
We recently stumbled onto something that surprised us.
While analyzing CloudTrail deny events across our customer base (that’s thousands of AWS accounts, spanning hundreds of organizations), we noticed recurring patterns. Different companies, different industries, different team structures. But all facing the same misconfigurations, same silent failures, and same financial and operational bleed.
You might assume they’re breaches or unauthorized access attempts. In reality, they're legitimate cloud operations (all being performed by trusted services and internal tools) that are getting blocked by overly broad policies or missing permissions.
At Firefly, we call them "falsely denied" events, and once you start looking for them, you realize they're everywhere.
Finding #1: The Missing Permission That Creates Ghost Volumes
The first pattern surfaced when we filtered our Event Center for denied EC2 actions. One finding immediately jumped out: EMR service roles failing to delete EBS volumes during cluster teardown.
Here's a redacted CloudTrail event from one customer:
{
"eventName": "DeleteVolume",
"errorCode": "Client.UnauthorizedOperation",
"errorMessage": "...is not authorized to perform: ec2:DeleteVolume...
because no identity-based policy allows the ec2:DeleteVolume action",
"sourceIPAddress": "elasticmapreduce.amazonaws.com",
"userAgent": "elasticmapreduce.amazonaws.com"
}
And here's one from a completely unrelated customer: different account, different role name, different naming convention.
{
"eventName": "DeleteVolume",
"errorCode": "Client.UnauthorizedOperation",
"errorMessage": "...is not authorized to perform: ec2:DeleteVolume...
because no identity-based policy allows the ec2:DeleteVolume action",
"sourceIPAddress": "elasticmapreduce.amazonaws.com"
}
Two independent organizations with zero connection to each other. Identical failure mode. And these were just the two that caught our eye first. But the pattern repeats across our dataset.
What's actually happening: When an EMR cluster terminates, the EMR service assumes your custom service role and calls ec2:DeleteVolume to clean up EBS volumes from terminated nodes. If the role doesn't include that permission (and most custom roles don't), the call is silently denied. The cluster still shows as "Terminated" in the console. No alarms fire. But those EBS volumes? They're now orphaned, sitting in an available state, accumulating charges indefinitely.
Why it keeps happening: Teams build EMR permissions based on the visible workflow. Launching clusters needs RunInstances and CreateVolume. Running jobs needs S3 access. Terminating needs TerminateInstances. But DeleteVolume is a background cleanup action performed by the EMR service. Nobody explicitly triggers it, so nobody thinks to include it. Testing doesn't catch it either. (That means the cluster terminates successfully, and the leftover volumes are invisible, unless you go looking for them.)
Making matters worse, teams using IAM Access Analyzer or CloudTrail-based policy generators to build least-privilege policies will never see DeleteVolume in their observation data unless a cluster happened to terminate and the permission was already present during the observation window. The very tools designed to help create tight policies can reinforce the gap.
This is why observation-based policy generation should be treated as a starting point rather than a complete solution.
The cost: A typical EMR cluster runs 3 to 20 nodes, each with 100 to 500 GB of EBS storage. At $0.08/GB/month for gp3, each orphaned volume costs roughly $8 to $40 per month. An organization running 5 to 10 transient clusters daily can accumulate hundreds of orphaned volumes within a few months. We estimate the annual waste at $10,000 to $50,000 per organization, more for teams running EMR across multiple accounts.
Finding #2: When Preventive Controls Block Your Own CI/CD (And Do It 28,000 Times)
The second pattern is different in origin but equally revealing. This time, the denial wasn't caused by a missing permission. It was caused by a Service Control Policy explicitly blocking a legitimate operation.
Here's the event:
{
"eventName": "RunInstances",
"errorCode": "Client.UnauthorizedOperation",
"errorMessage": "...is not authorized to perform: ec2:RunInstances
on resource: arn:aws:ec2:eu-west-1:***:volume/*
with an explicit deny in a service control policy",
"userAgent": "TeamCity Server 2023.11.4...",
"sourceIPAddress": "5*.2**.2**.1**"
}
This is a TeamCity CI/CD server attempting to launch spot EC2 instances as build agents: a completely standard, expected operation. The role (TeamCItyServer) is configured to spin up Windows Server 2019 spot instances (m5.xlarge) tagged with the appropriate department, environment, and profile metadata. Everything about this request looks intentional and well-configured.
But an SCP is blocking it. And it's not a one-off: this event occurred 28,000 times in 7 days.
That's 4,000 denied attempts per day, or roughly 167 per hour. TeamCity keeps trying to launch build agents, keeps getting denied, and keeps retrying. Meanwhile, the engineering team is probably wondering why their CI/CD pipelines are slow, why builds are queuing, why agent capacity seems unreliable.
The error message is telling: the SCP is denying ec2:RunInstances specifically on the volume/* resource. This likely means the organization deployed a preventive control (perhaps requiring EBS volume encryption, enforcing specific volume types, or mandating certain tags on volumes) that inadvertently catches TeamCity's instance launches in its blast radius.
This is the SCP paradox: the control was almost certainly put in place with good intentions.
- Enforce encryption everywhere.
- Prevent untagged resources.
- Block non-approved instance types.
But the policy was written broadly enough that it's blocking a core internal service 4,000 times a day. And worse, nobody seems to be aware of it.
The Bigger Picture: Preventive Controls Are Creating a Deny Event Epidemic
Here's what made these findings genuinely interesting to us. They're not isolated incidents. They point to a systemic pattern that's accelerating across cloud environments.
Over the past two years, preventive controls have become the dominant paradigm in cloud governance. AWS Service Control Policies and the newer Resource Control Policies. Azure Policy deny effects. GCP Organization Policy constraints. The industry (and rightfully so) has moved toward a model where guardrails are enforced proactively rather than detected reactively.
This is a good thing. Shift-left security, policy-as-code, preventive guardrails: we're strong advocates for all of it at Firefly. But there's a side effect that nobody is talking about: the explosion of false deny events from policies that are too broad, too blunt, or simply not tested against every legitimate workflow in the organization.
When a security team writes an SCP that says "deny ec2:RunInstances unless the volume is encrypted with our KMS key," they're thinking about rogue developers spinning up unencrypted instances. They're not thinking about the TeamCity server that's been quietly launching build agents the same way for three years. When a platform team mandates specific EBS volume tags via an SCP, they're not considering every service role that creates volumes as a side effect of its primary operation.
The result is a growing volume of denied API calls that represent legitimate, expected operations being blocked by controls that don't account for them. And because these denials happen at the API level, nobody sees them. The operations fail silently, then the services retry. The retry storms, in turn, generate thousands of CloudTrail events that nobody reads.
And here's the part that concerns me most: CloudTrail retains these events, but almost nobody is analyzing them systematically. Most teams treat CloudTrail as a forensic tool (i.e. you search it after something goes wrong). But the falsely denied events aren't triggering incidents. The build agents eventually launch, usually after dozens of retries. The orphaned volumes don't page anyone. The operational impact is real but diffuse: slower CI/CD, accumulated waste, unexplained cost creep.
What You Should Do Right Now
If you're running a cloud environment with any kind of governance controls (and you should be), here's how to check whether you have a false denial problem.
Audit your CloudTrail for denied events. Filter for errorCode = Client.UnauthorizedOperation and look for patterns. Pay special attention to calls from AWS services (sourceIPAddress ending in .amazonaws.com) and from internal tools (CI/CD servers, orchestrators, automation platforms). These are the most likely sources of false denials.
Check your EMR service roles. If you're using custom roles instead of the AWS managed policy, verify that ec2:DeleteVolume and ec2:DetachVolume are included. Then scan for orphaned EBS volumes in available state:
aws ec2 describe-volumes \
--filters Name=status,Values=available \
--query "Volumes[*].{ID:VolumeId,Size:Size,Created:CreateTime}" \
--output table
Review your SCPs against your actual workloads. For every SCP that contains a Deny statement, ask: which internal services and tools might trigger the actions this policy blocks? Have we tested this policy against our CI/CD pipelines, our orchestration tools, our managed services? An SCP that's never been validated against real workloads is a false denial waiting to happen.
Look for retry storms. A high volume of identical denied events from the same principal in a short time window is a strong signal. It means a service is trying to do its job, getting blocked, and retrying. The 28,000 events in 7 days we found is an extreme example, but even a few hundred denied events per day from the same source deserves investigation.
Fix the permission gaps. For the EMR case, add the missing permissions to your service role:
{
"Effect": "Allow",
"Action": ["ec2:DeleteVolume", "ec2:DetachVolume"],
"Resource": "arn:aws:ec2:*:*:volume/*",
"Condition": {
"StringEquals": {
"ec2:ResourceTag/aws:elasticmapreduce:cluster-id": "*"
}
}
}
For SCP-related denials, add targeted exceptions for your trusted automation roles rather than loosening the policy globally.
Update your IaC. Whatever you fix, fix it in your Terraform modules, CloudFormation templates, or Pulumi code. Otherwise you'll re-create the gap with every new environment.
How We Spotted This
This is exactly what Firefly's Event Center was built for. It aggregates cloud events (including ClickOps changes, CLI operations, IaC-driven changes, and critically, Deny events) into a single, filterable view across all your connected accounts. We can filter by:
- Event type
- Time range
- Asset type
- Data source
- And owner
And that level of granularity means we can zero in on patterns like the ones described in this post.
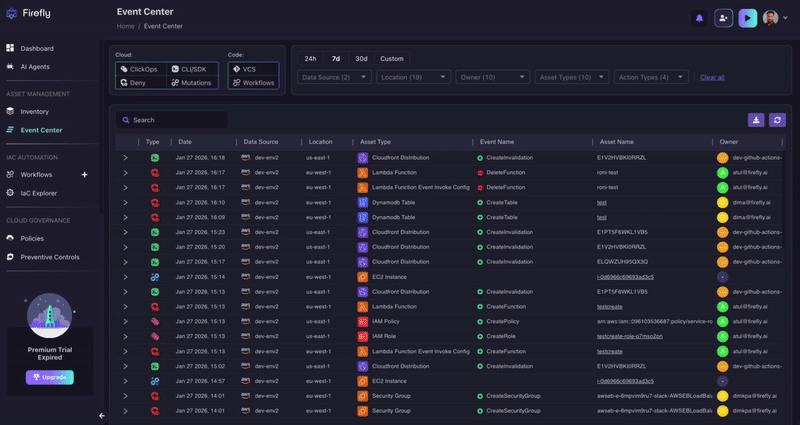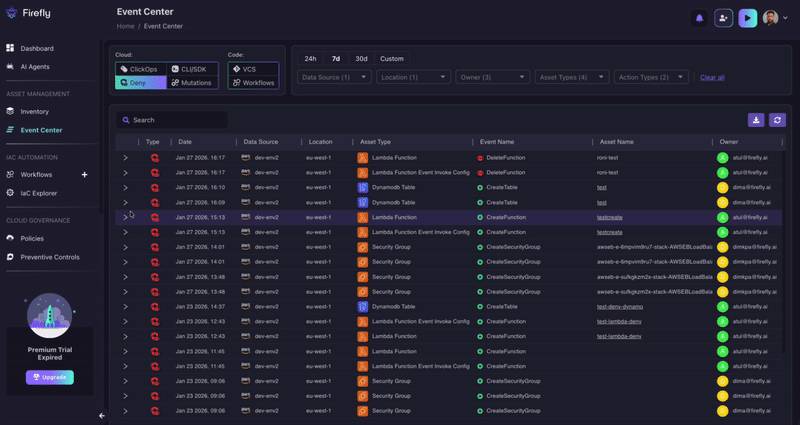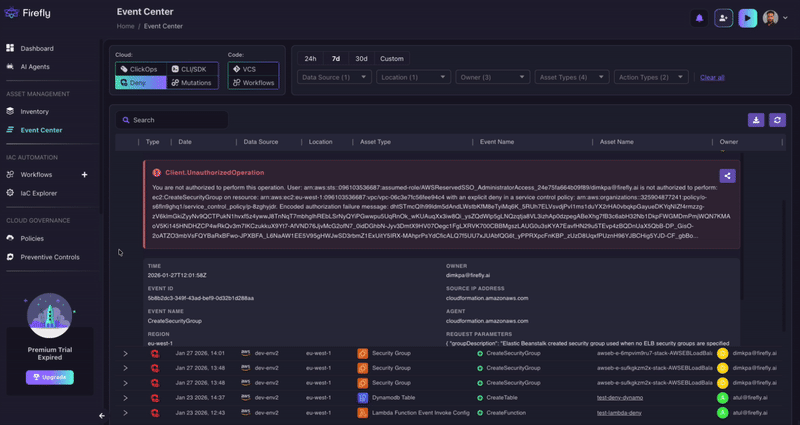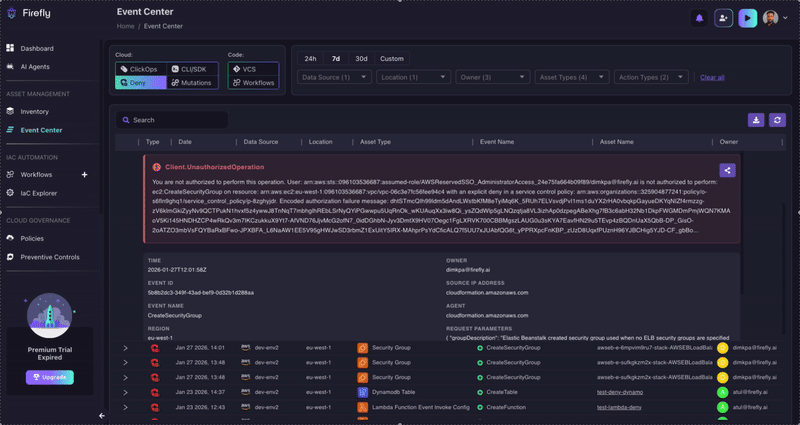
Neither the EMR pattern nor the TeamCity pattern was something we went looking for. They surfaced naturally once we started filtering for denied events across customer environments. The repeated identical failures from unrelated organizations made the patterns impossible to miss.
If you're curious what's silently failing in your cloud, sign up at app.firefly.ai and connect your AWS accounts. The Event Center will show you every denied action, including the ones you didn't know were happening.
You might be surprised by what you find.

.svg)