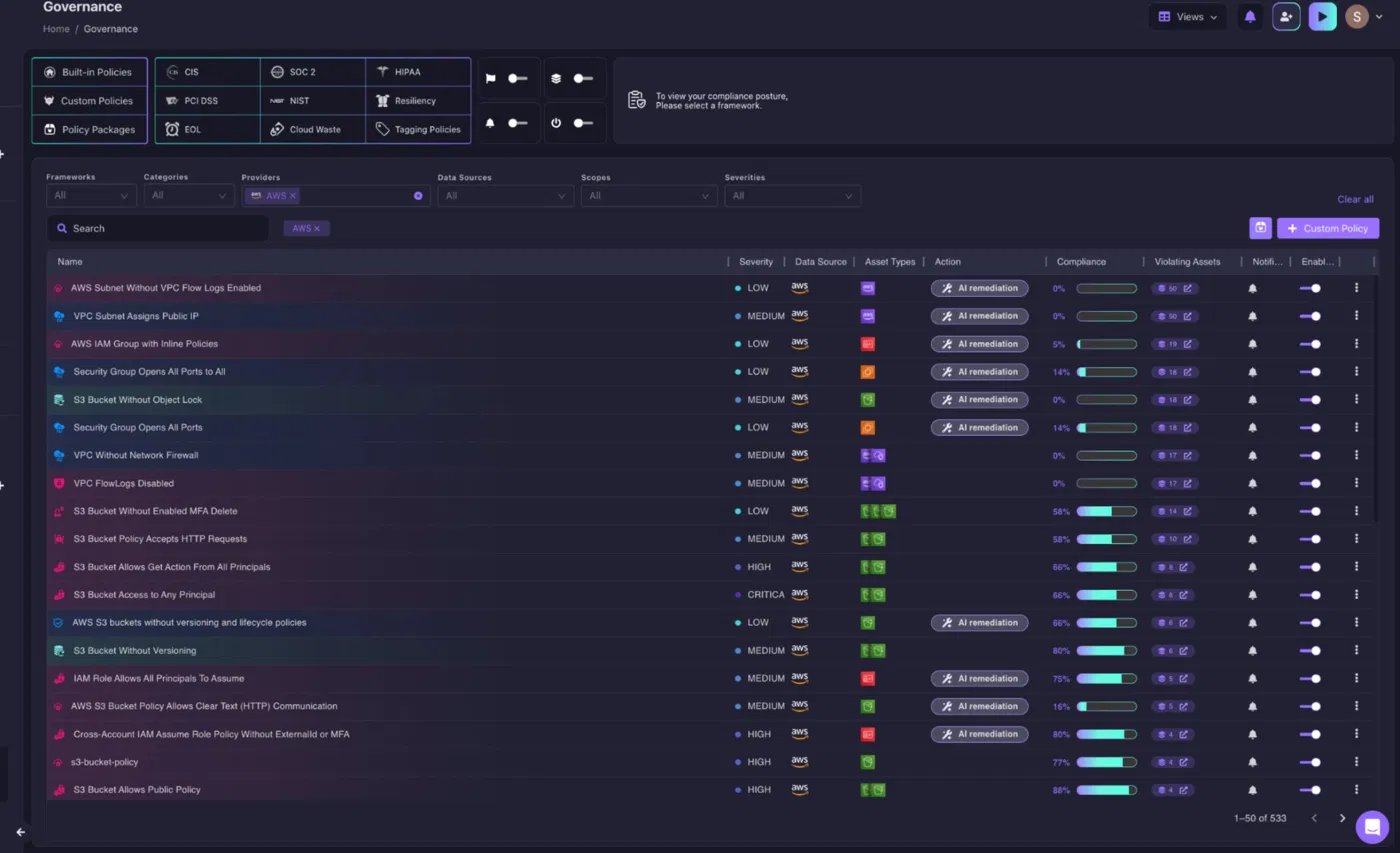
In the dashboard above, Firefly identifies findings such as subnets without VPC Flow Logs, buckets accessible to any principal, overly permissive IAM roles, and unrestricted security groups. For many findings, the platform can generate AI-assisted remediation recommendations, Terraform changes, or targeted AWS commands.
Training datasets, model artifacts, vector databases, inference endpoints, and agent workflows all rely on the same storage, networking, and identity layers represented in the dashboard. As a result, governance of AI systems extends beyond the model itself to include the environments where those systems are trained, deployed, and operated.
Firefly helps teams identify these infrastructure risks and provides AI-assisted remediation guidance, Terraform changes, or targeted AWS commands for many findings, allowing governance issues to be addressed before they affect production workloads.
Enforcing Governance Controls for SageMaker Deployments
Detection is only one part of governance. Firefly's Preventive Controls module allows organizations to enforce requirements before AI infrastructure is provisioned.
.png)
In the example above, a Service Control Policy (SCP) named DenyNonGravitonSageMaker prevents SageMaker endpoint configurations from being created unless they use approved Graviton-based instance families. Similar controls can enforce SageMaker encryption, approved AWS regions, networking standards, and other deployment requirements.
Firefly generates the policy in AWS SCP JSON, Terraform, CloudFormation, and AWS CDK while validating it through its Policy Insights engine before deployment.
This is what makes Firefly relevant in an AI governance discussion. Rather than governing model behavior, it governs the infrastructure, permissions, and deployment controls that AI systems depend on. For organizations running AI workloads in AWS, that infrastructure layer is often where governance requirements are ultimately enforced.
Pros
- 600+ pre-built compliance policies remove the policy authoring overhead that stalls most infrastructure governance programs at the start
- Thinkerbell agents reduce time-to-remediation from days to minutes by generating IaC fixes in the tool stack teams already use (Terraform, Pulumi, etc.)
- GitOps-native enforcement means governance runs at the PR level, not as a post-deployment audit.
Cons
- Governs infrastructure configurations, not AI model behavior, LLM outputs, or agent actions at the application layer; a second platform is required for AI model governance
- IaC-first approach requires an established IaC practice; teams still relying heavily on ClickOps will need to codify infrastructure before most governance controls become enforceable
2. Credo AI
Credo AI is an AI governance platform built around policy management, AI inventories, and compliance workflow automation. Forrester named Credo AI a Leader in the AI Governance Solutions Wave, Q3 2025, with the highest possible scores in 12 criteria, including AI policy management, regulatory compliance audit, and testing workflows, and the highest enterprise adoption rate in the category. Gartner recognized Credo AI as a Representative Vendor in the 2025 Market Guide for AI Governance Platforms.
Key Features
- AI knowledge graph: Maps every model, agent, application, and dataset to the policies, stakeholders, and risk controls governing them, giving compliance teams a queryable record of the entire AI estate
- Governance AI agents: Automated agents retrieve evidence across systems, assess risk against internal policies, generate governance plans, and flag incidents for human review
- Shadow AI discovery: Scans for AI tools operating in production without formal registration, surfacing deployments that business units launched without notifying the governance function
- Compliance framework mapping: Direct mapping of AI systems to EU AI Act, NIST AI RMF, and ISO 42001 controls with automated evidence package generation for regulatory audits
- Azure integration: Governance checkpoints embedded into the Azure AI development lifecycle, so data science teams encounter governance requirements without switching tools
Best For
GRC teams, CAIOs, and CISOs at large enterprises in financial services, healthcare, life sciences, and manufacturing are formalizing AI governance programs and need a single system of record for policy management, AI inventory, and audit evidence.
Pros
- Highest enterprise adoption rate in the category per Forrester Q3 2025
- Shadow AI discovery addresses the most common governance blind spot in large organizations, where business units deploy tools independently
- Governance AI agents compress multi-week evidence collection cycles, the primary bottleneck in manual compliance programs
Cons
- Adversarial red teaming, automated fairness evaluation across population segments, and LLM security testing are not core strengths; deep pre-deployment technical validation requires a complementary tool.
- Governance workflow depth is calibrated for enterprises building formal programs; smaller teams or early-stage governance maturity may not need the full platform.
Hands On: Registering the Cursor AI Agent Against Claude Opus 4.1, Clearing Intake, and Routing to Governance Review
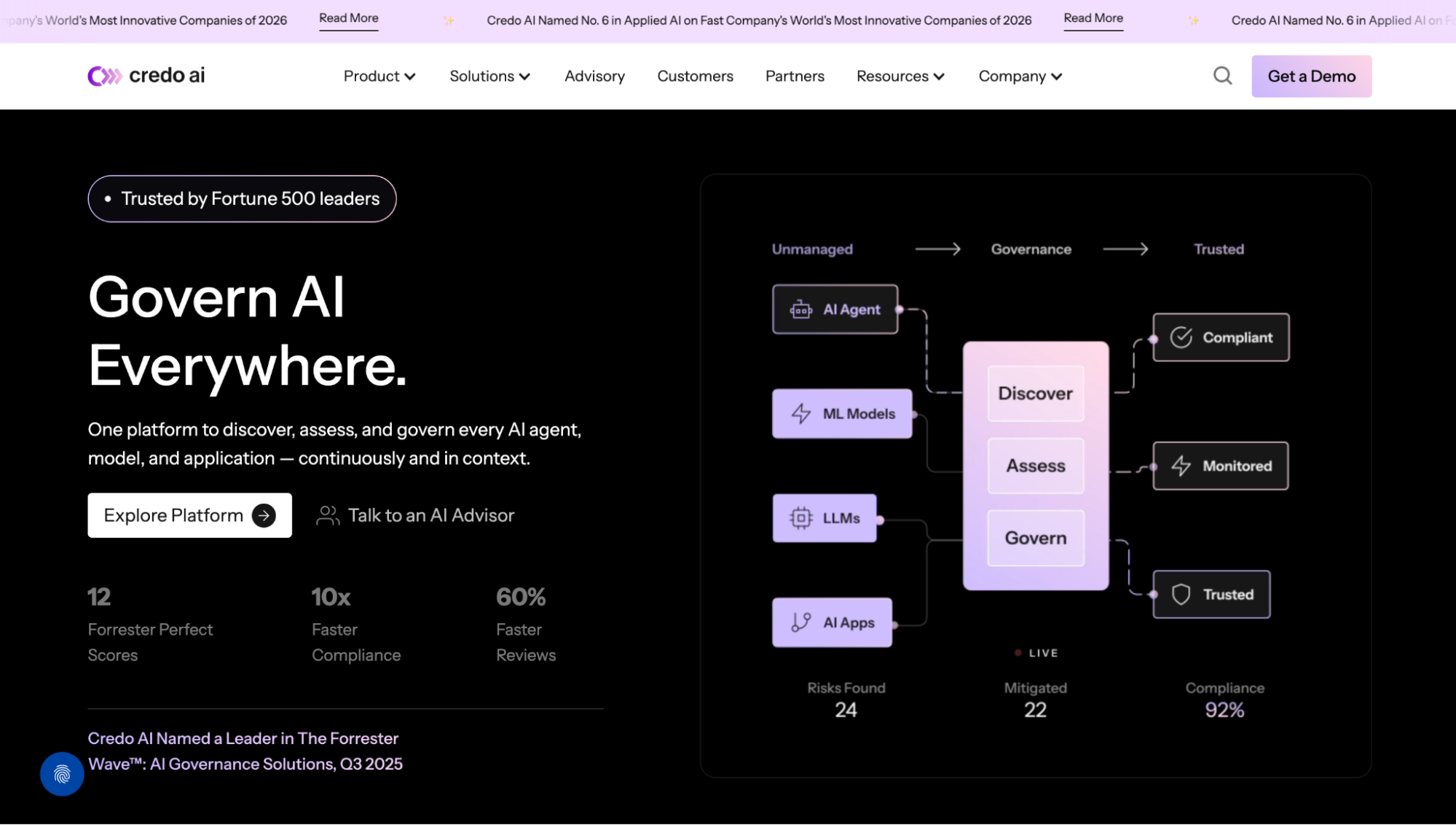
Credo AI registers every AI system, such as a model, application, or agent, as a use case record in the AI registry. The record below is for "Cursor Agent" (UC-1104): an AI coding agent running Claude Opus 4.1 through the Cursor IDE inside developer environments. Coding agents like this one have write access to codebases, can suggest and execute commands depending on configuration, and involve two separate vendors (Cursor as the IDE, Anthropic as the model provider), each with its own compliance posture that governance teams need to track independently.
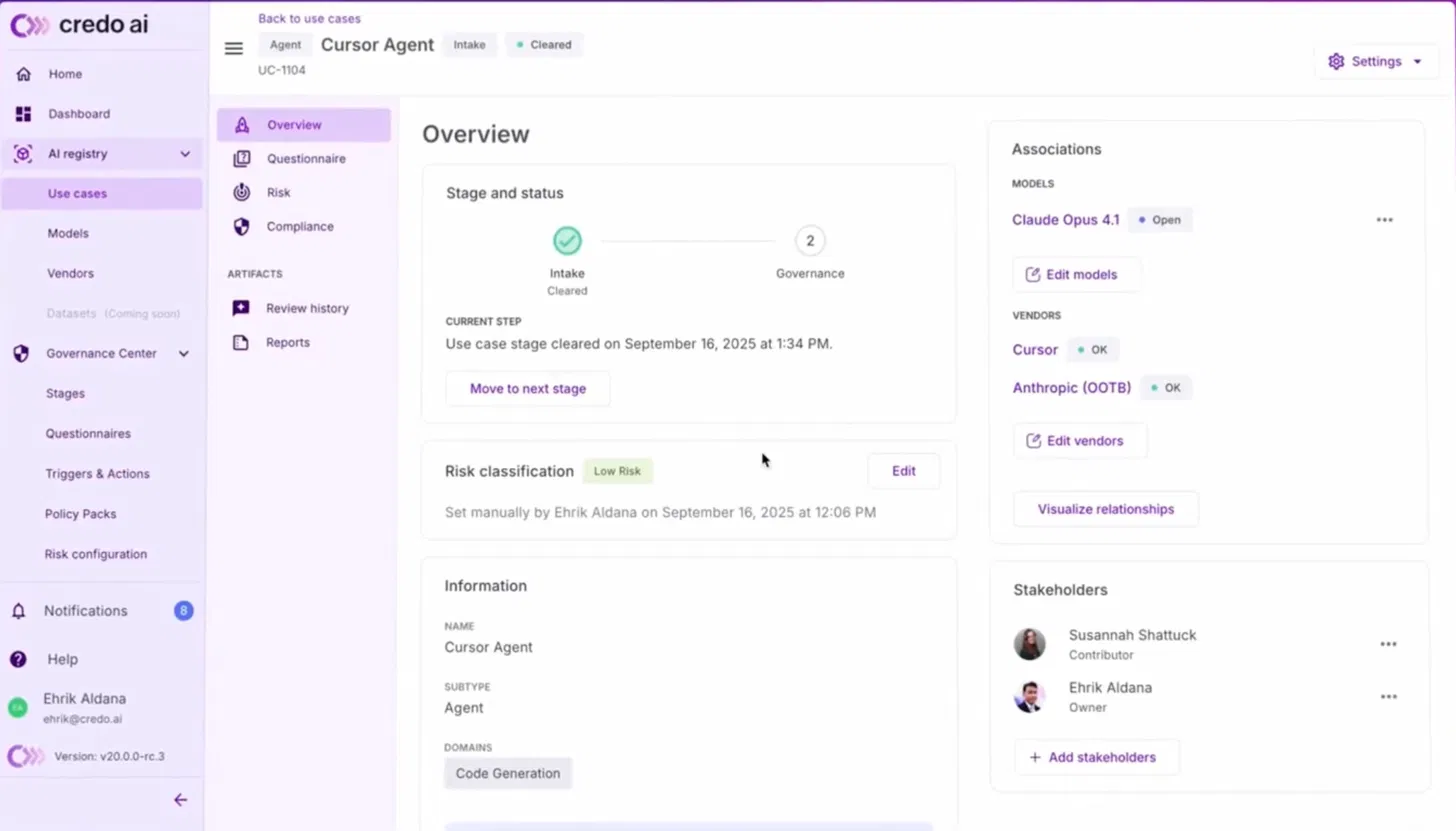
The stage pipeline shows two checkpoints: Intake (cleared September 16, 2025, at 1:34 PM) and Governance (pending, step 2). Intake clearance is timestamped with the exact moment of clearance, the kind of record that answers an auditor's question about when a system first passed governance review. Risk classification sits at Low Risk, set manually by Ehrik Aldana at 12:06 PM the same day.
That timestamp and name create an auditable record of who assessed the risk and when, distinct from who owns the system. The right panel links three types of associations: the model (Claude Opus 4.1, status Open, indicating it is registered but not yet in an approved production state), the vendors (Cursor and Anthropic OOTB, both status OK), and the stakeholders (Ehrik Aldana as Owner, Susannah Shattuck as Contributor).
Every one of these associations is a node in Credo AI's knowledge graph; the "Visualize relationships" button renders the full graph of connections between this agent, its model, its vendors, its policies, and the stakeholders responsible for each. When Credo AI's governance agents run evidence collection for a compliance audit, they traverse this graph to pull every associated record automatically rather than requiring a team member to locate each artifact manually.
3. Holistic AI
Holistic AI combines governance program management with continuous technical testing and real-time enforcement of governance controls in production. IDC's Product Scape for Worldwide AI Governance Platforms 2025 describes it as a platform that "oversees the entire life cycle of generative AI models, addressing governance concerns such as bias, security, and compliance." The platform integrates with Microsoft and PwC, and offers on-premises deployment for regulated industries.
Key Features
- Automated AI discovery: Read-only integrations scan cloud, code, and enterprise platforms to identify AI systems without requiring agents or modifying existing infrastructure
- Continuous bias and security testing: Adversarial simulations, fairness evaluations, and security checks run before and after deployment; results feed directly into compliance evidence records
- Guardian Agents: Autonomous supervisory agents observe AI agent behavior in production, evaluate each action against defined risk thresholds, and trigger kill switches when behavior crosses approved boundaries
- Deployment gates: AI systems are blocked from reaching production until specified governance checks pass; gate requirements are configurable per EU AI Act risk tier (unacceptable/high/limited/minimal)
- NYC Local Law 144 and EU AI Act compliance: Control mapping and continuous audit trail generation for hiring AI (LL 144 bias audits) and EU high-risk AI systems
Best For
Enterprises deploying customer-facing AI in regulated sectors, hiring tools subject to NYC Local Law 144, insurance decision models under EU AI Act high-risk classification, and healthcare applications with patient-facing outputs, where a single platform covering governance workflows and runtime enforcement avoids the integration overhead of assembling two separate tools.
Pros
- Guardian Agents close the gap between policy documents and runtime enforcement without requiring manual intervention for every agent action.
- NYC Local Law 144 support is a differentiator for US organizations running automated hiring or screening tools
- On-premises deployment for regulated industries with strict data residency requirements
Cons
- Teams whose primary need is approval routing and stakeholder sign-off workflows may find the governance workflow tooling secondary to the technical enforcement capabilities.
- Continuous testing adds operational overhead for teams without dedicated AI assurance resources.
Hands On: Reconciling 5 Unregistered Shadow AI Systems, Tracking 2 High-Risk Assets to Zero Residual Risk, and Investigating 35 Failed Governance Tasks
Holistic AI's read-only integrations, scanning Azure subscriptions, Databricks environments, and connected cloud accounts, discovered 18 formally registered AI assets and 5 additional systems operating in production that no one has registered. Those 5 appear in the Shadow AI counter as "pending reconciliation": each one requires a governance team member to either register it through the standard intake workflow or explicitly mark it as non-applicable. Until reconciled, each is an ungoverned system in production with no risk classification, no assigned owner, and no compliance record.
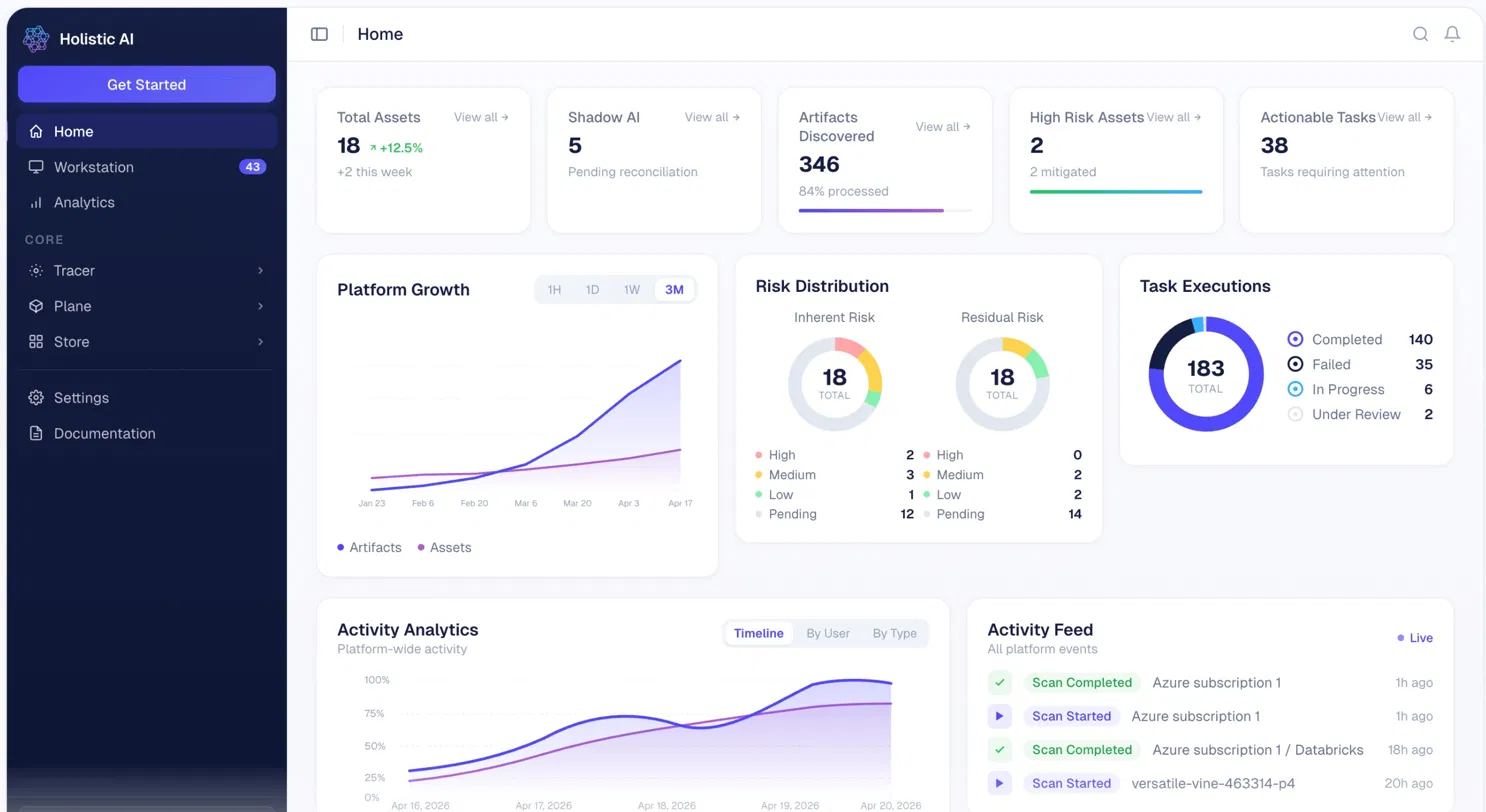
The Risk Distribution panel tells the governance program's effectiveness story in two numbers. Inherent risk, the initial assessment before mitigations, registers 2 High, 3 Medium, 1 Low, and 12 Pending. Residual risk, after mitigations have been submitted, reviewed, and accepted, registers 0 High, 2 Medium, 2 Low, and 14 Pending.
The two High-risk assets have accepted mitigations on file, bringing their effective risk tier down to zero at the High level. That is the governance program producing a measurable, auditable result: specific mitigations were proposed, reviewed against the platform's controls, and accepted. The Task Executions widget breaks 183 total governance tasks into 140 completed, 35 failed, and 6 in progress.
35 failed tasks are in the daily triage queue; each failure means a governance automation (a scan, a test, a control check) did not complete, and each failed task rolls into the 38 Actionable Tasks counter at the top. The Activity Feed at the bottom right confirms that discovery is running continuously: Azure subscription 1 completed a scan 1 hour ago; a Databricks environment scan completed 18 hours ago. The asset count, shadow AI queue, and risk distribution all update from these ongoing scans rather than from a weekly or monthly batch cycle.
4. Monitaur
Monitaur is an AI governance platform built for regulated industries, financial services, insurance, and healthcare that operate formal model risk management programs. The platform is organized around a policy-to-proof methodology: every governance activity produces documented evidence designed to survive regulatory examination. Gartner named Monitaur a Representative Vendor in the 2025 Market Guide for AI Trust, Risk, and Security Management. Forrester named it a Strong Performer and Customer Favorite in the AI Governance Solutions Wave, Q3 2025.
Key Features
- Guided Risk Assessment runs every AI use case through a configurable risk methodology aligned to the organization's own policies; routes high-risk systems to governance committee review and handles lower-risk systems automatically, reducing committee bottlenecks.
- FlightSim pre-deployment evaluation, Synthetic simulation layer that runs models against representative scenarios before production release, producing letter grades and specific remediation recommendations per model
- Common Controls Library, 33 pre-built controls for high-risk models that automatically generate 40% of required governance evidence at deployment without manual documentation
- Evidence mapping captures validation results and approval decisions from existing tools already in use and maps them to governance controls, reducing the documentation overhead of switching to a new system.
- Vendor governance, Centralized inventory, and pre-mapped controls for third-party foundation models and agentic AI, so vendor AI is governed to the same standard as internally built models.
Best For
Banks, insurance providers, and healthcare organizations running formal MRM programs that need to extend those programs to GenAI and agentic AI, where governance evidence must satisfy a regulator with examination authority, not just pass an internal audit.
Pros
- FlightSim letter grades give governance committees a concrete pass/fail signal before production, replacing subjective review with scored validation results.
- Vendor governance with pre-mapped controls for foundation models closes the MRM coverage gap created by third-party GenAI adoption.
- Policy-to-proof methodology aligns directly with SR 11-7 and OCC model risk management expectations in US banking.
Cons
- Runtime monitoring of agent behavior and hierarchical root cause analysis for multi-agent failures are not core strengths; production observability requires a complementary tool.
- Governance depth is calibrated for formal MRM programs; organizations outside financial services, insurance, and healthcare may find the compliance rigor more than their regulatory context requires
Hands On: 791 Pre-Production Controls, 15 Failures Blocking Deployment, and Why GPT 3.5 Cannot Move to Production
Monitaur's governance model is built around the principle that more controls are verified before a model enters production than while it is running in production, because the cost of catching a compliance failure before go-live is lower than catching it during a regulatory examination after.
The Governance Overview below makes the current state of that verification pipeline visible across all active projects.
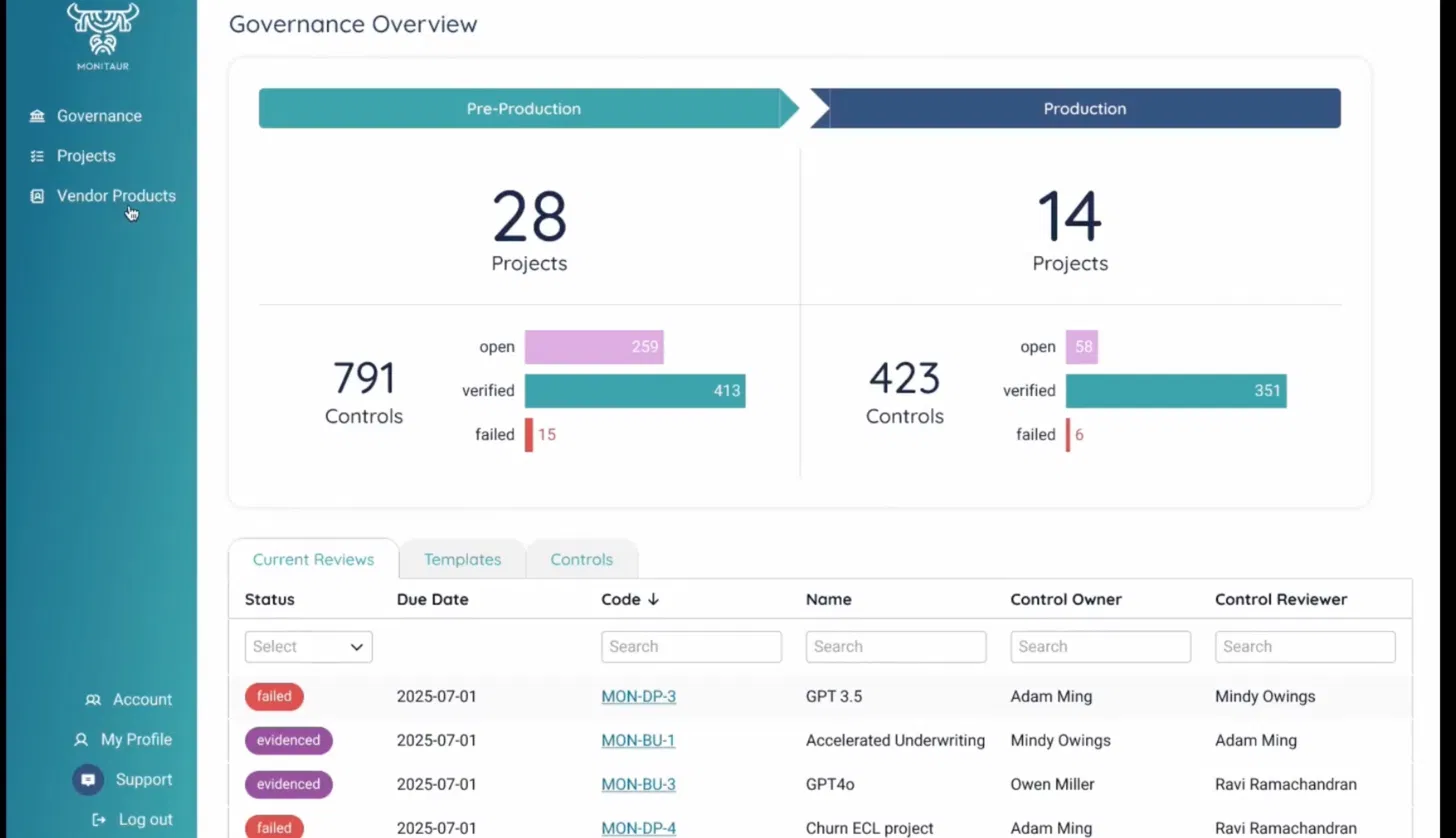
Pre-Production carries 28 projects and 791 controls. Of those, 413 are verified (evidence submitted and accepted by a reviewer), 259 are open (assigned but evidence not yet submitted), and 15 have failed; a reviewer assessed the submitted evidence as insufficient, and the associated models are blocked from advancing until the control owner submits acceptable remediation.
Production carries 14 projects and 423 controls, with 351 verified, 58 open, and 6 failed. The Current Reviews table makes the specific failures concrete. GPT 3.5, tracked under code MON-DP-3 (DP denoting a data processing use case classification), carries a failed status with a July 1, 2025, due date. Adam Ming owns the remediation; Mindy Owings is the reviewer. GPT 3.5 stays in pre-production until Adam Ming submits satisfactory remediation evidence and Mindy Owings accepts it, no manual override, no informal approval.
By contrast, Accelerated Underwriting (MON-BU-1) and GPT4o (MON-BU-3) are marked, meaning both systems have cleared their current review cycle and are advancing through the pipeline. Vendor Products in the left navigation sits alongside Governance and Projects as a primary object, confirming that externally purchased models like GPT 3.5 and GPT4o go through the same pre-production control verification as internally built models, rather than a lighter review track.
5. Fiddler AI
Fiddler AI is an AI observability and security platform focused on production monitoring of ML models, LLM applications, and AI agents. CB Insights named Fiddler a Leader in the AI Agent Security and Risk Management Market and included it in the CB Insights AI 100 for 2025. Gartner named Fiddler in the Market Guide for AI Evaluation and Observability Platforms. The Defense Innovation Unit issued a formal success memo for the platform. The U.S. Navy reduced ML model retraining time by 97% using Fiddler.
Key Features
- Production monitoring: Tracks 50+ LLM metrics and 30 ML metrics in real time: data drift via distribution comparison between training and production inputs, hallucination rates via LLM-as-judge scoring, toxicity levels, PII exposure, and prompt injection detection
- Fiddler Guardrails: Low-latency Trust Model scoring blocks, prompts, and responses exceeding configured safety, toxicity, or policy thresholds before they reach users
- Agent observability: Monitors multi-agent interactions, tracks tool call sequences and coordination patterns across agents, and surfaces cascading failures where one agent's incorrect output propagates through downstream agents
- Hierarchical root cause analysis: Drills from an application-level alert to the specific agent span, tool call, and parameter set that produced a failure in a multi-agent workflow
- Automated audit evidence: Generates compliance documentation from live monitoring data, hallucination rates, safety violation frequencies, and drift metrics, mapped to regulatory reporting requirements
Best For
AI platform and MLOps teams running large-scale LLM and ML workloads in production where pre-deployment evaluation scores diverge from production behavior, and engineering teams building multi-agent systems that need root cause tracing rather than alert dashboards.
Pros
- Hierarchical root cause analysis for multi-agent failures is the most technically specific agent tracing capability in the category. Teams can pinpoint which tool call caused a downstream failure, not just that a failure occurred
- 50+ LLM metrics out of the box means teams spend time analyzing results, not building evaluation pipelines
- Native integrations with AWS SageMaker AI, Amazon Bedrock, and NVIDIA NeMo Guardrails cover the most common enterprise LLM deployment stacks
Cons
- Governance program management, policy definition, stakeholder approval workflows, and risk classification frameworks are not core capabilities; most teams pair Fiddler with a governance workflow platform.
- Pre-deployment MRM-style validation and regulatory evidence collection are handled upstream; Fiddler picks up at the point of production deployment.
Hands On: Diagnosing a 0.11 Faithfulness Score Across 56k RAG Chatbot Requests Using Per-Span Traffic Breakdowns
Over 30 days, "DemoAgenticChatbot" processed 56.96k requests. The OpenAI model generated 11.94k LLM spans, each span is one discrete model call within the agentic pipeline. The application executed 6.68k tool calls, split between two tool types: RAG over a database and URL validation. The number that signals a production problem is the Average Faithfulness Score: 0.11.
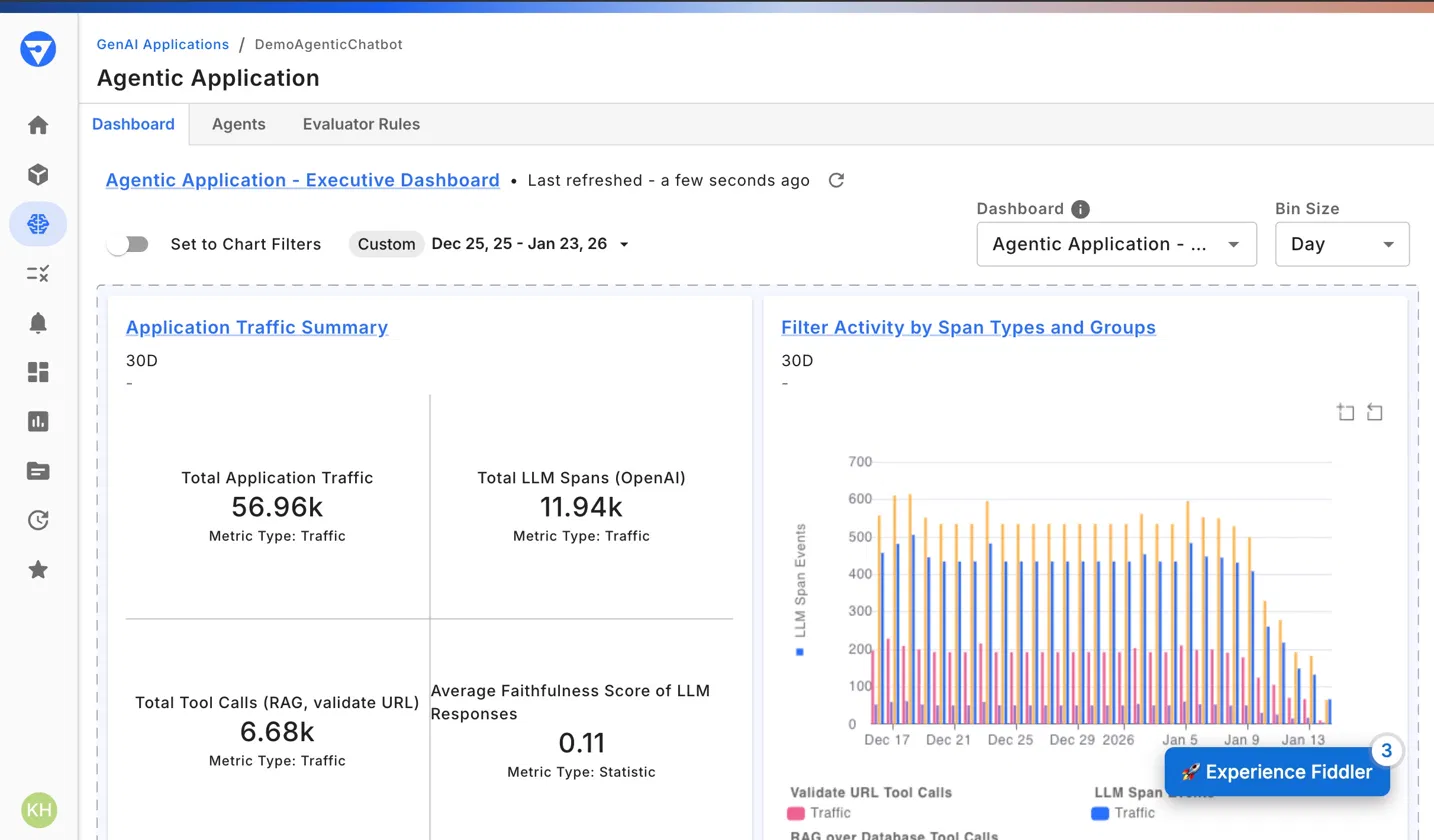
A faithfulness score of 0.11 on a 0–1 scale means LLM responses are almost entirely unanchored from retrieved source content. The RAG pipeline is executing, 6.68k database lookups confirm retrieval is running, but the model is generating answers from parametric memory rather than the documents retrieved. For an enterprise chatbot where users expect responses sourced from internal knowledge bases, a score of 0.11 means 89% of answers could contradict or ignore the actual database content, and no user sees a signal that the response was not grounded.
The span activity chart on the right breaks the 30-day traffic into three distinct series: Validate URL tool calls, RAG over Database tool calls, and raw LLM spans. An engineer investigating the faithfulness drop visible in the chart around December 29 to January 5 checks two hypotheses using these series: if RAG call volume fell proportionally to LLM span volume, retrieval is failing to execute; if LLM spans held constant while RAG calls dropped, the model is receiving an empty context window and answering from memory anyway.
The Evaluator Rules tab at the top of the dashboard is where teams configure the faithfulness threshold that fires an alert, so rather than discovering a 0.11 score during a quarterly review, the team receives a notification the day the score crosses the configured minimum.
AI Governance Platform Comparison
How to Match Your Governance Challenge to the Right Platform
The platforms above split the governance problem into distinct focus areas. Matching the right platform to an organization's situation depends on which part of the problem is most urgent.
Choose Firefly AI when the primary challenge is cloud infrastructure governance, maintaining a governed, continuously monitored infrastructure estate with automated policy enforcement, drift detection, and disaster recovery readiness. Firefly AI fits DevOps and platform engineering teams in organizations subject to SOC 2, PCI DSS, or HIPAA continuous compliance requirements.
Choose Credo AI when the primary challenge is building a governance program: defining policies, creating repeatable approval workflows, maintaining a centralized AI inventory, and generating audit evidence for regulatory frameworks. Credo AI is best suited for GRC teams, CAIOs, and CISOs at large enterprises scaling AI deployments and formalizing oversight across business units.
Choose Holistic AI when the primary challenge is both program management and technical enforcement, testing AI systems for bias, safety, and security vulnerabilities before deployment, and blocking unsafe outputs in production without requiring separate tools for each layer. Holistic AI fits enterprises deploying customer-facing AI in sectors where automated bias and safety controls are compliance requirements, not optional features.
Choose Monitaur when the primary challenge is producing governance evidence that satisfies regulatory examination, not just documenting that governance occurred, but proving through validated records, test results, and approval trails that every AI system was assessed against defined risk criteria and approved through a structured process. Monitaur fits banks, insurers, and healthcare organizations operating formal MRM programs that need to extend those programs to GenAI and agentic systems.
Choose Fiddler AI when the primary challenge is production visibility, detecting model drift, diagnosing multi-agent failures, monitoring hallucination and toxicity rates under live traffic, and generating compliance evidence from continuous production monitoring rather than periodic audits. Fiddler AI fits AI platform teams running large-scale LLM and ML deployments where production behavior differs materially from evaluation behavior.
Many enterprises find that their governance requirements span more than one area. A financial institution may use Monitaur for model risk management evidence, Fiddler AI for production monitoring, and ModelOp as the lifecycle operating layer that ties both into a single governance workflow. Evaluating two or three platforms together against specific organizational requirements, rather than selecting based on feature lists alone, consistently produces better outcomes than treating the category as undifferentiated.
FAQs
What Is Cloud Security Posture Management?
Cloud Security Posture Management is a category of tooling that continuously monitors cloud environments for misconfigurations, compliance violations, excessive IAM permissions, and exposed resources. CSPM platforms provide visibility across cloud accounts, automate security assessments against frameworks such as CIS and NIST, and surface findings for remediation before they result in a breach or a failed audit.
What Is the Difference Between CSPM and SIEM?
CSPM continuously assesses cloud resource configurations for misconfigurations, policy violations, and compliance gaps. It answers "what is the current posture of this environment?" SIEM collects and correlates logs and security events across infrastructure to detect, investigate, and respond to threats. It answers "what happened, and is it a threat?" CSPM prevents exploitable conditions. SIEM detects when exploitable conditions are being acted on.
What Are the Most Widely Used CSPM Tools?
Cover the tool landscape without superlatives. Note that the right CSPM solution depends on cloud architecture, regulatory framework, and whether the organization's IaC is primarily Terraform, CloudFormation, or Pulumi. Mention Opsera as providing continuous compliance visibility with pre-deployment Terraform assessment as a differentiated capability.
What Does a CSPM Finding Look Like in Practice?
Walk through a concrete example: CSPM platform scans an S3 bucket, detects that BlockPublicAcls is set to false and no encryption configuration exists, flags the bucket as publicly accessible and unencrypted, maps the finding to a CIS benchmark control, and surfaces it with remediation guidance. Contrast with the pre-deployment equivalent: Opsera reads the S3 bucket module in Terraform, detects no aws_s3_bucket_server_side_encryption_configuration block, and flags the gap before Terraform apply runs.
.webp)


.webp)















