
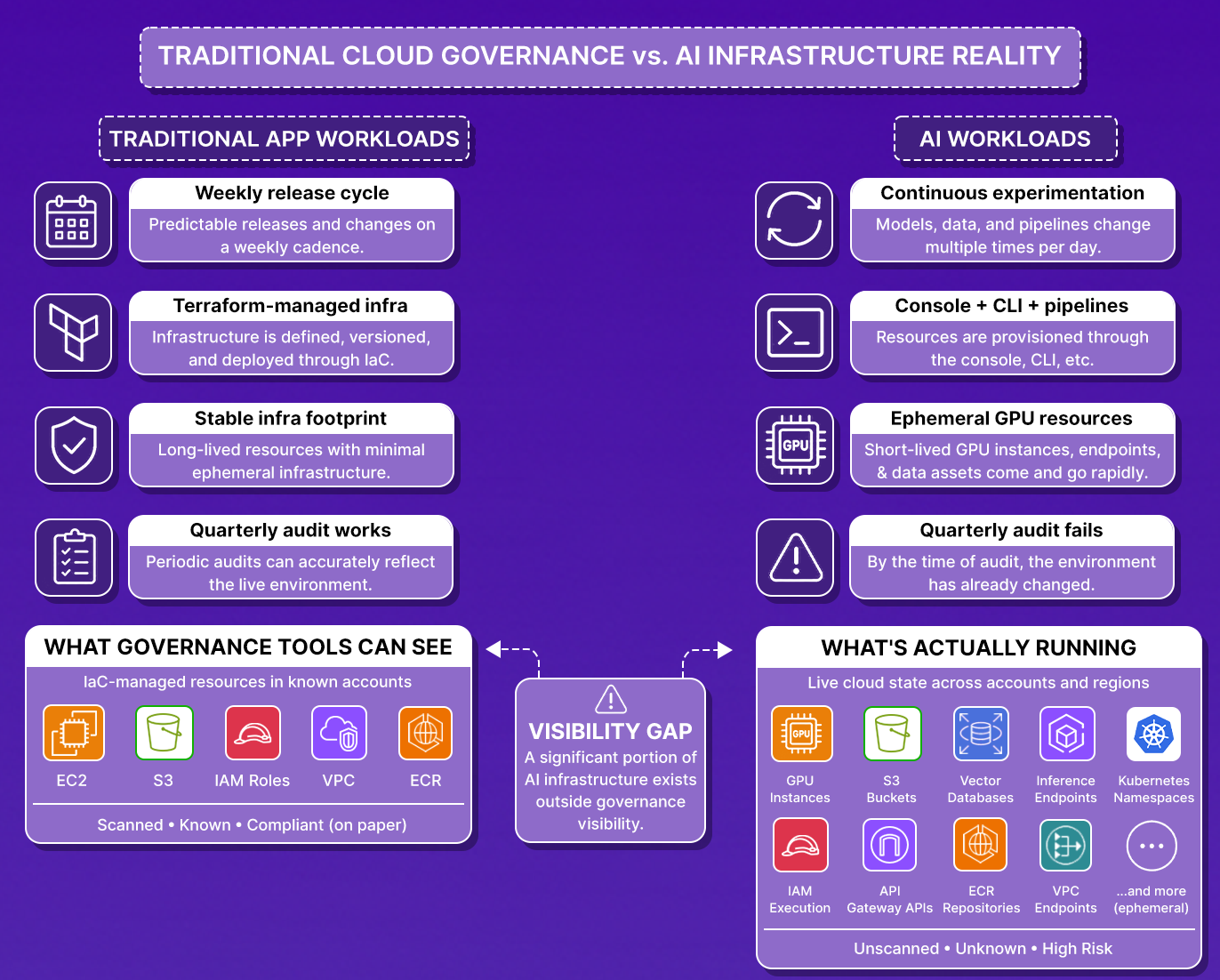
TL;DR
- Multiple cloud incidents start as operational failures, a stale Terraform plan, an incompatible Kubernetes upgrade, a CI runner with permissions nobody audited, not an external attacker.
- Restoring your database backup does not restore production: the IRSA role bindings, cert-manager ClusterIssuers, and WAF ACL ARNs your app depends on are not in any snapshot.
- Infrastructure drifts silently between incidents: every manual console change, kubectl patch, and out-of-band IAM edit lives in your runtime but not in your Ia.C.
- No single tool category covers infrastructure-state recovery, backup tools restore data, CSPM platforms surface misconfigurations, IaC tools rebuild what you declared, but none reconstruct what you actually deployed.
- Firefly closes this gap by maintaining a continuous cloud system of record, reverse-engineering unmanaged resources into IaC, and enabling drift-aware recovery across your full environment.
- Teams that recover in minutes treat drift detection and restore validation as P2 production issues rather than quarterly compliance tasks.
Cloud outages are not caused by attackers. They are caused by the infrastructure itself becoming inconsistent, unrecoverable, or operationally opaque, and nobody notices until something breaks at the worst possible moment.
An engineer runs terraform apply against a stale plan and removes the production route table. A Kubernetes upgrade patches the control plane but leaves ingress controllers on an incompatible version. A leaked AWS access key gets used to delete CloudTrail logs and attach a persistent IAM role. A CI runner with AssumeRole permissions on the production account deploys a modified container image that nobody approved.
None of these is hypothetical. They are the normal failure modes in large cloud environments, environments with dozens of accounts, hundreds of Kubernetes namespaces, and CI/CD pipelines that have accumulated permissions over years of unchecked growth.
The common thread across all four failure patterns is not that prevention failed. Prevention will always fail eventually. The question that matters is what happens after it does.
What Is Cyber Resilience?
Cyber resilience is the ability of a platform to continue operating and recover to a trusted state when the Kubernetes control plane fails, IAM credentials are compromised, a CI pipeline deploys a corrupted image, Terraform state is deleted, or a cloud region experiences partial degradation.
For platform engineers and SREs, that means four specific infrastructure capabilities need to hold under pressure:
1. Blast radius containment
A compromised namespace should not have a path to modify cluster-wide RBAC. A CI pipeline deploying to staging should not include credentials capable of assuming production IAM roles.
2. Operational continuity during disruption.
Workloads in us-east-1 should fail over to us-west-2 without engineers manually updating DNS. A database read replica in a secondary region should be replicating continuously, not provisioned on demand when the primary goes down.
3. Infrastructure rebuildability from the declared state.
Running terraform apply against the main branch should recreate a working environment, not a partial one that's missing the IAM trust relationships an engineer added directly in the AWS console during an incident six months ago.
4. Trusted operation restoration after compromise.
After a CI runner is identified as compromised, the team should be able to rotate its credentials, validate that no malicious images were pushed to ECR, and confirm that Terraform state was not modified, in minutes, not hours.
Whether those four capabilities hold during an incident depends almost entirely on whether the environment was designed for recoverability from the start.
Why Cyber Resilience Is Harder in Cloud-Native Environments
A firewall rule blocks an unrecognized IP; the failure stays at the network edge. A single EC2 instance crashes, and the failure stays on that host. That model of contained, local failures is what most security tooling was built to handle.
It does not describe how a production EKS cluster fails. When a PostgreSQL RDS instance starts responding slowly, the failure does not stay in the database:
The original problem was a slow query in the payments service. The actual outage spans four services and a Kubernetes scheduling delay, no attacker involved, no misconfiguration, and no single component misbehaving.
The outage emerged from how the payments connection pool, the checkout retry configuration, the node autoscaler, the Kubernetes scheduler, and ArgoCD's reconciliation loop interacted under load. Each system did exactly what it was configured to do. Together, they turned a slow database query into a cluster-wide disruption.
What that means for recovery: the right unit is not the payments database. It is the full chai, the connection pool limit on the payments service, the retry budget and backoff ceiling on checkout and orders, the autoscaling threshold that determines when nodes get added, and the liveness probe tolerance that decides which pods restart. Restore the database without those, and the same cascade fires on the next traffic spike.
Traditional backup tools restore the database. They do not restore the connection pool limits, retry configurations, and autoscaling policies that determine whether the cluster survives the load that follows.
Why a Completed Backup Restore Does Not Mean Your Platform Has Recovered
The scenario every DR plan is written for: ransomware encrypts the EBS volumes on the application nodes. The on-call team does what the runbook says: snapshot the RDS instance from two hours before the attack, spin up a clean VPC, and restore the database. The restore completes in 40 minutes. The team runs terraform apply and lets ArgoCD sync the cluster back to the state in Git. All pods come up. Readiness probes pass. ArgoCD shows green across every application.
Four hours later, the engineering manager is still on a war-room call because production is returning errors. What the restore brought back: the database, with data intact up to the snapshot timestamp. What the restore could not bring back, because none of it existed in Git:
The pods were running. ArgoCD was green. But external-secrets could not authenticate to AWS Secrets Manager, so every pod that needed a database credential started without one. TLS renewal failed because cert-manager was pointing at a Route53-hosted zone that no longer existed in the new account. The ALB came up without the WAF ACL that had been manually created in the console two years earlier and never added to Terraform. ArgoCD stopped syncing because its GitHub App installation was registered against the old cluster's OIDC provider.
The backup did its job. It restored the RDS instance exactly as it was two hours before the attack. What it could not restore was the runtime infrastructure state the application depended on, the IAM roles, DNS zone IDs, WAF rules, and OIDC bindings that were created manually over two years and never committed to Git.
This is not specific to ransomware. The same breakdown surfaces any time a rebuild is forced: a region failover, a corrupted Terraform state, a cluster upgrade that goes wrong. The database comes back. Everything that was never in Git does not.
Why Cloud Infrastructure Resists Recovery
Those four broken dependencies, the IRSA role, the Route53 zone ID, the WAF ACL, and the OIDC provider, were not accidents. They represent four specific patterns through which cloud environments accumulate untracked state that only becomes visible when a rebuild is forced.
Manual Changes That Terraform Will Undo on Rebuild
Every cloud environment drifts. The mechanism is always the same: an engineer makes a manual change during an incident, production recovers, and the change never gets committed to Terraform. Over months, these changes accumulate:
- An added inbound rule on a security group
- A modified IAM policy to let a workload read from a new S3 bucket
- A Route53 failover record created during a DNS incident
- A Kubernetes resource patched directly with kubectl edit
None of these feels significant at the time. But when a rebuild is forced, by a region failure, a ransomware event, or a Terraform state corruption, Terraform restores the declared state, not the current state. All those runtime dependencies that accumulated since the last git commit are gone.
The environment Terraform builds is not the environment that was running. Workloads lose S3 access. Health checks fail on ports that the security group no longer allows. Ingress routing breaks because the failover record is missing. Engineers spend hours tracing failures that have nothing to do with the original incident.
The only control that prevents this is continuous drift detection: comparing runtime cloud state against declared IaC state and treating divergence as a P2 production issue, not a cosmetic finding.
A Lost Terraform State File Takes Days to Reconstruct
Terraform state is not a deployment artifact. It is the source of truth for the resources Terraform manages, resource IDs, dependency graph, module outputs, and provider relationships.
When a state is corrupted or deleted, Terraform loses track of which resources it owns. Running terraform plan against orphaned infrastructure produces plans that want to create resources that already exist. Running terraform apply against that plan creates duplicate resources and breaks networking because two VPCs now share the same CIDR range.
Recovering from state corruption without a backup requires reverse-engineering the state file from live infrastructure, manually importing each resource in dependency order, while production is down. This takes days.
Terraform state backends need versioning, cross-region replication, and access restricted to dedicated deployment roles, not the same roles used by CI pipelines running against development environments:
terraform {
backend "s3" {
bucket = "company-terraform-state-prod"
key = "production/main.tfstate"
region = "us-east-1"
encrypt = true
dynamodb_table = "terraform-state-lock"
# S3 bucket should have:
# - versioning enabled
# - cross-region replication to us-west-2
# - bucket policy restricted to deployment role only
# - NOT accessible from CI pipelines running against dev/staging
}
}Cluster Recovery That Depends on Startup Order Nobody Documented
Restoring a Kubernetes cluster is not the same as restoring production on Kubernetes. The cluster is the compute layer. Production is the cluster plus every operator, webhook, CRD, and cloud integration running on top of it, each with its own startup dependencies.
When a cluster is rebuilt, and manifests are reapplied without respecting dependency order, this failure sequence is common:
.webp)
Result: kubectl get pods shows everything Running. Production is still broken.
ArgoCD sync waves solve the ordering problem, but only when ordering is explicitly declared. Most clusters have implicit dependency ordering that experienced engineers understand but never encode:
# Explicit sync wave ordering in ArgoCD Applications
---
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: cert-manager
annotations:
argocd.argoproj.io/sync-wave: "1" # Infrastructure operators first
spec:
# ...
---
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: external-secrets
annotations:
argocd.argoproj.io/sync-wave: "2" # Secret sync after operators
spec:
# ...
---
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: application-workload
annotations:
argocd.argoproj.io/sync-wave: "3" # App workloads last
spec:
# ...Without explicit sync waves, the ordering is tribal knowledge. It works when the engineer who built the cluster is in the war room. It fails when they are not.
IAM Permissions That Accumulated Beyond What the Pipeline Needs
The damage a compromised identity causes is bounded almost entirely by how the IAM design was built. In environments where CI/CD pipelines accumulate permissions without regular audits, a single compromised runner can reach AdministratorAccess on the production account and delete CloudTrail logs before any alert fires.
A GitHub Actions workflow that started with permission to push images to ECR three years ago now has sts: AssumeRole on a deployment role with AdministratorAccess, because someone added it temporarily during a migration and never removed it.
Short-lived OIDC-federated credentials keep blast radius bounded. A token that expires in 15 minutes after a pipeline run does far less damage than a long-lived access key with accumulated role assumptions:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::123456789:oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com",
"token.actions.githubusercontent.com:sub": "repo:company/app:environment:production"
}
}
}
]
}Scoped deployment roles that expire after the workflow completes, and explicit break-glass activation for administrative access, are not optional controls in environments where CI/CD pipelines touch production. These IAM sprawl patterns aren't unique to recovery scenarios, they're the same misconfigurations driving breaches across enterprise cloud environments generally; see our breakdown of enterprise cloud security risks for how identity misconfigurations, privileged Kubernetes pods, and exposed APIs compound at scale.
How Platform and SRE Teams Test Recovery Readiness
The four patterns above stay hidden until a rebuild is forced. By then, the incident is already active. The teams that recover in under two hours are the ones who already knew where each pattern existed in their environment, because they ran the tests before the incident hit.
Here is what that testing looks like in practice.
Test 1: Does Terraform actually rebuild a working environment?
Run Terraform apply from scratch against a clean staging account with no pre-existing resources. Most teams find the CLI exits with code 0 but the environment does not work: ingress controllers cannot attach to the ALB because an IAM role ARN changed six months ago, external-secrets pods start and immediately crash because the IRSA annotation references a role that was recreated with a different ARN after a migration, and inter-service calls fail because a security group rule for internal traffic was added manually and never committed to Terraform. The AWS console shows everything green. Nothing is actually reachable.
Test 2: How long does an RDS restore actually take, end to end?
Restore the RDS instance from a snapshot and measure the full sequence, not just the snapshot restore timer. The snapshot comes back in 35 minutes. Then the connection strings in Secrets Manager still point to the old endpoint. The cert-manager ClusterIssuer references the old Route53 hosted zone. The application health checks do not pass for another 90 minutes after the database is available. The DR plan says RTO is 1 hour. The actual time to work on production is 3.5 hours. If those numbers do not match, the DR plan is wrong, not the test.
Test 3: How long until the cluster is actually working, not just running?
Delete the EKS cluster. Rebuild it from Terraform and ArgoCD from scratch. Measure time until external-secrets is syncing from Secrets Manager, ingress is routing external traffic, and a cross-service API call succeeds end-to-end. Not until pods are in the running state does that milestone mean anything. The common finding: ArgoCD shows all applications synced within 20 minutes, but external-secrets is in CrashLoopBackOff because the IAM OIDC provider ARN in the ServiceAccount annotation does not match the one Terraform just created. The cert-manager ClusterIssuer is stuck waiting on a Secret that external-secrets has not synced yet. Three components waiting on each other, none failing loudly, all showing healthy in kubectl get pods.
Test 4: How quickly can the team contain a compromised CI role?
Mark a CI deployment role as compromised. Measure how long it takes to: query CloudTrail and identify every API call the role made in the last 24 hours, revoke the credentials, and confirm no persistent access was left behind via a new IAM user or a modified trust policy. The common finding: filtering CloudTrail for a specific role across a multi-account environment takes 45 minutes. When the query comes back, the role had sts:AssumeRole on two other roles nobody knew about, one of which has s3:PutObject on the backups bucket.
Test 5: Does the team have audit visibility if the logging pipeline goes down?
Kill the log aggregator. Check whether CloudTrail, VPC flow logs, and Kubernetes audit logs are still accessible or whether they were all delivered into the same aggregator that just went down. The common finding: the aggregator was also the CloudTrail delivery target. The team has no audit trail for the 40 minutes before the cluster failed. If a credential was compromised in that window, there is no record of which API calls were made.
Each of these tests will fail in at least one way the first time they are run. The environments that recover fastest under real incidents are the ones where the failures happened in a scheduled test first.
Existing Cyber Resilience Solution Categories
Those five tests expose a coverage problem in the existing tooling landscape. The market has four distinct solution categories, each addressing one layer of the recovery problem. None of them addresses the infrastructure-state layer.
Backup and Data Recovery Platforms
These platforms handle point-in-time data recovery, immutable snapshot storage, and ransomware recovery. They restore databases, VM volumes, and object storage reliably. What they do not restore: the Kubernetes operator dependency chains, the IaC module outputs, the IRSA role bindings, and the GitOps sync state the application depends on to start correctly. The data comes back. The infrastructure the application sits on does not.
Cloud Security Posture and Visibility Platforms
These platforms map attack paths, detect misconfigured IAM, and identify publicly exposed resources. They tell you that a workload has wildcard S3 permissions. They do not rebuild the IaC that should have scoped those permissions to a specific bucket prefix, and they do not detect when that IaC diverged from the runtime state six months after the initial deployment. They are visibility tools, not recovery tools. For the policy-as-code and continuous-monitoring side of this category, and how automation shifts it from periodic audits to real-time enforcement, see our guide to cloud security compliance automation.
Infrastructure-as-Code and GitOps Platforms
These platforms make infrastructure rebuildable from versioned, declared state and are foundational to any recovery strategy. But they depend entirely on the declared state being accurate. A resource patched directly with kubectl edit is invisible to GitOps reconciliation. An IAM trust relationship created manually in the cloud console cannot be rebuilt from a Terraform module that does not know it exists. These platforms are only as reliable as the discipline that keeps runtime state in sync with what is declared in Git.
Disaster Recovery Automation Platforms
These platforms handle region failover, snapshot replication, and workload migration sequencing. They work well for isolated infrastructure failures where the environment was clean before the failure. They do not work when recovery involves compromise, a failover that routes traffic to a secondary region does not address a CI pipeline still deploying from a compromised runner, and it does not reconstruct the unmanaged IAM roles and DNS records that were never part of the failover definition.
Across all four categories, the gap is the same: none of them maintains a continuous record of what the runtime infrastructure actually looks like. The WAF ACL was created manually in the console two years ago. The IAM role was added during a migration and never committed to Terraform. The Kubernetes resource was patched with kubectl edit during last month's incident. These exist in your production environment. They do not exist in any of these tools. When a forced rebuild comes, they are the reason production stays broken after the backup succeeds.
How Firefly Approaches Cyber Resilience Differently
Every tool category described above has the same gap: none of them maintains a continuous record of what the runtime infrastructure actually looks like. So none of them can tell you what will break before a rebuild, and none of them recover the infrastructure the application depends on, only the data it stores.
Before Firefly, recovering from a failed rebuild looked like this:
- An engineer notices that an IAM role referenced in a Helm values file does not exist in the new account
- They grep through CloudTrail to figure out when it was created and by whom
- They manually recreate the role, attach the correct policies, update the Helm values file, and redeploy
- Three hours later, they find the cert-manager ClusterIssuer is also referencing a hosted zone ID from the original account.
- They repeat the same trace-and-rebuild loop, once for each dependency that was never committed to Git.
That loop continues until every out-of-band dependency is found. In a production environment that has been running for two years, there can be ten or fifteen dependencies. Each one adds hours.
Firefly addresses this as two connected problems: knowing your recovery posture before an incident strikes, and recovering the full infrastructure, not just the data, when one does.
Cloud Resilience Posture Management (CRPM)
Before a rebuild is forced, Firefly gives platform teams a real-time view of what can and cannot be recovered. The Resiliency Posture dashboard scores your environment against built-in resiliency policies such as S3 buckets without versioning or object lock, EBS volumes without snapshots, EC2 instances without valid AMIs, and KMS keys without deletion windows. Here’s what the resiliency posture dashboard looks like, scanning all the live resources running:
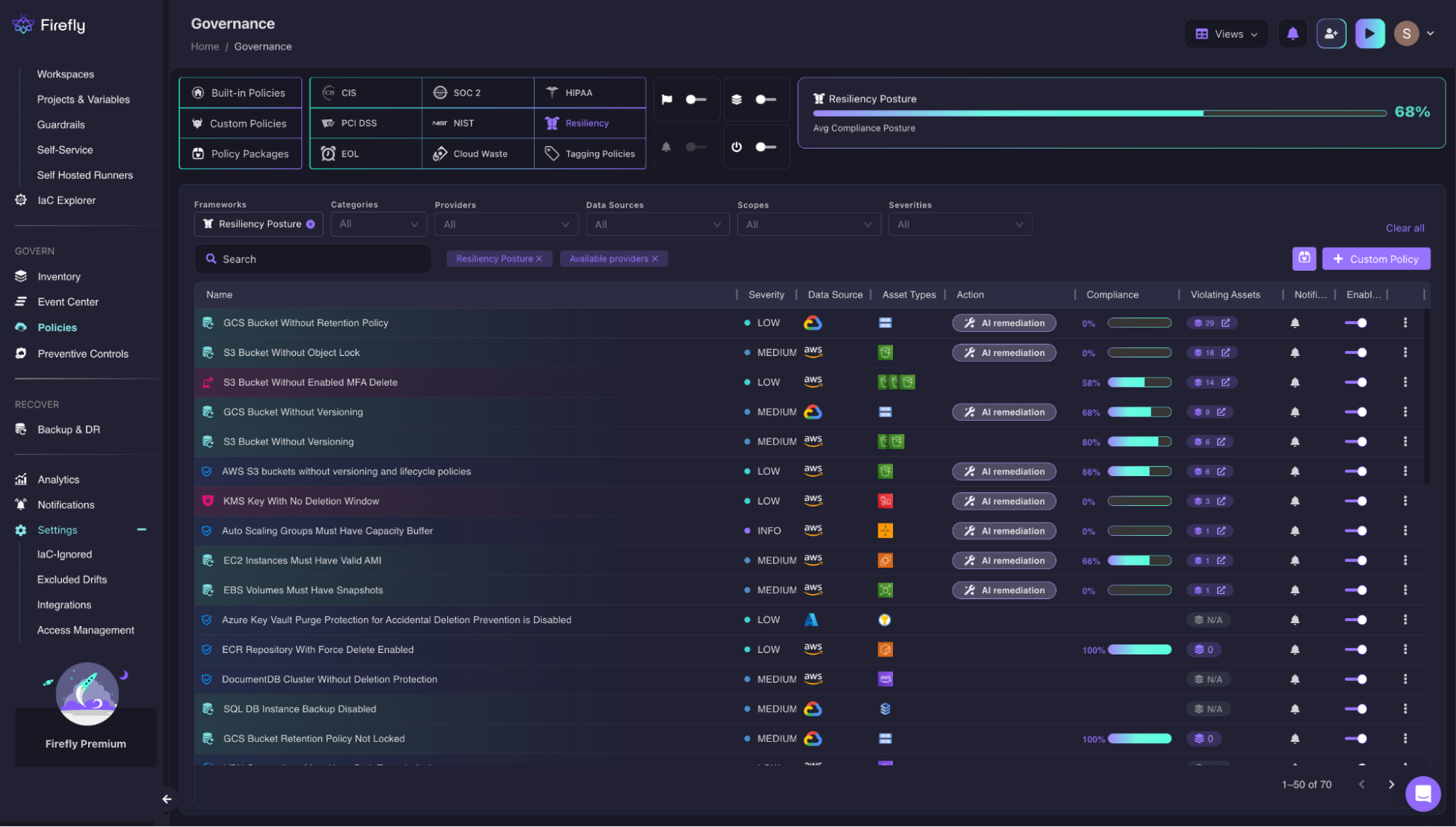
Each policy shows which assets are violating it and the current compliance percentage across your accounts. A team that knows their Resiliency Posture is at 68% before an incident knows exactly which 32% of their environment will fail to recover, and can remediate it before the incident forces the question. For a deeper look at CRPM as a discipline, how it blends disaster recovery, CSPM, and automation into one continuously enforced score, see our guide to cloud resilience beyond backups
Application Backup and DR
When Firefly takes a backup, it captures not just data volumes but the full infrastructure the application depends on: IAM roles, IAM instance profiles, EC2 instances, EBS volumes, KMS keys, Internet Gateways, Route Tables, and Key Pairs.
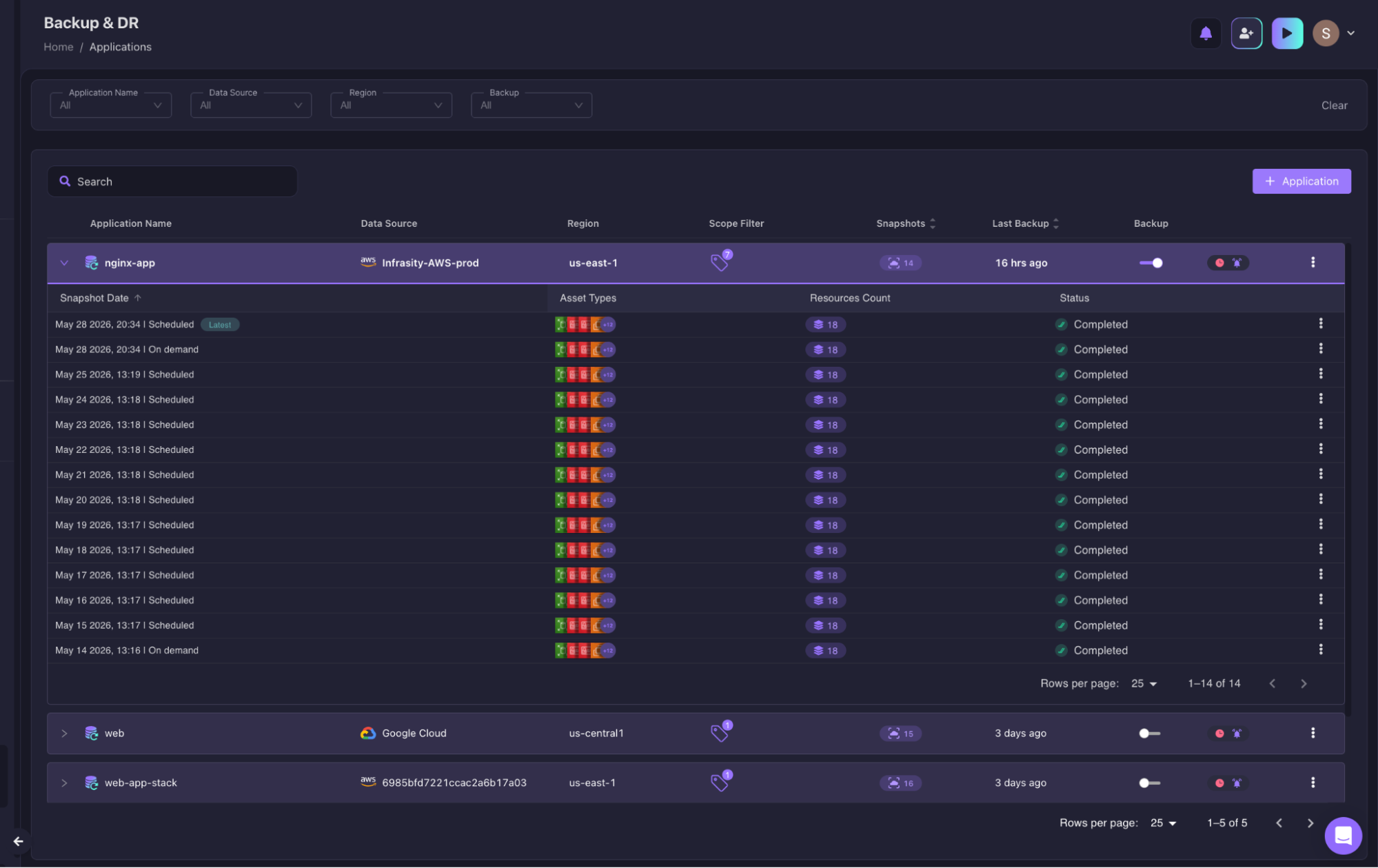
The assets that caused the four-hour recovery failure in the ransomware scenario earlier in this post, the IRSA role, the WAF ACL, and the DNS configuration, are exactly the category of infrastructure assets Firefly's Backup & DR is built to capture. The snapshot includes the full dependency graph of the application, not just its storage layer.
IaC-First Recovery
Recovery in Firefly does not directly mutate infrastructure. When a restore is initiated from a snapshot, Firefly generates Terraform code for the selected resources and opens a pull request against the team's Git repository on the target branch. The recovery is reviewed, versioned, and applied through the same IaC workflow the team uses for every other deployment. The restored infrastructure is immediately codified; it does not create new untracked resources that become the next recovery problem.
Recovery stops depending on the engineer who remembers which IAM role was created during the migration two years ago. The infrastructure state is recorded continuously, the backup captures the full dependency graph, and the restore produces auditable Terraform, not a manual recreation that becomes the next gap.
Practical Cyber Resilience Implementation
Firefly closes the infrastructure-state gap. But the teams that recover fastest combine tooling with a small set of engineering practices that make recovery predictable rather than heroic.
They treat Terraform apply from a clean state as a production readiness criterion, running it quarterly against a staging account with no pre-existing resources and validating that the result is a working environment, not just an environment where the CLI exits without errors.
They run drift detection continuously across all production accounts, treating unmanaged resources and IaC divergence as P2 issues rather than governance findings to be reviewed in a monthly compliance report.
They scope IAM to the minimum permissions required for each pipeline step, using OIDC federation to issue short-lived credentials instead of long-lived access keys, and audit sts:AssumeRole usage in CloudTrail to catch permission creep before it becomes blast radius.
They validate backup restores end-to-end on a schedule, not by checking that the backup job completed, but by actually restoring a snapshot into a clean environment and confirming that the application can read from the database before deleting the test environment.
They treat Kubernetes dependency ordering as explicit, not tribal knowledge, encoding sync waves in ArgoCD Applications, using init containers to gate on dependency readiness, and documenting restoration sequence in a format that survives the departure of the engineer who originally built the cluster. None of these practices requires new tooling. Most require reclassifying drift detection, IAM scoping, and restore validation from governance findings to production readiness criteria. The infrastructure that recovers predictably is the one designed to be rebuilt. That is the engineering decision that determines whether a bad incident becomes a recoverable one.
Frequently Asked Questions
What is cyber resilience?
Cyber resilience is the ability of a cloud platform to continue operating and recover to a trusted state after a failure, whether that failure is a ransomware attack, a corrupted Terraform state, a compromised CI credential, or a cascading service outage. It goes beyond data recovery. A platform that restored its RDS instance but cannot authenticate to Secrets Manager or route traffic through the ALB has the data back, but not cyber resilience.
What are the 5 pillars of cyber resilience?
In cloud infrastructure, the five pillars are: blast radius containment (scoped IAM, isolated namespaces), infrastructure rebuildability (runtime state in sync with declared IaC), operational continuity (multi-region replication and automated failover), trusted state restoration (recovering IAM roles, DNS configs, and Kubernetes dependencies alongside data), and observability survivability (audit logs that remain accessible even when the logging pipeline goes down).
What are the 4 types of resilience?
Infrastructure resilience, rebuilding from IaC state, including resources that exist outside Terraform. Application resilience, workloads that degrade gracefully under load without cascading across services. Security resilience, containing a compromised credential and restoring trusted operations before persistent access is established. Data resilience, backup, and restore with validated RTO that reflects actual end-to-end recovery time, not just the snapshot timer.
What are the 3 C's of resilience?
Codification: Every resource that needs to survive a rebuild must exist in Terraform or a GitOps manifest, not only in the AWS console. Continuity, backup that covers IAM roles, Route Tables, and KMS keys alongside data volumes. Continuous validation, recovery capability tested on a schedule against the actual RTO, not assumed to work because the backup job shows green.

.avif)
.avif)
.webp)

.webp)

















