
Ask infrastructure practitioners what they most want from IaC in 2026 and the answer is unambiguous: infrastructure immutability and rebuild confidence.
More than anything else, practitioners say that’s the #1 benefit of infrastructure-as-code: that it gives you the foundation you need to lose a region, a stack, an entire environment, and bring it back from code alone, within a defined window, without downtime.
That makes a big statement about what IaC is actually supposed to be for.
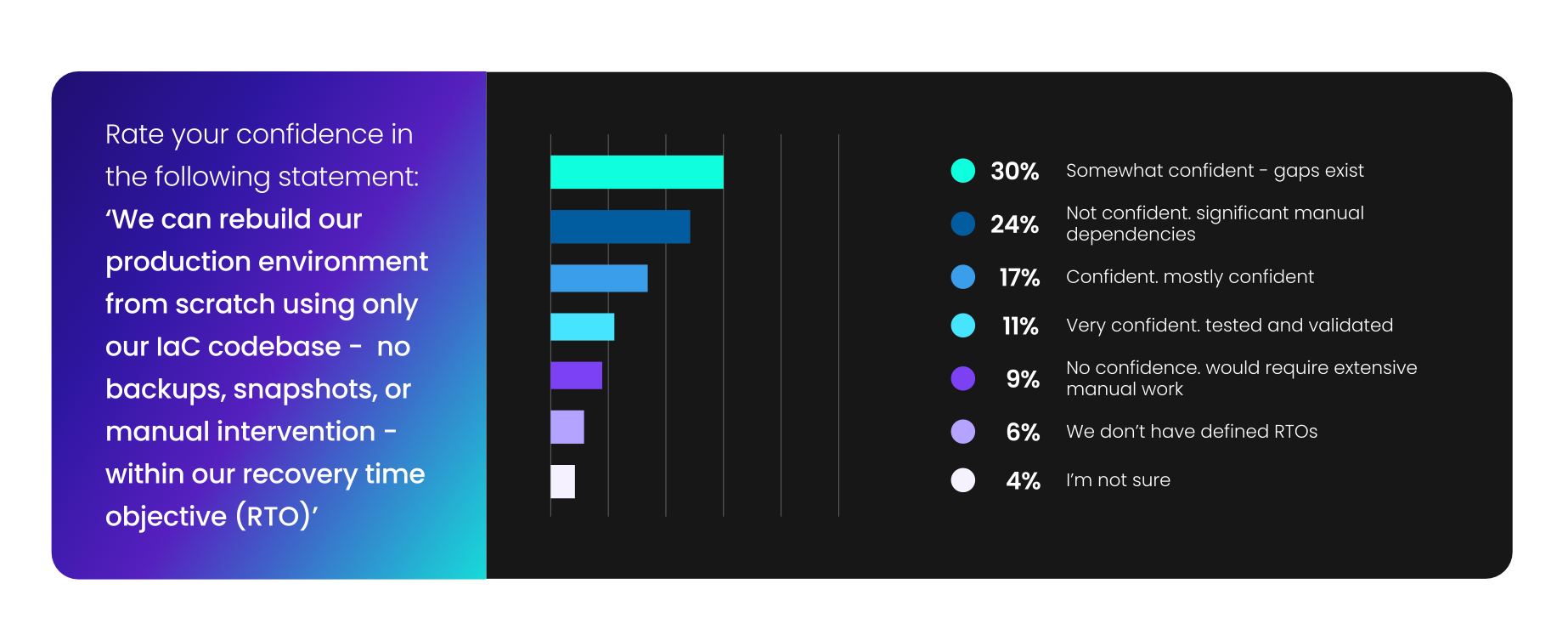
Now ask how many teams have actually built out what they seek? Only 11%. That's the percentage who describe their DR posture as tested and validated. Everyone else is somewhere on a spectrum between "pretty sure it would work" and "we'd probably be in serious trouble, but hopefully not."
That gap between what the industry believes IaC should deliver and what it actually delivers when things go wrong is the most important story in infrastructure right now.
The 2026 State of Infrastructure as Code report reveals what the current landscape looks like.
Finding #1: IaC adoption and IaC recovery readiness are not the same thing
This distinction gets lost constantly, and it costs teams badly when incidents hit.
Most organizations have IaC. Pipelines are running. Modules are versioned. State files are stored. By the traditional adoption metrics, the job is done. But adoption is an inventory story. Recovery is a different story entirely: one that most teams haven't stress-tested.
- 29% of practitioners don't test DR procedures, and 17% have no formal DR plan
- 1 in 3 have little to no confidence they can restore within RTO
- When asked how quickly they could restore operations if their primary region failed today, only 37% could do so within 4 hours
- 22% would take more than a day
For teams with IaC, the code exists, but the confidence doesn't.
Because data protection is not the same as business resilience. Until the rebuild has actually been run, against a real RTO, with the gaps documented and closed, it's nothing more than a hypothesis.
Finding #2: ClickOps debt is often why the rebuild fails
When teams do try to recover from code alone, this is usually where it breaks down.
The IaC codebase doesn't represent production. It represents the parts of production that were provisioned through code, which in most organizations, is not everything. The gap between what's in the repo and what's actually running in the cloud has been quietly growing for years.
"Retrofitting existing ClickOps infrastructure into code" ranks as the #1 IaC blocker in 2026, ahead of both skills gaps and tooling fragmentation. The debt that was deprioritized in favor of shipping, accumulated quietly, and is now sitting directly between most organizations and the rebuild confidence they say they want most.
You can't rebuild from IaC if your infrastructure isn't in IaC. And in most organizations, it isn't, at least not fully, accurately, and dependably.
The fact that auto-generating IaC from existing cloud resources tops the AI capability wishlist by a wide margin isn't a coincidence. Practitioners know the debt is there. They're looking for a way to close it that doesn't require a six-month manual audit.
Finding #3: Validation practices are making it all worse
Even for the infrastructure that is codified, most teams aren't confident in what they have.
- 37% rely on manual human review before apply.
- 6% apply with no validation at all.
- Only 26% run comprehensive automated checks (think: security, policy, cost, testing) before anything lands in production.
Manual review isn't completely negligible, of course. But it's also a single point of failure that doesn't scale and certainly doesn't constitute a tested recovery posture. It's a process built for normal operations, not for the real, inevitable incidents your organizations will face at one point or another.
The automation maturity picture says the same thing from a different angle.
Just 5% of teams have reached fully self-healing infrastructure. 49% are still at manual or basic scripted levels.

Most production changes still require a human in the loop.
That's the baseline the industry is operating at.
Why this matters more now than it did a year ago
A year ago, the rebuild confidence gap was a problem. In 2026, it's an accelerating one.
AI agents are now in the infrastructure lifecycle for nearly half of teams surveyed. Agents that make changes at machine speed, against infrastructure that may not be fully codified, with drift remediation processes that were built for human-paced change management. If an agent introduces a bad change (and they will) the recovery depends entirely on the foundation underneath it.
Weak codification coverage plus untested DR plus manual validation doesn't just mean slow recovery. It means the thing practitioners most want from IaC (the ability to rebuild with confidence) is unavailable exactly when it's needed most.
The teams ranking rebuild confidence as the #1 IaC benefit aren't being idealistic. They're naming the thing that makes everything else survivable. Without it, speed is just a faster way to reach an incident you can't cleanly recover from.
The fix? Test the recovery, not the plan
You need to be able to rely on the actual, successful execution of rebuilding from the IaC codebase, against a defined RTO, with real gaps surfaced and closed. Until that's happened, rebuild confidence is a hope, but not quite a capability.
Get an accurate picture of what's actually in code versus what isn't. Not the version from the last architecture review — the real-time, continuously reconciled version against live cloud state. Then, treat codification as infrastructure work, not cleanup. Every week that uncodified infrastructure sits in production, the delta between the codebase and reality grows harder to close, and the rebuild scenario gets harder to execute.
The organizations building toward genuine cloud resilience aren't necessarily the most sophisticated. But they are the ones who decided that IaC's job isn't deployment, but recovery, and they built accordingly.

.svg)