
TL;DR
- Hybrid cloud is not defined by where infrastructure runs; it's defined by whether private infrastructure and public cloud share the same identity, networking, security, and governance layer
- Organizations end up with a hybrid cloud through workload-level decisions: compliance requirements, legacy dependencies, latency constraints, and cost structures, not a top-down architecture strategy
- The hardest problems in hybrid cloud aren't provisioning resources across environments; they're tracking what exists, who owns it, whether it matches IaC, and what depends on what across provider boundaries
- Firefly solves this by maintaining a real-time inventory across AWS, GCP, Kubernetes, and on-premises, tracking IaC coverage, detecting drift the moment it happens outside Terraform, and mapping cross-provider dependencies before a change breaks them
A few months ago, someone posted on r/Cloud asking a simple question: What exactly is hybrid cloud architecture?
The thread drew 15 comments, but the discussion wasn't really about the definitions of hybrid cloud. Most of the answers pointed to a practical reality that some workloads are easier to run in the cloud, while others are better left where they are.
An organization might run customer-facing applications in AWS while keeping databases in a private data center. A machine learning team may adopt Vertex AI for model training and BigQuery for analytics, while customer-facing services, internal APIs, and operational databases remain on existing infrastructure. Regulatory requirements, latency constraints, data gravity, and years of investment in existing systems all influence where workloads end up living.
The result is an environment where applications, data, and operational responsibilities are spread across public cloud and private infrastructure. That's hybrid cloud in practice, not as a vendor diagram, but as an operating model.
And that's where the real challenges begin. Once services, networks, identities, and data span multiple environments, teams must manage cross-platform observability, security, connectivity, governance, and operational complexity.
This article covers what hybrid cloud infrastructure actually is, why organizations end up running it, how the architecture is structured, and what the real operational challenges look like at scale.
What is a Hybrid Cloud Infrastructure?
A hybrid cloud is commonly defined as a combination of private infrastructure and public cloud services. That definition is technically correct but operationally incomplete.
Running workloads in two different environments doesn't automatically create a hybrid cloud architecture. If your organization has a VMware cluster in a data center and a separate AWS account hosting a few applications, those environments are simply coexisting. They are not necessarily operating as a unified platform.
A hybrid cloud environment exists when workloads, applications, data, and operational processes span multiple infrastructure environments and depend on shared services to function.
The important word there is depend. The environments are not isolated. They communicate. They share identity systems. They depend on the same networking layer. An incident in one environment can affect services running in another.
At a high level, the architecture looks like this:
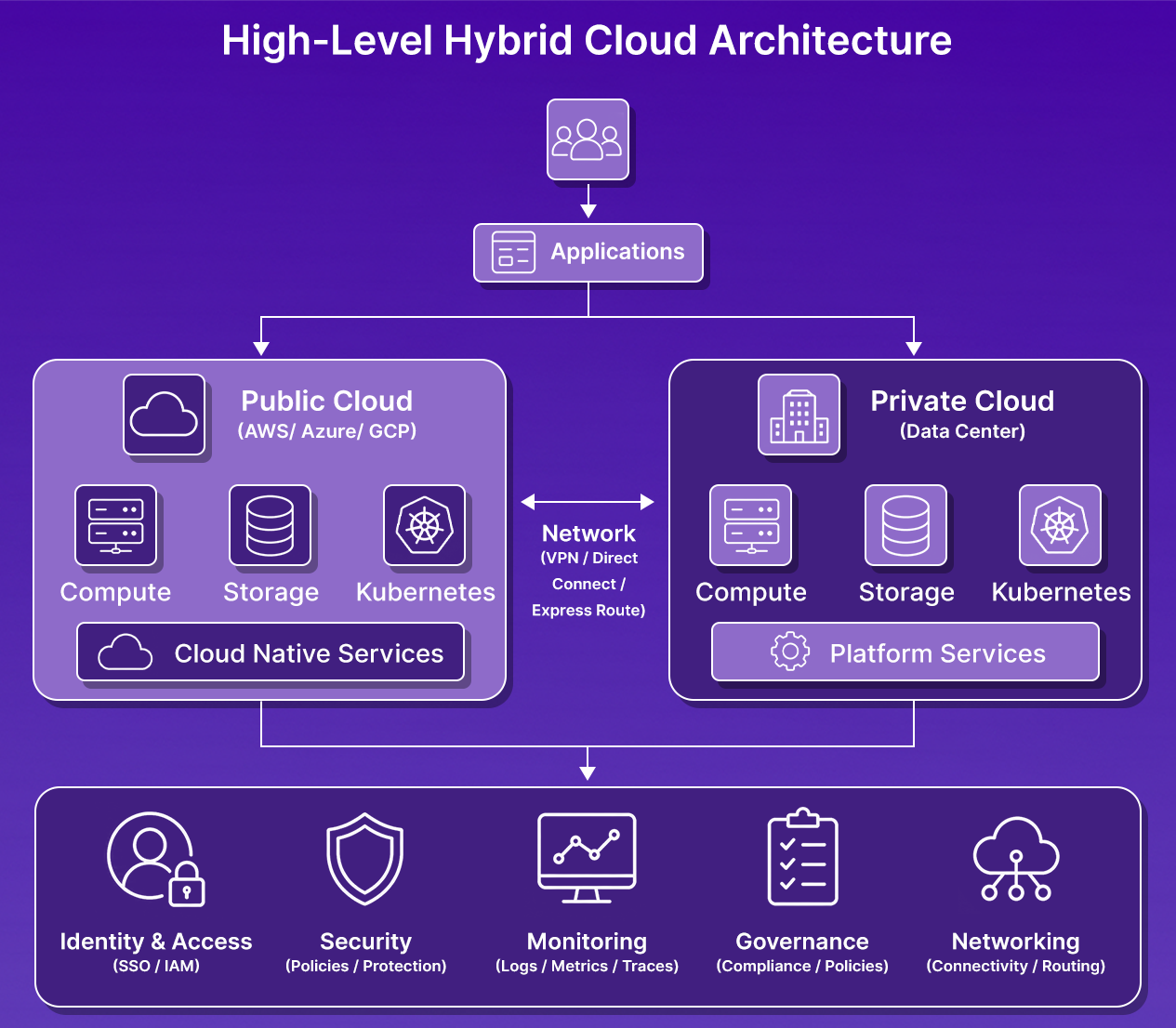
The infrastructure itself, the virtual machines, the databases, and the Kubernetes clusters, is not the hard part. Most teams can provision those. The challenge lies in the underlying layer: the shared systems and processes that enable multiple environments to operate as a single operating model.
A user accessing an application should authenticate through the same identity provider regardless of where the workload runs. A security team should be able to enforce baseline controls without maintaining separate processes for each platform. An SRE troubleshooting a production incident should have visibility across the entire request path, not separate dashboards per environment.
Without those shared capabilities, every environment becomes its own operational island. That is where hybrid cloud gets expensive to operate.
Why Organizations Shift to Hybrid Cloud Infrastructure?
Organizations don't choose hybrid cloud for its own sake. Specific workload properties, legacy dependencies, regulatory restrictions, latency requirements, and cost structures make it either technically impossible or economically unjustifiable to place everything in a single cloud provider.
Six drivers explain why most enterprise infrastructure ends up spanning multiple environments. Each one forces a placement decision at the workload level, and each placement decision creates operational requirements that infrastructure teams carry long after the original decision was made.
1. Legacy Apps Tied to Proprietary Systems Require a Full Redesign to Move to the Cloud
Many ERP systems, financial platforms, and manufacturing applications were built before cloud-native architectures existed. They depend on specific operating systems, proprietary software, tightly coupled integrations, or fixed hardware configurations that the public cloud cannot replicate without rebuilding the application from scratch. For most organizations, keeping these workloads on-premises while modernizing everything around them is cheaper and faster than a full redesign.
2. HIPAA, GDPR, and Sector-Specific Regulations Restrict Where Certain Data Can Live
Healthcare, financial services, and government organizations operate under regulations that specify where data can be stored, processed, and accessed, and who can inspect the infrastructure handling it. Public cloud providers offer compliance certifications, but they don't give organizations control over the underlying hardware, the physical access audit trail, or the ability to satisfy regulators who require infrastructure to be wholly owned. Retaining regulated workloads in private environments is a compliance requirement, not a conservative preference.
3. Manufacturing and Edge Systems Can't Absorb Public Cloud Round-Trip Latency
Industrial control systems, real-time sensor processing at manufacturing facilities, and edge AI inference need to act on data in milliseconds. Routing that data to a cloud region before processing introduces latency that breaks the application's core function; a factory floor safety system can't wait 40ms for a cloud API response. Running these workloads at edge locations or within local facilities is an architectural constraint dictated by physics, not a deployment preference.
4. Stable, High-Utilization Workloads Cost Less on Fixed-Price Private Infrastructure
Pay-as-you-go cloud pricing is built for variable demand. For workloads running at consistent utilization, internal databases, batch processing pipelines with fixed schedules, core business applications with predictable traffic, the per-hour cost of public cloud over three years frequently exceeds the amortized cost of owned hardware. Organizations that run total-cost-of-ownership analyses for high-utilization workloads often find private infrastructure cheaper in those cases, even after accounting for operational overhead.
5. Migrating Hundreds of Apps With Uneven Technical Debt Takes Years, Not Quarters
A large enterprise typically operates hundreds of applications with different owners, codebases, dependency trees, and levels of technical debt. Moving all of them to public cloud is a multi-year program, not a project. During that window, which often stretches five to seven years, some applications have completed migration, others are mid-flight, and some will never move. Hybrid cloud is the operating model that exists during and after that transition, not a temporary state on the way to something else.
5. Public Cloud DR Environments Deliver Redundancy Without a Secondary Data Center
Maintaining a secondary physical data center purely for disaster recovery is expensive: hardware, colocation fees, networking, and staff to keep it current. Running DR environments in AWS, Azure, or GCP provides organizations with geographic redundancy and on-demand recovery capacity at a fraction of the cost. The primary workloads stay on-premises or in a private environment; the recovery environments live in the cloud and activate only when needed.
The pattern that runs through all six drivers: nobody decides at the organization level that the company should run a hybrid cloud. They decide, on a workload-by-workload basis, that this ERP system stays on-premises, that this analytics service runs in GCP, and that this database stays in a private environment for compliance. Those individual decisions add up to a hybrid cloud estate.
What Are the Different Types of Hybrid Cloud Infrastructure?
Engineers picture a hybrid cloud as two environments: an on-premises data center connected to a single public cloud provider like AWS. In practice, a mature enterprise estate rarely stops there. It typically spans five distinct infrastructure types: on-premises data centers, private cloud platforms, multiple public cloud providers, edge deployments, and SaaS control planes, each running different workloads, managed through different tooling, and governed by different access models. Every additional infrastructure type means another set of credentials to manage, another monitoring integration to maintain, and another policy framework to keep synchronized.
On-Premises Data Centers Run the ERP, Financial, and Manufacturing Systems That Predate Cloud
Physical servers, storage arrays, networking equipment, and virtualization platforms hosted in company-operated data centers form the oldest layer of most enterprise estates. SAP deployments, core banking systems, and factory floor control systems live here, not because nobody thought to move them, but because they were built with hardware-specific dependencies, proprietary middleware, or fixed network architectures that the public cloud can't replicate without rebuilding the application. These systems often have uptime requirements and compliance obligations that make migration a multi-year commitment, not a project sprint.
VMware and OpenStack Environments Deliver Self-Service Provisioning Without Exposing Data to Public Cloud
Private cloud sits between traditional data centers and public cloud. The infrastructure stays under the organization's control, but resources are delivered through self-service portals, APIs, and automation pipelines rather than being manually provisioned by an ops team. VMware-based private clouds, OpenStack environments, and internal Kubernetes platforms fall into this category. Banks, hospitals, and defense contractors use private cloud to give application teams faster provisioning cycles without placing regulated data on hardware they don't own or can't inspect.
AWS, Azure, and GCP Each Host Different Workloads Because Different Teams Made Independent Adoption Decisions
Public cloud carries customer-facing applications, containerized workloads, data pipelines, and analytics platforms. The reason most organizations end up across multiple public cloud providers isn't strategy; it's that different teams evaluated different services at different times and picked what fit their requirements. The data team adopted GCP for BigQuery. The product team standardized on AWS. The enterprise integrations team moved to Azure because the organization already ran Microsoft 365. Those decisions are rarely reversed, which means multi-cloud isn't a choice so much as an accumulated outcome.
Factory Floors and Retail Sites Run Local Compute. When Sending Data to a Cloud Region Would Break the Application
Edge deployments exist because some workloads can't tolerate the latency of a public cloud round-trip. A conveyor belt sensor system that needs to detect a fault in under 10ms can't route that decision through an AWS region. A point-of-sale terminal in a retail store needs to process transactions even when the WAN link is degraded. These workloads run on local hardware at manufacturing facilities, hospitals, telecommunications sites, and distribution centers, and that hardware needs to be patched, monitored, and governed with the same rigor as anything else in the estate.
When the Identity Provider Goes Down, Cloud Consoles, Kubernetes Clusters, and VPNs All Lose Access Simultaneously
SaaS platforms are rarely listed in infrastructure architecture diagrams, but they function as control points for the entire estate. Okta or Microsoft Entra ID handles authentication for AWS IAM role federation, Kubernetes OIDC, VPN access, and internal tooling. Datadog or New Relic aggregates telemetry from every environment. GitHub holds the IaC definitions that describe what should exist. ServiceNow or Jira tracks who approved what change. These platforms don't sit outside the hybrid estate; they're the connective tissue that holds operational workflows together across every layer of it.
The hard part is maintaining a consistent identity model, a unified governance policy, and a single observability pipeline across all five simultaneously, without any of them having a native way to talk to the others.
What Is the Difference Between Hybrid Cloud and Multi-Cloud?
These terms are often used interchangeably. They describe different things.
Hybrid cloud is defined by the presence of private infrastructure, an on-premises data center, a VMware cluster, and a private Kubernetes platform integrated with public cloud. Multi-cloud is defined by running workloads across two or more public cloud providers.
Most large enterprises are running both without having made an explicit decision to do so. A bank with SAP on VMware in its own data center, customer-facing services on AWS, enterprise identity on Azure AD, and analytics on GCP is running hybrid cloud and multi-cloud simultaneously. Those aren't alternative labels for the same environment; they're two overlapping descriptions of different dimensions of it.
The reason the distinction matters is tooling scope. A platform built for multi-cloud management, Terraform Cloud, for example, can provision and track resources across AWS, Azure, and GCP from a single workflow. What it cannot do is give visibility into the VMware cluster in the data center, the Active Directory groups controlling access to on-premises systems, or the physical network path between the colocation facility and the AWS Direct Connect endpoint. Hybrid cloud operations require tooling that covers the private infrastructure layer, on-premises networking topology, physical compliance boundaries, legacy system dependencies, and cross-environment governance, not just the public cloud layer. A team that buys a multi-cloud tool to solve a hybrid cloud problem will find it covers roughly half their estate.
4 Problems That Only Appear When Infrastructure Spans More Than One Environment (Hybrid Cloud)
The AWS-to-GCP analytics migration from earlier produced one cross-cloud dependency. Six months later, that single migration had generated orphaned EC2 instances, an undocumented IAM role, a Terraform state that no longer matched production, and a dependency that only surfaced when a database upgrade broke the analytics pipeline.
These aren't edge cases. They're what happens when infrastructure grows faster than operational visibility, and hybrid cloud accelerates that gap because no single platform has visibility across all environments simultaneously.
EC2 Instances and GCP Resources Created Outside Terraform During a Migration Stay Running Because No Tool Shows the Complete Inventory Across Both Providers
During the analytics migration, an engineer provisioned a t3.large EC2 instance in AWS to test cross-cloud connectivity, through the console, not Terraform. A GCP Compute instance was spun up to validate BigQuery output before the service went live. Both were meant to be temporary. Neither was cleaned up when the project closed.
Six months later, both instances are still running. The engineer who created them moved to another team. CloudTrail shows the EC2 instance was last accessed four months ago, but that doesn't tell you whether a GCP service still calls it. Terraform has no record of either resource; they don't appear in terraform state list. In a single AWS account, you can cross-reference CloudWatch logs, VPC flow logs, and Terraform state in one console. When one resource is in AWS, and the dependency that might reference it is in GCP, that cross-reference requires pulling data from two separate platforms with no shared inventory between them.
Cross-Cloud IAM Roles Created During a Migration Have No Owner After the Engineer Who Configured Them Moves Teams
The analytics migration required an AWS IAM role that allowed the GCP service account to read from S3 and query RDS. The engineer who created it is now on a different project. The role is still active with broad S3 read permissions that were scoped for migration testing and never tightened for production.
During a quarterly access review, the security team finds the role in AWS IAM. They can see it exists. They can't immediately tell which GCP service account is using it, whether that service account is still active, or whether removing the role would break the production analytics pipeline. Answering those questions requires checking AWS IAM, GCP IAM, the GCP service account bindings, and the analytics service's runtime config, four separate systems with no native visibility into each other.
A Security Group Fixed Through the AWS Console During a 2 am Incident Permanently Splits Terraform State From What's Running in Production
The analytics pipeline stops receiving data from RDS at 2 am. An on-call engineer opens the AWS Console, finds a misconfigured inbound rule on the RDS security group, fixes it directly, and closes the incident. The fix is correct. It never gets committed back to the Terraform module that manages the security group.
Three weeks later, the platform team runs terraform plan as part of a routine database parameter change. Terraform flags the manual security group change as drift and proposes reverting it. An engineer who doesn't recognize the context approves terraform apply. The misconfiguration that caused the original incident gets reintroduced. In a single-environment deployment, drift shows up in one state file against one provider API. In a hybrid environment where RDS is in AWS, the analytics service is in GCP, and the network path crosses a Direct Connect, the context for why a specific security group rule matters doesn't live in any single tool, which means drift gets reviewed without the information needed to evaluate it safely.
The Direct Dependency Between the GCP Analytics Service and the AWS RDS Instance Only Becomes Visible When the Upgrade Breaks the Pipeline
Eighteen months after the migration, the platform team plans a PostgreSQL 13 to 16 upgrade on RDS, a 20-minute maintenance window. They identify every internal AWS service querying RDS from Terraform: eleven services, all documented. What they don't identify is that the GCP analytics service also queries RDS directly through a Direct Connect path, using a read replica endpoint added six months after the original migration and documented only in a Confluence page last updated eight months ago. During the maintenance window, the analytics pipeline fails silently. The data team reports missing dashboards the following morning.
That dependency wasn't in the AWS Console, Terraform state, or GitHub because it was created at runtime, crosses a provider boundary, and was added outside the IaC workflow. Tracing it after the fact requires correlating AWS VPC flow logs, GCP service account audit logs, and Direct Connect traffic data across two cloud providers with separate logging pipelines.
How Firefly Becomes the Single Source of Truth for Hybrid Cloud Infrastructure
Without a unified system of record, answering "what resources exist across our AWS accounts, GCP project, and on-premises infrastructure" means opening four separate consoles, cross-referencing Terraform state files, querying CloudTrail and GCP audit logs independently, and accepting that the answer is only as current as the last time someone did that exercise manually. The t3.large EC2 instance from the migration stays running. The IAM role with no owner doesn't get reviewed. The security group fix at 2 am gets reverted three weeks later. The RDS upgrade breaks the GCP analytics pipeline.
Firefly replaces that workflow with a continuous scan that maintains a real-time inventory across AWS, Azure, GCP, Kubernetes, and on-premises simultaneously, so the questions that previously required five tools and a Slack thread have a single answer.
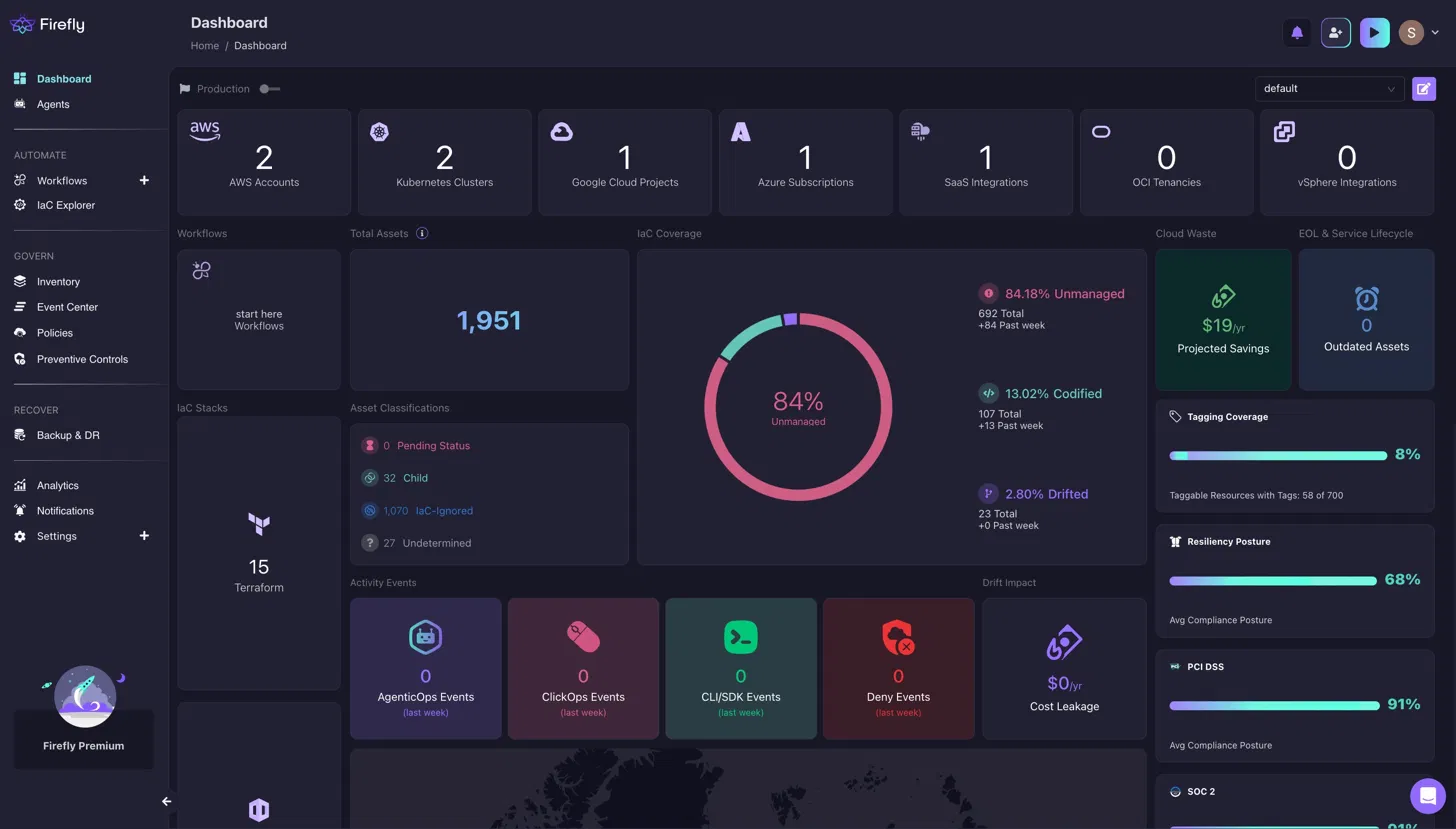
The dashboard above shows what Firefly sees across a real multi-cloud environment: 1,951 total assets, 84% unmanaged, 23 drifted resources, and compliance posture tracked continuously across PCI DSS and SOC 2, without anyone manually pulling that data together.
Firefly's Inventory Shows Every Unmanaged Resource Across AWS, GCP, and Kubernetes in One View
Every resource Firefly discovers, including the t3.large EC2 instance provisioned through the AWS Console during migration testing, appears in the inventory with its IaC status: Codified (exists in a Terraform state file), Unmanaged (exists in production with no corresponding Terraform definition), or Drifted (exists in Terraform but production no longer matches). For resources flagged as Unmanaged, Firefly can automatically generate Terraform or OpenTofu code by inspecting the running resource's configuration and producing the equivalent HCL, turning a console-created EC2 instance into a version-controlled resource without manual rewriting. Based on the snapshot below:
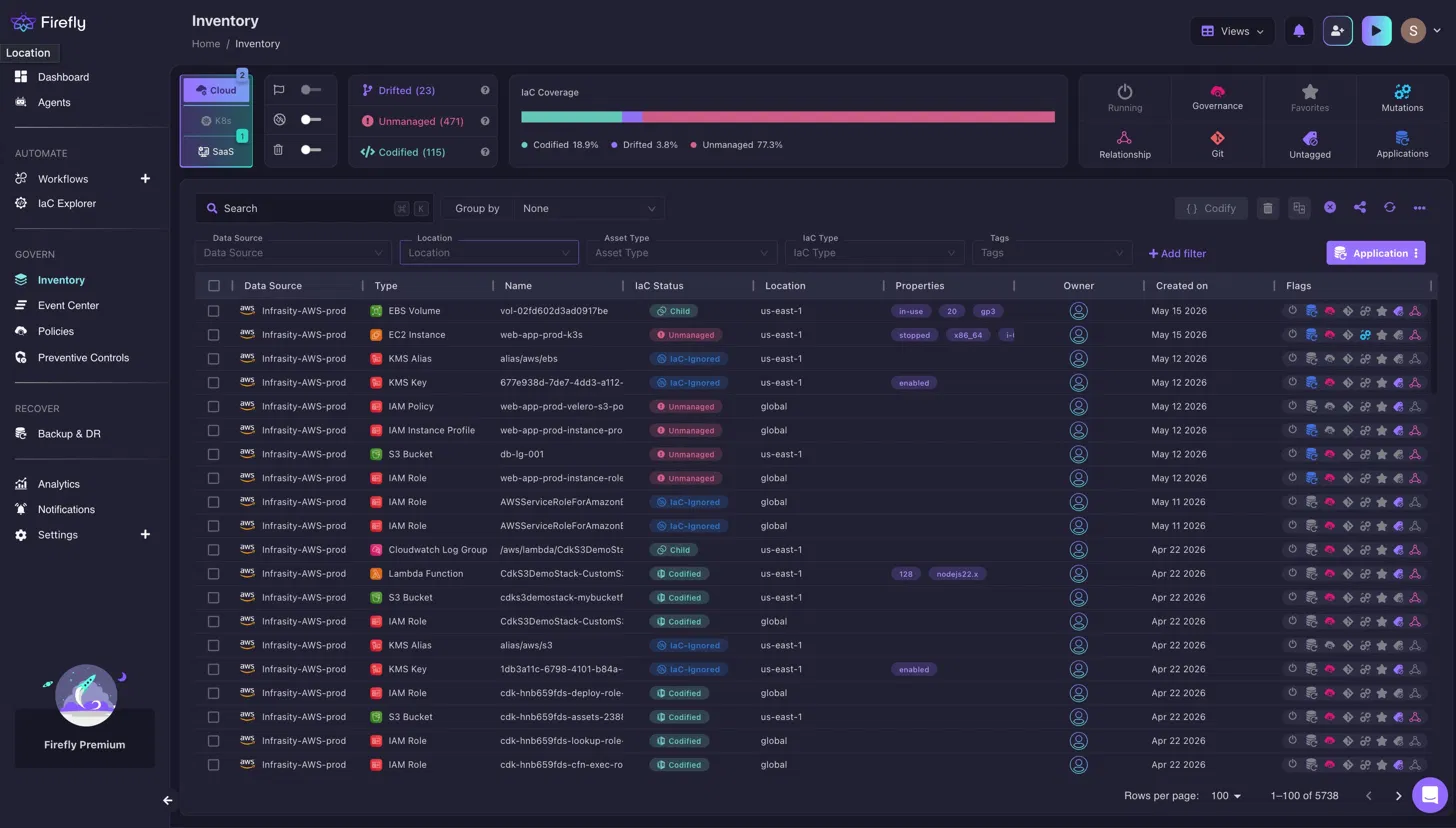
The inventory above shows 5,738 resources across a single AWS account. The IaC Status column makes the coverage gap immediately visible, such as IAM roles, S3 buckets, and EC2 instances sitting as Unmanaged alongside fully Codified Lambda functions and IaC-Ignored KMS keys. Without this view, an engineer reviewing the same account in the AWS Console sees all 5,738 resources, with no indication of which are known to Terraform.
Event Center Tracks Every Console Change With Owner Attribution
When an engineer opens the AWS Console and updates the RDS security group inbound rule at 2 am, Firefly's Event Center records the change, the specific resource modified, the AWS account it belongs to, the IAM identity that made the change, and the exact timestamp. Ownership is assigned based on provisioning and change history, not from a wiki page that may be six months old. When the security team finds the AWS IAM role created during the GCP migration during a quarterly access review, Firefly surfaces which GCP service account is bound to it and when the role was last used, without manually querying AWS IAM, GCP IAM, and the service account audit logs separately.
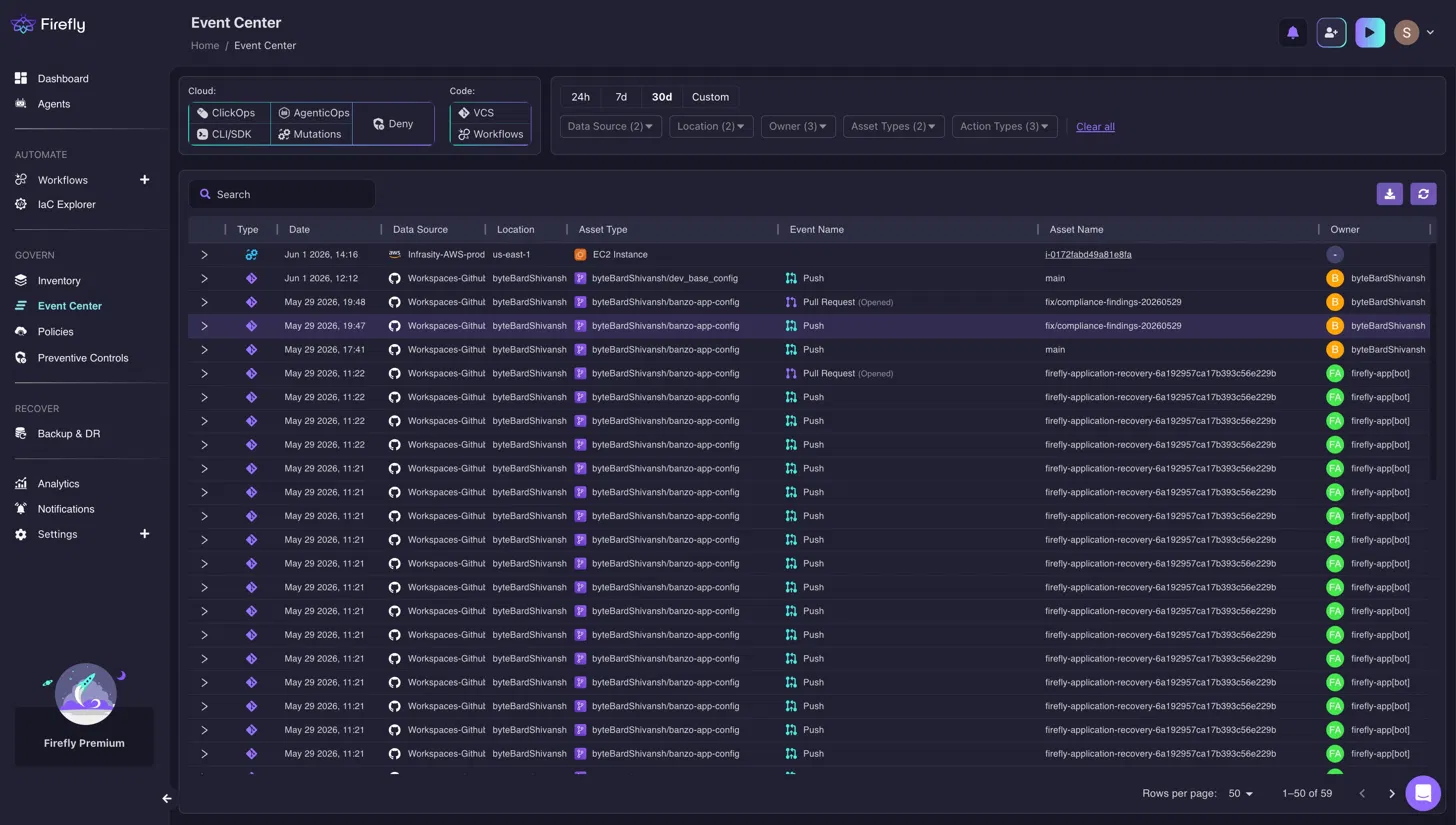
The Event Center above shows exactly what is captured when a change occurs outside Terraform: the EC2 instance modified in the Infrasity-AWS-prod account on Jan 1, 2026, at 14:16, attributed to a named owner. Every ClickOps change, CLI mutation, and AgenticOps event is logged the same way, filterable by data source, location, asset type, and owner across every connected provider.
Maps Cross-Provider Dependencies Before a Change Breaks Them
Firefly builds a dependency graph across provider boundaries by correlating resource configurations, network paths, IAM bindings, and runtime relationships. The read replica endpoint that the GCP analytics service queries through Direct Connect, added outside the IaC workflow and documented only in an outdated Confluence page, appears in Firefly's dependency map as a live relationship between the GCP service account and the AWS RDS read replica. Before the PostgreSQL upgrade maintenance window runs, a platform engineer queries Firefly for every resource depending on the RDS instance and gets back not just the eleven internal AWS services in Terraform, but the GCP analytics service querying it across the provider boundary.
The AWS Console, Terraform state, and GitHub each answered one part of that question. Firefly answers all four: what exists across every provider, who owns it, whether it matches its Terraform definition, and what depends on it before a change runs.
FAQs
What is an example of a hybrid cloud?
A bank running its core transaction processing system on on-premises infrastructure for regulatory compliance, while hosting its customer-facing mobile banking application on AWS and running fraud detection workloads on GCP, is a real-world hybrid cloud. The private infrastructure handles data that can't leave the organization's control. The public cloud handles workloads that benefit from elastic scaling and managed services. Both environments share the same identity provider, monitoring pipeline, and governance policies.
Is Netflix a hybrid cloud?
Netflix runs almost entirely on AWS, which makes it a public cloud deployment rather than a hybrid cloud. Hybrid cloud requires private infrastructure, an on-premises data center, a private Kubernetes platform, or a colocation environment, integrated with public cloud. Netflix migrated away from its own data centers to AWS between 2008 and 2016, so it no longer maintains the private infrastructure layer that defines a hybrid cloud. Organizations like banks, hospitals, and manufacturers that retain on-premises systems alongside AWS or GCP are closer examples of hybrid cloud in practice.
What is the difference between cloud and hybrid cloud?
Cloud typically refers to running workloads entirely on a public cloud provider like AWS, Azure, or GCP, with no privately owned infrastructure involved. Hybrid cloud means at least part of the infrastructure runs on hardware the organization owns or directly controls, integrated with public cloud through shared networking, identity, and governance. The key difference is the presence of private infrastructure: a company running everything on AWS is cloud-only; a company running its database on-premises while its application tier runs on AWS is hybrid cloud.
Which are the most common uses of hybrid clouds?
The most common use cases are disaster recovery, where production workloads run on-premises and recovery environments run in AWS or Azure, gradual cloud migration where some applications have moved, and others haven't yet, compliance-driven workloads where regulated data must stay in private infrastructure while non-regulated services run in public cloud, and cost optimization where predictable high-utilization workloads run on owned hardware while variable-demand workloads use cloud elasticity. Most enterprises running a hybrid cloud are doing several of these simultaneously rather than choosing one.
.webp)


.webp)















