
TLDR
- The cloud AI market is growing at 39.3% CAGR, from $121 billion in 2025 to a projected $1.7 trillion by 2033. Every dollar of that growth lands on cloud infrastructure that needs to be governed, not just models that need to be audited.
- AI governance covers two layers: model governance (fairness, bias, explainability) and infrastructure governance (configuration, drift, access controls, policy enforcement). Most programs actively control the first and leave the second unmonitored until something breaks.
- AI workloads break audit-cycle governance because they move faster and span more resource types than any other workload. By the time the quarterly scan runs, the inference endpoint is already misconfigured, the training bucket is already unencrypted, and the IAM role already has permissions nobody approved.
- Firefly governs the infrastructure layer at all three points where it breaks: blocking non-compliant deployments before they land, catching drift and policy violations the moment they occur at runtime, and closing violations through the same PR workflow engineers already use.
A month ago, a cloud architect posted on r/cloudcomputing: "Should AI governance be part of cloud governance or handled separately?"
The thread surfaces a real split: folding AI governance into existing IAM, data classification, and spend controls feels consistent, but AI workloads introduce a risk surface that does not behave like traditional cloud workloads.
The answer depends on which layer of AI governance you mean. Model governance, bias detection, explainability, and lifecycle management belong with the ML team and need tooling that most cloud programs do not carry. Operational governance, infrastructure configuration, drift detection, and policy enforcement are cloud governance. Separating that layer leaves the infrastructure running your AI workloads outside the compliance controls applied to everything else.
This guide covers how AI governance works across all three layers, such as governing model behavior, governing the data that trains it, and governing the cloud infrastructure it runs on, who owns each layer, and why the infrastructure layer is where most teams have undetected drift, ungoverned resources, and compliance gaps they only discover during an incident. Governance is one pillar of a much larger adoption problem, though - for the fuller roadmap covering planning, MLOps integration, and rollout alongside this governance layer, see our guide to building an enterprise AI strategy.
What Is AI Governance?
AI governance is how an organization stays in control of its AI systems in production, the Bedrock agents autonomously handling customer requests, the SageMaker inference pipelines scoring fraud risk on every transaction, the RAG pipelines retrieving from vector databases to answer internal queries, and the multi-agent workflows orchestrating data retrieval, summarization, and action execution across AWS services.
For every one of those systems, governance means four things, and each one has a specific failure mode that shows up as a named policy violation before it becomes an incident:
1. Who and what can access it
A Bedrock customer support agent runs under an IAM execution role scoped at build time to cover every tool it might ever need. The trust policy was never restricted to a specific principal; any identity in the account can assume it. That is a live IAM Role That Allows All Principals to assume a violation at MEDIUM severity from day one. Add a cross-account deployment without an ExternalId condition, and it becomes Cross-Account IAM Assume Role Policy Without ExternalId or MFA at HIGH, the agent's execution role assumable from any account, by any identity, with no MFA requirement.
2. Whether the resources it runs on are configured correctly
The S3 bucket storing customer receipts, the one the agent reads on every refund request, was provisioned without a bucket policy restricting access to the agent's execution role. That is S3 Bucket Access to Any Principal at CRITICAL, and S3 Bucket Allows Get Action From All Principals at HIGH. The VPC the RDS instance sits in has flow logs disabled, no audit trail for any of the agent's rds-data:ExecuteStatement calls. That is VPC FlowLogs Disabled at MEDIUM. The KMS key encrypting the receipts bucket has no deletion window. KMS Key With No Deletion Window: The key protecting every receipt the agent reads can be deleted instantly with no recovery period.
3. Whether every change to its infrastructure is tracked
An engineer changed a security group rule on the RDS instance at 11 pm during a production incident and never reverted it. The VPC has no network firewall, VPC Without Network Firewall at MEDIUM. CloudWatch has no retention period on the Lambda handling tool dispatch, CloudWatch Without Retention Period Specified. The logs that would attribute that 11 pm change to a specific identity have already been purged by the time the SOC 2 auditor asks. That same attribution problem gets sharper once an AI agent, not a person, is the one making the change - CloudTrail records the API call but not that an agent decided to make it, which is its own governance gap; see our breakdown of AI governance solutions for what it takes to attribute and audit agent-driven cloud changes specifically.
4. Whether the model behaves consistently over time
The agent's instruction-following accuracy on refund policy questions dropped from 94% to 71% after a base model update. No drift detection is running. The degradation ran for two weeks before a customer escalation surfaced it, because behavioral drift lacks an equivalent to a named policy violation that fires the moment a threshold is crossed.
The first three failures are infrastructure configuration states, deterministic, nameable, and detectable the moment they occur. The fourth is a behavioral evaluation problem that requires a different enforcement mechanism. Both need to run simultaneously on every AI system your platform team owns.
The two layers every AI governance program needs
Model governance answers: Is the AI system producing the outputs it is supposed to produce? The enforcement mechanism is statistical, comparing output distributions against a training baseline and alerting on divergence. Tools like IBM OpenScale, Databricks Unity Catalog, and AWS AI Service Cards operate here. They cannot tell you whether the receipts bucket has a public ACL, whether the agent's execution role is assumable by any principal, or whether VPC flow logs are disabled on the RDS instance it queries.
Infrastructure governance answers: Are the cloud resources that the AI system depends on in the exact configuration state that the policy requires? The enforcement mechanism is deterministic, S3 Bucket Access to Any Principal either fires or it doesn't. IAM Role Allows All Principals To Assume is either open or it isn't. There is no distribution to sample; there is a resource attribute and a policy rule, and the delta between them is the violation.
Turning off either one leaves a category of failure with no detection running, the model governance layer catches the 94% to 71% accuracy drop; the infrastructure governance layer catches the IAM Role Allows All Principals To Assume violation, the S3 Bucket Access to Any Principal on the receipts bucket, and the missing VPC flow logs on the RDS instance, the moment each one appears, not months later when an auditor asks.
Why Your Existing Governance Stack Misses AI Workload Violations
Cloud governance programs were built for application workloads that change on a weekly release cycle. AI workloads do not behave that way. A single model training run provisions GPU instances, S3 buckets, IAM execution roles, and VPC endpoints, often outside the Terraform pipeline, often in non-production accounts that governance tooling does not scan, and often by ML engineers who are not thinking about SOC 2 controls when they are hitting a training deadline.
That gap between how AI infrastructure gets built and what periodic audit governance programs can see is where most compliance failures originate.
The snapshot below shows the operational disconnect between traditional cloud governance assumptions and the reality of modern AI infrastructure environments.
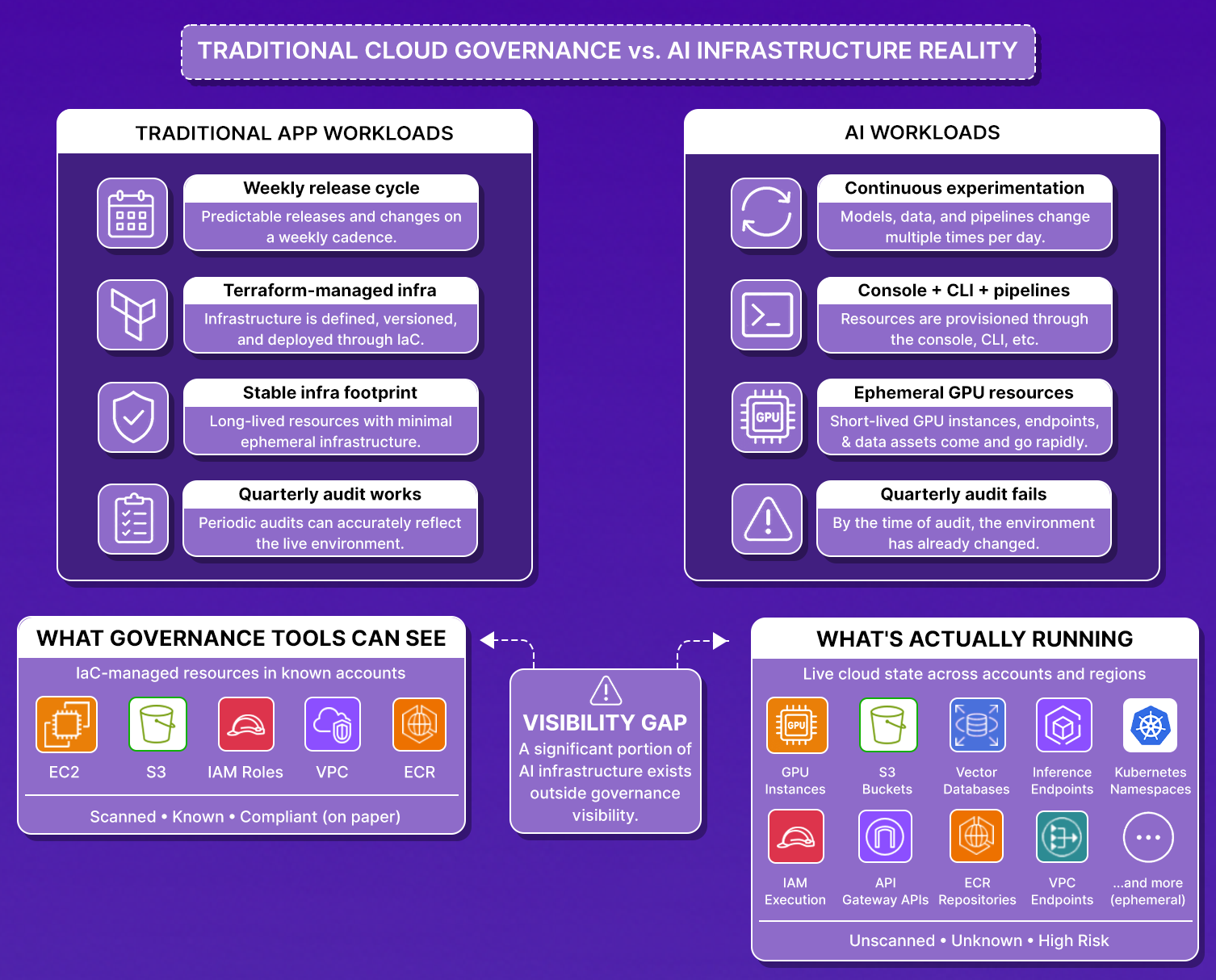
That gap between how AI infrastructure gets built and what periodic audit governance programs can see is where most compliance failures originate.
Three specific breaks explain why:
1. Infrastructure Changes Faster Than Governance Can Track
Teams provisioning new model versions, scaling inference capacity, and updating data pipelines make infrastructure changes faster than quarterly audits can track. Between audit cycles, the live environment and the IaC-defined environment diverge, and that gap is unmonitored. Fewer than one in three organizations continuously monitor their cloud infrastructure for configuration drift. The other two-thirds find out during an incident, a failed deployment, or an audit. Closing that gap is exactly what continuous, policy-as-code enforcement is built for - our guide to enterprise AI workflow automation covers how GitOps-driven reconciliation loops and Guardrail rules replace the audit cycle with real-time drift detection across the whole AI pipeline, not just the model layer.
2. AI Infrastructure Extends Beyond Traditional Governance Coverage
AI infrastructure is not one resource type. A single production AI workload spans GPU compute, inference endpoints, vector databases, S3 buckets, IAM execution roles, API Gateway APIs, ECR repositories, and Kubernetes namespaces, spread across multiple accounts and regions. Governance tooling that only scans IaC-managed resources misses every resource provisioned through the console, the CLI, or an ML pipeline that has never been touched by Terraform.
3. AI Regulations Now Include Operational Infrastructure Accountability
The EU AI Act's provisions on technical documentation and operational monitoring extend beyond model behavior to the systems and processes that support AI deployment. Organizations that treat infrastructure as outside the scope of AI governance will face compliance gaps as regulators begin assessing operational accountability, not just model outputs.
What Governing AI Workload Infrastructure Actually Requires
Governing the infrastructure layer of AI workloads is different from a standard web application stack. AI workloads span a wider set of resource types, each with specific accessibility requirements, and each with a distinct governance failure mode when that access level is wrong.
Three accessibility tiers apply across all of these resources:
- Strictly private: training compute, data storage, vector databases, feature stores, container registries. None of these carries a legitimate reason to have a public endpoint. A Firefly policy flagging any resource in this tier with public access enabled is a CRITICAL violation, not a configuration preference.
- Private with controlled external access: inference endpoints and API Gateway APIs. These serve external traffic but only through a defined control surface: TLS, authorizer, WAF, usage plan, CloudWatch logging. Each missing control is a separate policy violation on a production-exposed resource.
- Management plane private: Kubernetes API servers, IAM roles, Secrets Manager. The management interfaces for AI infrastructure must never be publicly reachable. An EKS cluster with a public API endpoint, or an IAM role with a trust policy that allows any principal, is a governance failure at the account boundary level.
The governance requirement across all three tiers is the same: continuous visibility into the current configuration of every resource, real-time detection when that configuration drifts from its defined state, and a remediation path that closes the violation without requiring an engineer to manually author the fix. Periodic audits produce this picture four times a year. AI workload infrastructure changes four times a day.
When the access and configuration requirements are not checked continuously, the gaps compound quietly. A training bucket gets provisioned without encryption in a non-production account, sits untagged and unowned for six months, and is only discovered when someone notices $4,000 in unexpected monthly storage costs, 180 days after the governance failure actually happened.
How Firefly Governs Cloud Infrastructure for AI Workloads
The Bedrock agent's over-permissioned execution role, the RDS security group change that ran exposed for three weeks, the unencrypted training bucket with no IaC definition — Firefly catches each one at the specific point where it occurs: before the Terraform plan applies, the moment a live resource drifts from its defined state, and when the engineer needs a fix without authoring Terraform from scratch.
Blocking Non-Compliant AI Infrastructure Before terraform apply
The Bedrock agent's IAM execution role ships with s3:* on every bucket because no policy rule evaluated the Terraform plan before the Terraform apply ran. The SageMaker endpoint goes out without a VPC constraint because the ML engineer who wrote the module didn't know the networking standard. The training bucket lands in the dev account without KMS encryption because no guardrail blocked it in that workspace.
Firefly's Guardrails evaluate every Terraform plan before terraform apply runs, when the Bedrock agent's execution role with Resource: * triggers a least-privilege rule, the deployment stops and the engineer gets a PR comment naming the specific violation, which rule fired, and an AI-generated fix suggestion showing the corrected Terraform block, inline, in the PR, before the merge.
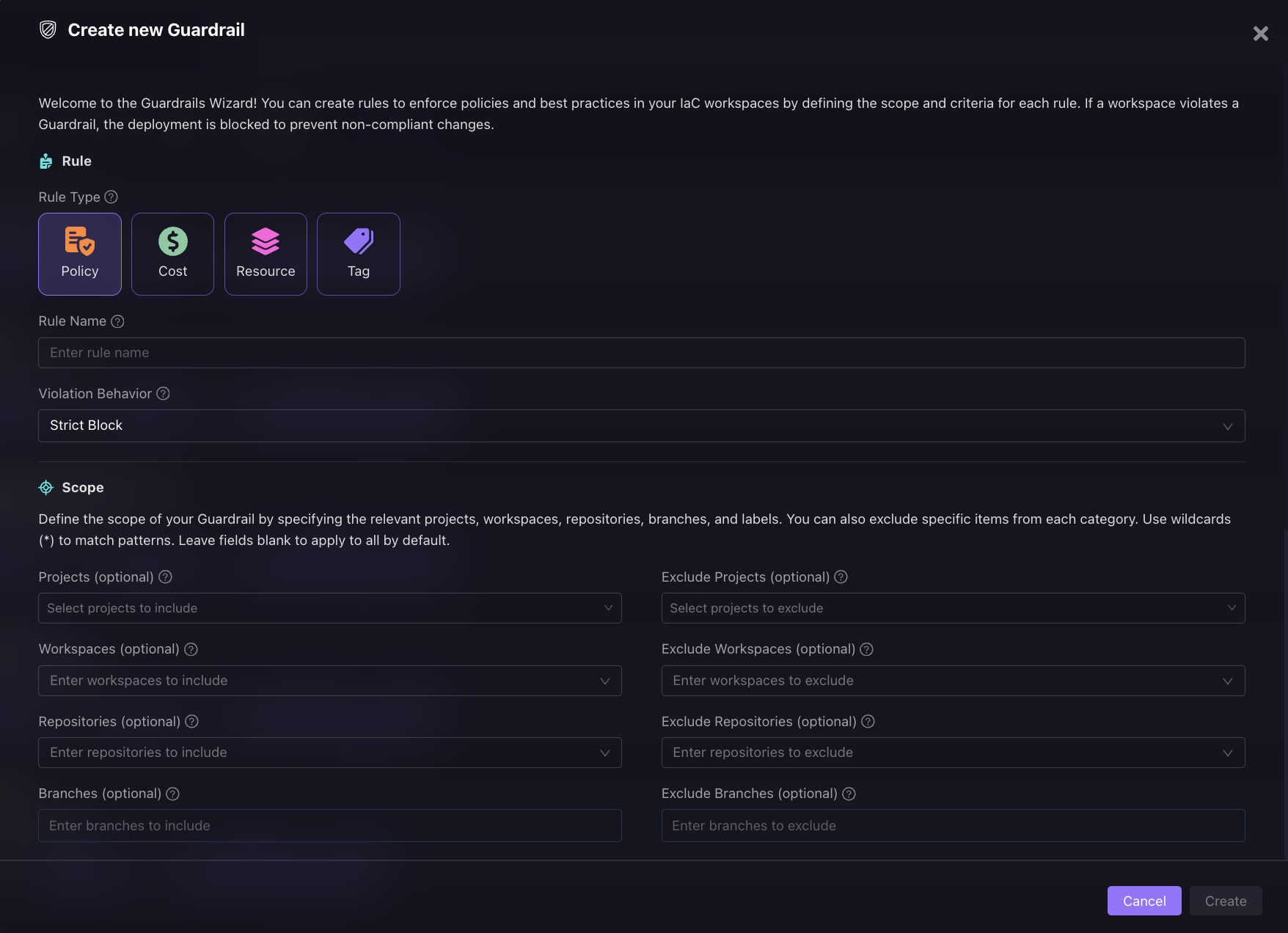
Four rule types cover the failure modes that appear most often for AI workloads:
- Policy rules: A Guardrail requiring KMS encryption on every S3 training bucket fires when an ML engineer pushes a plan without a server_side_encryption_configuration block; the bucket never lands in the dev account unencrypted. A rule requiring VPC deployment on SageMaker endpoints catches the publicly exposed inference endpoint before terraform apply runs. A rule blocking any IAM execution role with wildcard Resource: * catches the Bedrock agent's over-permissioned role before it ships, the Cross-Account IAM Assume Role Policy Without ExternalId or MFA violation never reaches the live account.
- Cost rules: A Terraform plan provisioning an ML.p4d.24xlarge GPU cluster that pushes the estimated deployment cost $38,000 above the workspace threshold gets blocked at plan time. The engineer sees the projected monthly cost against the defined limit before the instance is provisioned.
- Tag rules: A GPU node group missing Owner and Environment tags is blocked at plan time, before it lands in a non-production account, where it would sit unowned for six months, accumulating storage costs with no team responsible for it.
- Resource rules: Block creation, deletion, or modification of specific resource types in specific regions, enforcing the account boundaries that keep AI workload infrastructure out of accounts your compliance tooling doesn't scan.
Rules run as either a Strict Block, no override, no exceptions, used for wildcard IAM roles and public inference endpoints, or a Flexible Block, which blocks by default but lets authorized engineers override for a single run or permanently for that specific violation. Every override is logged.
The no-op check closes the non-production account sprawl gap that quarterly scans structurally miss. Policy and tag rules scan not just what the current plan is changing, but everything already running in the environment, scoped to that workspace. An ML engineer pushing a new SageMaker endpoint triggers a scan that surfaces 14 unencrypted S3 training buckets sitting in a non-production account for the past six months, resources that would never appear in a plan diff, but are still violating the encryption policy tied to that workspace.
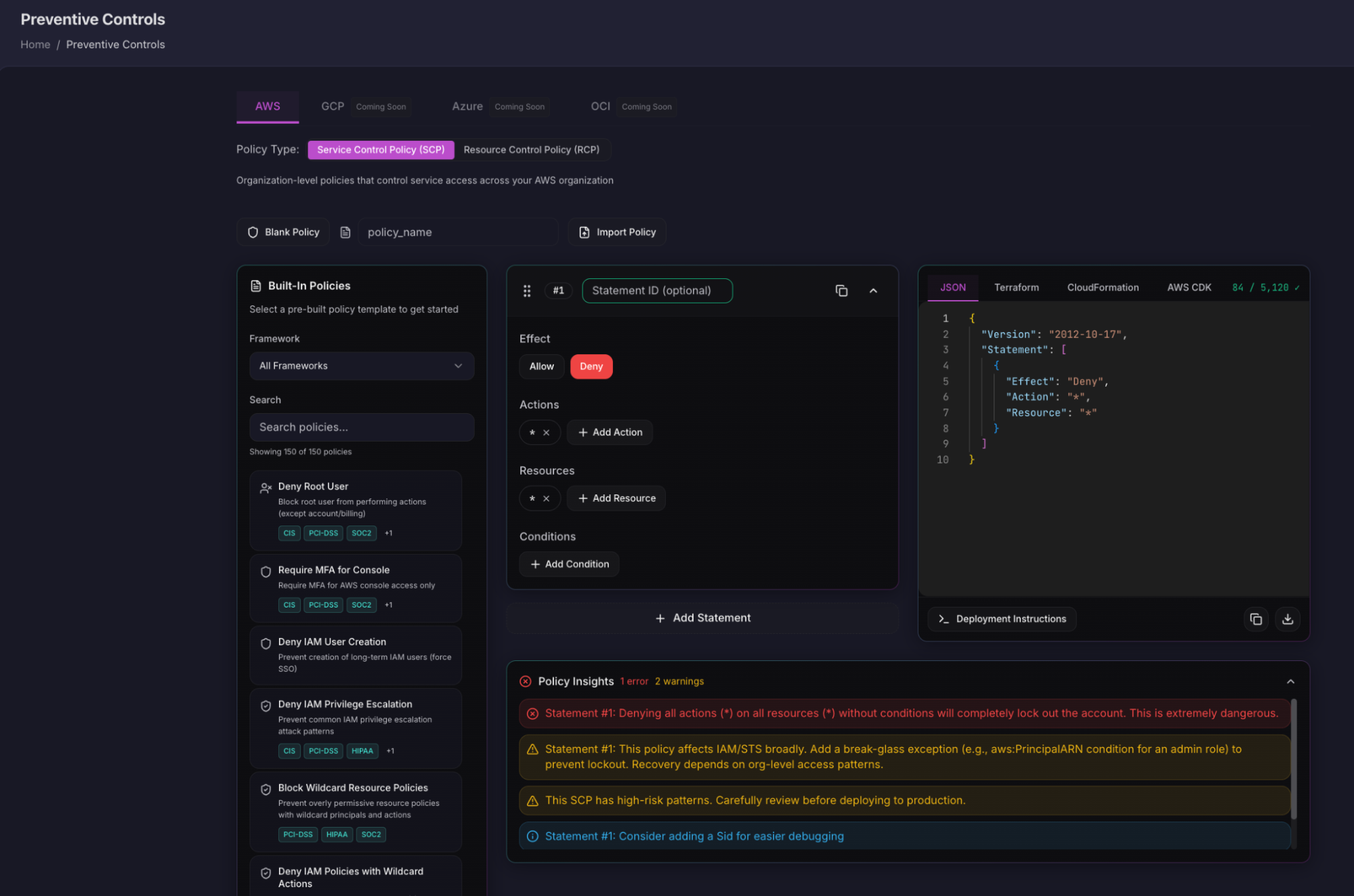
Preventive Controls push SCPs to AWS Organizations that deny non-compliant API calls before any resource in any account can be created or modified, whether the call came from Terraform, the console, or a notebook-triggered pipeline. A sagemaker:CreateTrainingJob call without sagemaker:VolumeKmsKey specified gets a hard deny at the AWS Organizations level before the GPU instance is provisioned. Deny IAM privilege escalation. Block wildcard resource policies. Require MFA for console access in training accounts.
The two active SCPs deny sagemaker:CreateNotebookInstance and sagemaker:CreateTrainingJob when sagemaker:VolumeKmsKey is null. Any training job triggered without a KMS volume key gets a hard deny at the AWS Organizations level, whether the engineer used Terraform, the console, or a Jupyter notebook. The Policy Insights panel flags a warning before this SCP deploys: neither statement has an aws:PrincipalIsAWSService condition, which means AWS-managed service roles could be blocked alongside human-initiated calls. Firefly surfaces that risk before the SCP goes live, so the governance control itself doesn't become the incident.
Console changes to AI workload resources bypass every Guardrail and leave no audit trail until Firefly detects the delta
Guardrails evaluate Terraform plans. An engineer who opens the AWS console at 11 pm during a production incident and removes the VPC-restriction rule from the RDS security group bypasses every Guardrail in the pipeline. The live configuration diverges from the Terraform definition the moment the rule is saved, and nothing detects the delta until Firefly's continuous IaC-to-live comparison fires.
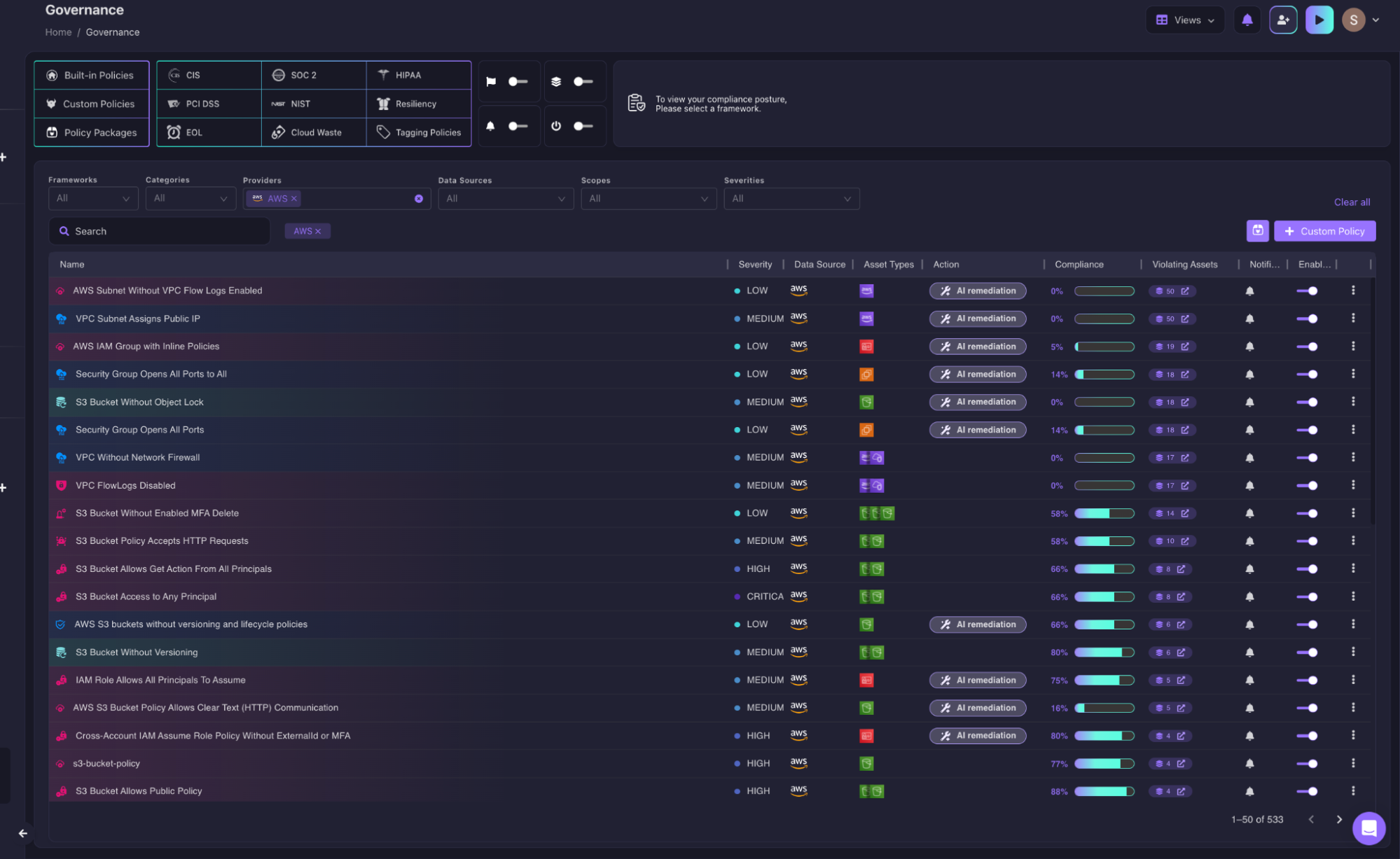
The Governance page maps every active policy to the live cloud state across every connected account, severity, asset type, compliance rate, and exact count of violating assets. A platform engineer can see at a glance that S3 Bucket Access to Any Principal is sitting at CRITICAL with 6 violating assets, or that Cross-Account IAM Assume Role Policy Without ExternalId or MFA is HIGH with 4 violations on Bedrock agent execution roles. Each violation has an AI Remediation button that generates the fix without leaving the page.
Firefly continuously compares every inventoried resource against its IaC definition and 533+ built-in policies covering CIS, SOC 2, HIPAA, PCI DSS, and NIST, flagging the moment a resource attribute diverges from its defined state, not at the next quarterly scan.
For AI workloads, that continuous comparison runs across every connected account, including the non-production accounts where ML engineers provision training jobs outside Terraform and where quarterly scans never run. The moment the engineer removes the VPC-restriction rule from the RDS security group in the console, Firefly detects the delta between the live configuration and the Terraform state and fires an alert through Slack, PagerDuty, or Teams, not three weeks later, not at the next quarterly scan, but within minutes of the change occurring.
For teams with AI-specific requirements beyond the 533 built-in policies, "flag any SageMaker endpoint not deployed in a VPC with KMS encryption enabled on the associated training bucket", Firefly generates the Rego policy from a plain-language description. The engineer validates it in the playground against a sample SageMaker resource, and it immediately begins evaluating every matching resource across all connected accounts, flagging existing violations and blocking future deployments that violate the new rule.
Closing AI Workload Policy Violations Without Manual Terraform
When the SOC 2 auditor flags the unencrypted S3 training bucket in the dev account, the platform engineer assigned to fix it faces two problems: the bucket was provisioned from the AWS console six months ago, no IaC definition, no Terraform module to update, no PR to open. The fix requires knowing the exact AWS CLI syntax, identifying the correct KMS key ARN, and running the command without review or an audit trail for the remediation itself.
Firefly's remediation closes both paths, for Terraform-managed resources and for ghost resources provisioned outside any pipeline.
For the SageMaker endpoint provisioned through Terraform but deployed outside a VPC, Firefly generates the IaC change, adding the vpc_config block with the correct subnet IDs and security group references, and opens a PR against the team's existing repository. The engineer reviews the generated change, approves it, and the pipeline applies it. The fix goes through the same PR workflow used for every other infrastructure change, with a reviewer, a pipeline run, and a commit that attributes the remediation to a specific identity at a specific timestamp.
For the S3 training bucket provisioned from the AWS console with no IaC definition, Firefly generates the AWS CLI command to apply the encryption configuration directly:
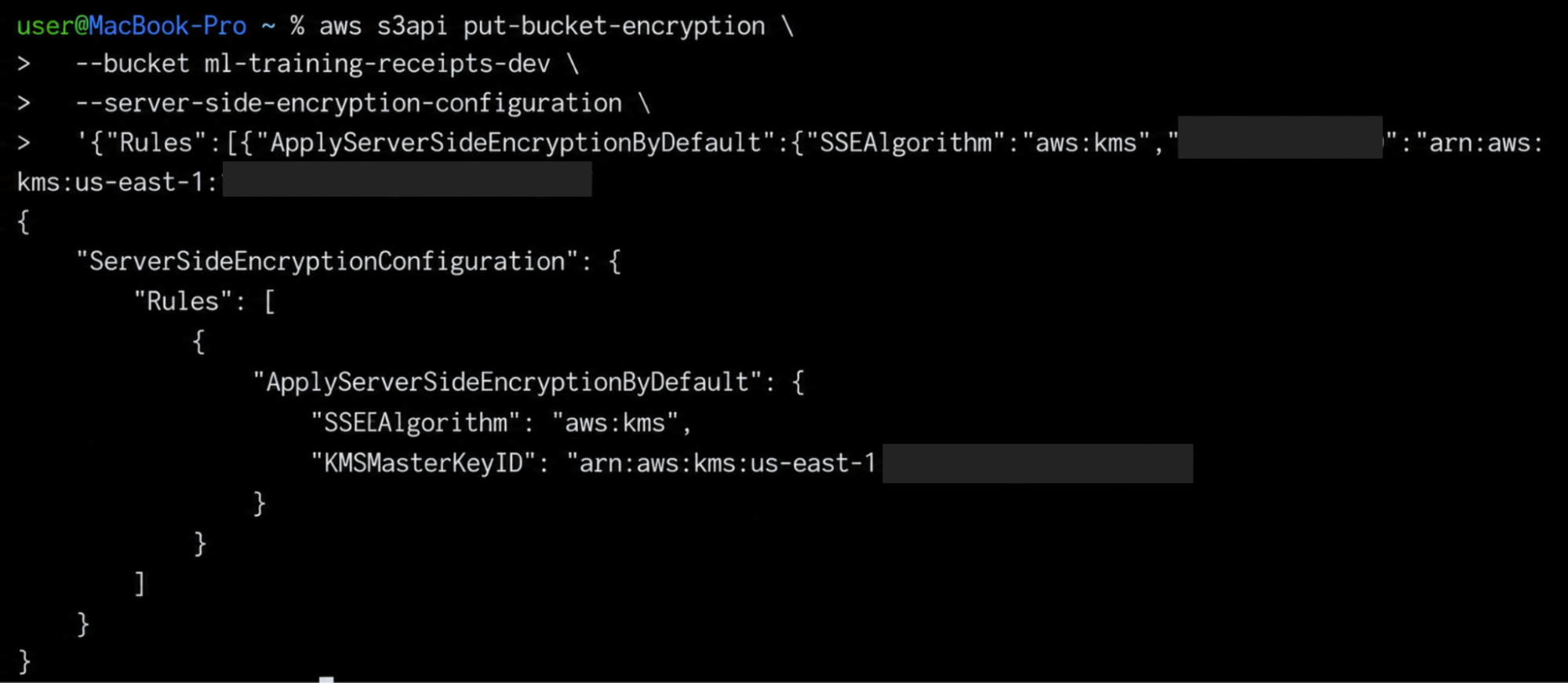
The engineer runs it. Firefly re-evaluates the bucket against the S3 Bucket Access to Any Principal and encryption policies. The violation closes. The Governance page updates. The SOC 2 auditor gets a timestamped remediation record tied to that specific bucket, not a manual note in a spreadsheet.
Both paths come from the AI Remediation button on the Governance page. Select the violation, pick IaC Patch for Terraform-managed resources or Cloud Patch for ghost resources provisioned outside any pipeline, review the generated fix, and apply it.
FAQs
What is the difference between AI governance and cloud governance?
AI governance is the broader discipline: it covers how AI systems are developed, deployed, and monitored responsibly, including model behavior, data quality, and operational accountability. Cloud governance is one component of AI governance, specifically the operational governance layer that controls how cloud infrastructure is configured, changed, and enforced against policy. An AI governance program that does not include cloud infrastructure governance has an uncovered layer.
What does an AI governance framework include for engineering teams?
For engineering teams, an AI governance framework defines policy standards for infrastructure configuration, enforcement mechanisms that run in CI/CD pipelines rather than quarterly audits, change accountability processes that attribute every infrastructure modification to an authorized workflow, and remediation requirements that specify how quickly detected violations must be resolved. Frameworks like NIST AI RMF and the EU AI Act set organizational-level requirements; engineering teams operationalize them through IaC policies, drift detection, and audit trails.
How do I detect and fix infrastructure drift as part of cloud governance?
Drift detection requires comparing the live state of every cloud resource against its IaC definition continuously. A resource whose live configuration diverges from its Terraform or Pulumi definition is drifted and represents an untracked change. Tools like Firefly perform this comparison in real time and surface the specific attribute that changed, the timestamp, and the compliance impact. Remediation is applied by generating the IaC change that brings the resource back into compliance and committing it through the existing PR workflow.
What are the best AI governance tools for multi-cloud environments?
The answer depends on which governance layer you are addressing. For model governance, IBM OpenScale, Databricks Unity Catalog, and AWS AI Service Cards address model lifecycle and compliance. For operational governance across multi-cloud environments, tools need to inventory and enforce policy across AWS, Azure, GCP, and Kubernetes simultaneously. Firefly covers this layer with a unified inventory, continuous drift detection, and policy enforcement across all major cloud providers and Kubernetes clusters.

.avif)
.avif)
.webp)

.webp)

















