
Most teams have a disaster recovery plan. Far fewer have tested whether it actually works.
(Think about it. When was the last time you tested yours? If that question makes you a little bit uncomfortable, you’ll want to keep reading.)
That gap between a theoretical plan and a tested and validated one is where incidents turn into outages. The assumptions below are common, widely held, and consistently wrong. Firefly and AWS broke them down in a recent webinar, alongside the architectural patterns and tooling that give teams real confidence in their recovery posture.
Here's what we covered (plus, a handy link to the on-demand recording!)
The 5 Wrong Assumptions Getting Teams Into Trouble
Eran Bibi, Firefly Co-Founder and CPTO, reveals five assumptions causing disaster recovery challenges: ones he sees ring true across organizations of all sizes.
Misconception #1: Cloud DR works like on-prem DR
The pace of change in cloud environments is fundamentally different from a data center. Teams are provisioning infrastructure daily, with multiple tools and multiple people touching the same environment. The processes that worked on-prem don't map cleanly to that reality.
Misconception #2: If one app is recoverable, they all are
Every cloud application has its own dependency graph. Validating one doesn't mean the others are ready. Every business-critical application needs its own testing and visibility.
Misconception #3: Backing up data = guaranteed resiliency
Data backup is necessary but not sufficient. If the supporting infrastructure isn't also captured and recoverable, including subnets, security groups, identity components, and networking layers, the application won't run even if the data is there.
Misconception #4: ClickOps is fine
Manual changes through the cloud console are not auditable, not repeatable, and nearly impossible to reproduce in a disaster scenario. IaC coverage, the percentage of your cloud managed by code versus done manually, is a metric that should live on your resilience dashboard.
Misconception #5: IaC alone is enough
Even teams using IaC run into drift: the gap between what your code says and what's actually running in the cloud. When a third-party tool or a manual change modifies a resource outside of code, the blueprint no longer reflects reality. In a disaster, you find that out the hard way.
What True Cloud Resilience Requires at Scale
In our webinar, Cristian Critelli, AWS Lead Networking and Resilience Specialist, walked through the AWS mental model for resilience, which breaks into three areas: high availability, disaster recovery, and continuous improvement.
High availability is about resistance. When small failures happen, the application keeps serving users without them noticing.
Disaster recovery is about one thing: actual recovery. When something larger happens, a regional failure, a security event, a misconfiguration at scale, teams need a defined path back to operational. That path is governed by RPO (how much data can you afford to lose) and RTO (how long can you afford to be offline).
Continuous improvement is about testing. Chaos engineering, observability, and regular DR drills are what separate a plan that works from one that just looks good on paper.
As Critelli put it:
"If you never tested it, just consider it a guess."
He also covered five categories of failure to architect against:
- Single points of failure
- Excessive load
- Excessive latency
- Misconfiguration and bugs
- And shared fate, where dependency on a third-party service means their outage becomes yours.
On infrastructure, Critelli made the case for pre-provisioning capacity. Auto-scaling groups depend on the control plane. If the control plane is impaired during a failure, scaling won't kick in. Pre-provisioned capacity in each availability zone is what keeps applications running when a zone goes down.
He also walked through the full DR strategy spectrum, from backup-and-restore to active-active, with the tradeoffs at each level. The point: your DR tier should match your application's criticality, compliance requirements, and budget.
The Path From Blueprint to Recovery in Minutes
Our on-demand webinar shows a live demo of how Firefly operationalizes all of this.
The platform is built around three capabilities: automating IaC-based deployments with guardrails, giving teams visibility into what's managed versus unmanaged in their cloud, and enabling fast recovery through automated snapshots and Terraform-based replication.
During the session, we walked through a real flow: scoping an application (a checkout service), running dependency discovery to capture not just compute but networking, identity, and security layers, setting an RPO, selecting a recovery target region, and generating the IAC module used to rebuild the environment. Snapshots are committed to version control as pull requests, so the recovery blueprint lives in the customer's own infrastructure regardless of Firefly's availability.
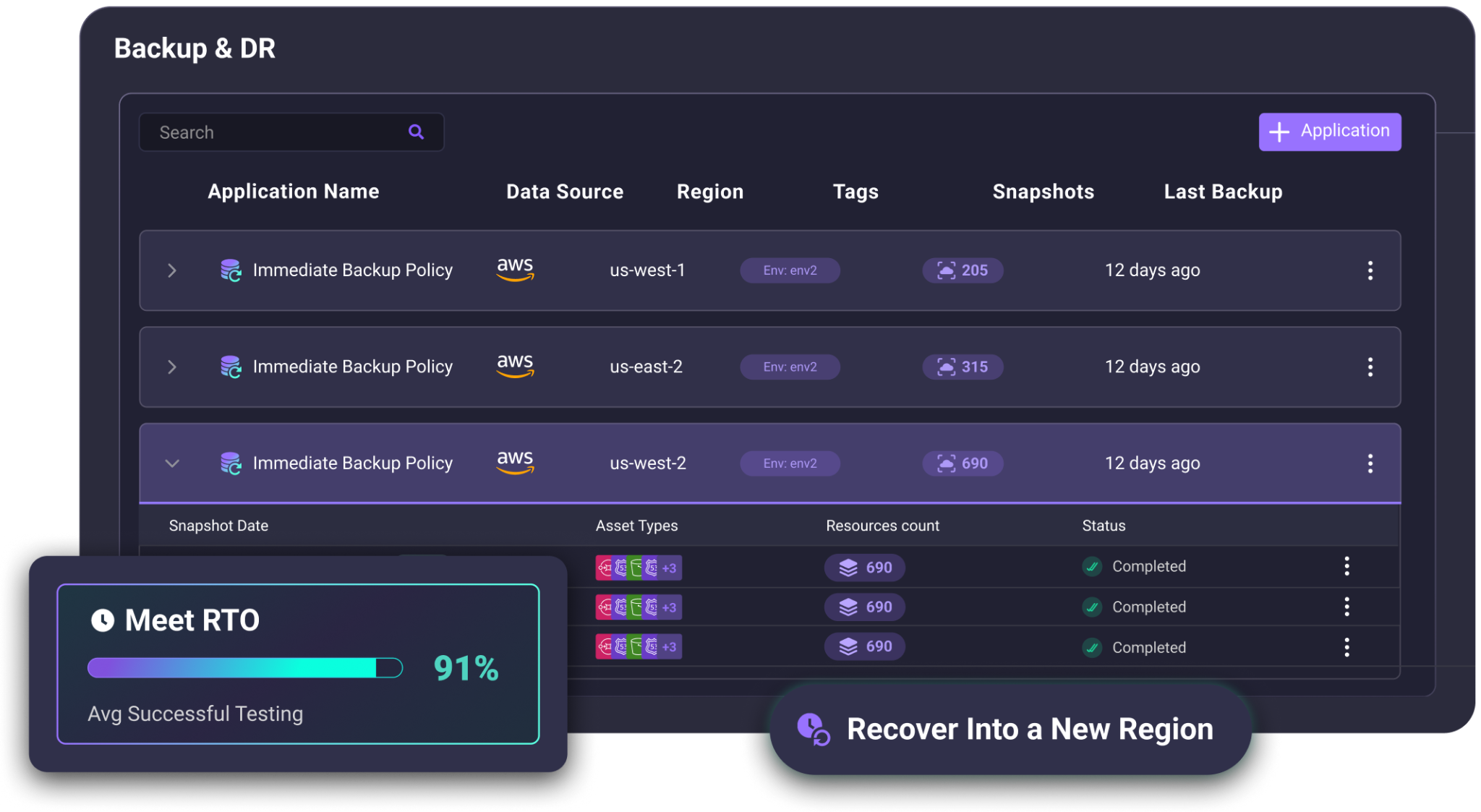
Before recovery starts, the plan output shows exactly what would be created, estimated cost, tag coverage, and any misconfigurations in the source environment. Firefly reruns the plan every 24 hours and surfaces a current readiness signal, so teams know whether their application is recoverable today, not just when they set it up.
Note: Gartner recently recognized this as a distinct category, Continuous Resilience Automation (CRA), which combines resilience posture management with validated recovery capability. Firefly is named as one of the vendors in the space.
Watch the Full Session: Architecture, Demo, and Q&A
The frameworks above are a starting point.
The full session goes deeper on AWS architecture patterns, solutions to common disaster recovery challenges including a Firefly demo, and a Q&A where the panelists address how to distinguish high availability from disaster recovery, how to choose the right AWS region for DR, and what meeting real RPO and RTO commitments requires in practice.
[Watch the on-demand recording here.]

.svg)