
TL;DR
- Traditional DRaaS replicates VMs and automates failover; it was built for hardware failures, not for broken IAM policies, Kubernetes misconfigurations, or Terraform drift.
- A Velero restore can exit cleanly while PostgreSQL pods stay in Pending, the application IAM role returns 403 on every secrets fetch, and terraform plan exits with code 2. The infrastructure is back. The application is not.
- Manual post-restore recovery for a single-namespace EKS stack, reconstructing IAM from CloudTrail, parsing kubectl describe pod events, interpreting Terraform diffs, and sequencing fixes without a dependency graph takes two to six hours. For twenty services across three availability zones, there is no reliable time bound.
- Firefly's CAIRS rebuilds full environments from IaC on demand, restoring compute, networking, IAM, and Kubernetes state in dependency order with health validation gates between each step.
- CRPM continuously scans for resources that exist in production but are absent from IaC, flags drifted configurations before they become recovery failures, and generates per-resource remediation commands scoped to exact resource IDs, before the incident, not during it.
In the Reddit community: r/sysadmin, an engineer running on-premises infrastructure alongside critical workloads in Azure, asked for recommendations to replace their backup and disaster recovery stack.
Every solution they tested failed in an important way: one could not restore cleanly into Azure, another restored on-premises systems too slowly, and another lacked Linux backup support entirely. The replies followed the same pattern, suggesting Veeam, Commvault, HYCU, Azure-native tooling, and custom recovery scripts stitched together internally because no single platform covered the full environment without operational gaps. Coverage gaps like that are common enough that we keep an updated comparison of cloud disaster recovery solutions, evaluating where platforms like Firefly, Druva, Rubrik, Trilio, and Veeam each draw the line between backup and full application recovery.
That is what happens when disaster recovery tooling designed around restoring servers and virtual machines meets environments built on Kubernetes, IAM policies, managed services, secrets managers, APIs, and distributed application dependencies.
Restoring compute, storage, and networking no longer guarantees that the application running on top of them will recover correctly. Kubernetes workloads depend on runtime configuration, service discovery, IAM state, secrets, and dependency sequencing that exist outside VM snapshots and infrastructure replication workflows.
Now, to be clearer about why those recovery gaps appear and why they become harder to manage as cloud-native complexity grows, we start with understanding what Disaster Recovery as a Service was originally designed to protect.
What Is Disaster Recovery as a Service, and How Does It Work?
Let's suppose: it is 2 AM, a ransomware attack has encrypted your primary database server, and your on-call engineer is staring at a dead environment. Without DR in place, that engineer spends the next 12 hours rebuilding from whatever backup exists, if one does.
With DRaaS, the provider has already been replicating your servers to a secondary environment in real time. The engineer triggers a failover, and within minutes, the replicated environment is serving traffic. That is the core promise of DRaaS: a third-party provider continuously mirrors your infrastructure so that when the primary environment fails, operations switch to the replica without rebuilding from scratch.
Two numbers define whether that promise holds under real conditions:
RTO (Recovery Time Objective) is how long the business can survive with systems offline. An e-commerce platform processing $50,000 per hour has a very different RTO tolerance than an internal reporting tool. DRaaS providers compete on RTO; competitive providers push into the sub-hour range, and some cloud-based solutions spin up a VM in minutes.
RPO (Recovery Point Objective) is how much data loss is acceptable. A payment processor with an RPO of zero replicates every transaction in real time; losing even one payment record is unacceptable. A company with an RPO of four hours accepts that a worst-case failure wipes the last four hours of changes.
Teams choose a delivery model based on how much of that responsibility they want to own:
- Self-service: the provider supplies the infrastructure, and the internal team runs the DR plan. Lower cost, but the team is on their own at 2 AM when an incident fires.
- Assisted: an MSP helps build and test the DR plan and provides expert support during an active incident. Balances cost with coverage.
- Managed: the MSP owns DR end-to-end, from planning through execution. Right fit for teams without dedicated infrastructure staff; the highest cost of the three.
One comparison that trips up most procurement decisions: DRaaS is not the same as Backup as a Service (BaaS). BaaS copies data off-site. If a failure occurs, an engineer retrieves the backup and manually rebuilds the environment around it, with RTO measured in hours or days. DRaaS replicates both data and infrastructure and automates the failover, with RTO measured in minutes. An organization running BaaS and calling it DR has protected its data, but has no automated path back to a running application.
That distinction, data backup versus infrastructure recovery, is exactly where most cloud-native environments expose a deeper problem.
Why Does DRaaS Break in Cloud-Native Environments?
Here is a failure that happened to a real team. Their EKS cluster went down during a node replacement.
The DRaaS failover ran, the compute came back online, and the RTO SLA was met. Then the on-call engineer spent the next four hours debugging why none of the application pods were scheduling. On doing RCA, it was found that the node selector labels in the deployment spec no longer matched the labels on the replacement nodes, a Kubernetes misconfiguration that had nothing to do with the server going down and everything to do with the configuration state that the DRaaS tool never touched.
That is not an edge case. These are the failure modes that actually take cloud-native production down:
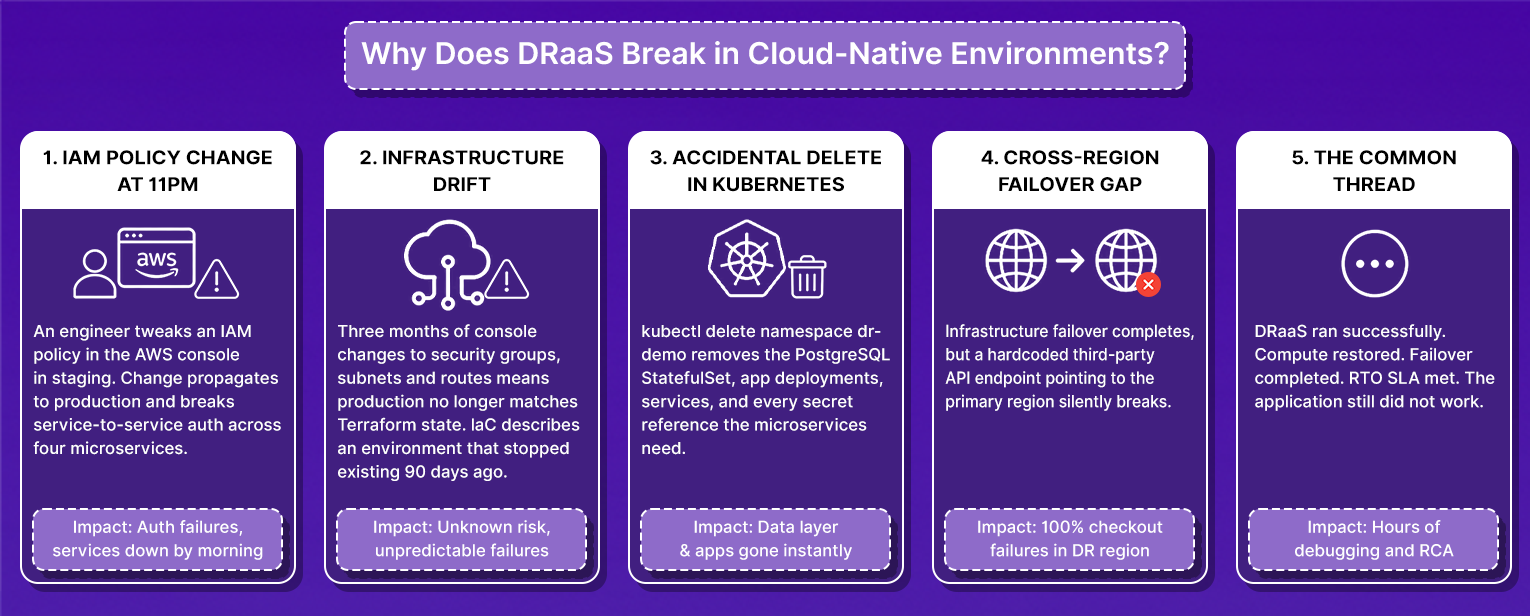
- An engineer tweaks an IAM policy in the AWS console at 11 PM to fix a permissions issue in staging. The change propagates to production and breaks service-to-service authentication across four microservices. Nobody knows until the morning.
- Three months of engineers adding security group rules and modifying subnets directly in the console means production no longer matches Terraform state. The IaC definitions describe an environment that stopped existing 90 days ago.
- An accidental kubectl delete namespace dr-demo during a cleanup operation removes the PostgreSQL StatefulSet, application deployments, services, and every secret reference the three microservices fetch at startup, simultaneously.
- A cross-region failover completes at the infrastructure layer, while a hardcoded third-party API endpoint pointing to the primary region's URL silently breaks, causing 100% checkout failures in the recovery region.
The DRaaS tool ran successfully in every one of these scenarios. Compute restored. Failover completed. RTO SLA met. And the application still did not work, because the failure was never in the hardware.
Traditional DRaaS protects the things that failed in 2010: servers, storage, VM images, and network replication. What it does not touch in a cloud-native environment:
- IAM roles and cross-account trust policies that took six months of incremental tuning to reach a working state and exist nowhere as version-controlled code
- Kubernetes manifests, Helm values, network policies, and RBAC rules that have drifted from their declared state through two quarters of direct kubectl edits
- Database credentials and API keys in Secrets Manager or Vault, with rotation schedules and IAM access policies that nobody codified in Terraform
- The service dependency graph: which microservice calls which endpoint, in what order, before which database is ready, living in a Confluence page that was last updated eight months ago
The result was a DRaaS plan executed, the RTO clock stopped, the SLA was met, and the engineering team spent the next six hours figuring out why IAM is broken, why three pods are in CrashLoopBackOff, and why checkout is returning 500s. Only 11% of teams describe their DR posture as tested and validated. 30% have little to no confidence in their stated RTO targets. The infrastructure came back. The application did not.
Gartner’s peer data reflects the operational gap this creates: only 11% of teams describe their disaster recovery posture as fully tested and validated, while 30% report little to no confidence in meeting their stated RTO targets. The confidence problem is no longer infrastructure failover itself; it is everything the failover leaves unresolved.
DRaaS Recovery Workflows Break After the Restore Completes, Not During It
DRaaS platforms can successfully restore infrastructure, recover Kubernetes namespaces, and recreate persistent volumes while PostgreSQL pods fail readiness checks, LoadBalancer endpoints return 503 responses, and IAM permissions block service-to-service calls. The failure between a successful infrastructure restore and a functioning application surfaces during post-restore validation, not during the Velero restore operation itself.
To demonstrate where the break occurs, consider an EKS-based application stack:
- A Terraform-managed Kubernetes cluster
- PostgreSQL running as a StatefulSet with EBS-backed storage
- Velero backups stored in S3
- An NGINX application exposed through a LoadBalancer
- Automated backup, restore, and validation workflows
The environment is deployed through Terraform and bootstrapped with a setup workflow that installs Velero, configures backup storage, deploys Kubernetes workloads, and waits for the cluster to become healthy:
terraform apply -auto-approve
aws eks update-kubeconfig --region "${AWS_REGION}" --name "${CLUSTER_NAME}"
helm upgrade --install velero vmware-tanzu/velero \
--namespace velero \
--create-namespace \
-f helm/velero-values.generated.yaml
kubectl apply -f kubernetes/03-postgres-statefulset.yaml
kubectl apply -f kubernetes/04-nginx.yamlThree weeks into production, an engineer deletes the dr-demo namespace during a routine cleanup operation:
kubectl delete namespace dr-demoThe PostgreSQL StatefulSet, application deployments, services, and Kubernetes configuration disappear immediately. Velero restores the latest backup:
./scripts/restore-latest.shVelero recreates the namespace, deployments, StatefulSets, persistent volume claims, services, and PostgreSQL storage attachments. At the Kubernetes resource layer, the restore exits cleanly. None of these steps confirms that the application is accepting traffic or that PostgreSQL is returning valid query results.
Post-restore validation runs the following checks:
velero backup get
kubectl get pvc -n dr-demo
kubectl get pods -n dr-demo
terraform -chdir=terraform plan -detailed-exitcodeThe Terraform plan -detailed-exitcode step matters because Velero restores Kubernetes resource definitions, not infrastructure state. A restored PVC can reference an EBS volume that no longer exists in the same availability zone, causing the StatefulSet to schedule, but the pod to fail volume attachment.
Infrastructure can come back online with all of the following conditions active simultaneously:
- Persistent volumes attach to the wrong availability zone, leaving the StatefulSet pod in Pending indefinitely
- services pass TCP health checks but return 503 on application-layer readiness probes
- Terraform plan exists with code 2, indicating infrastructure state diverged from the restored Kubernetes resource definitions.
- The NGINX deployment initializes before PostgreSQL finishes WAL recovery, causing connection pool exhaustion at startup.
- The application's IAM role lost its secretsmanager:GetSecretValue permission during namespace deletion, returning 403 on every secrets fetch at pod startup.
Recreating compute infrastructure is a solved problem. The unsolved problem is confirming that PostgreSQL is returning valid query results, that IAM permissions match the pre-incident state, that the terraform plan exists clean, and that application pods are passing readiness probes, before declaring recovery complete and routing production traffic back.
What Manual Recovery Looks Like Without a Platform Tracking Environment State
For the EKS stack in the scenario above, like one namespace, one database, one application, one load balancer, an engineer working through post-restore validation without IaC coverage executes the following in sequence:
- Reconstruct IAM state from the AWS console. Identify which roles were assigned to each service account before the namespace deletion. No Terraform record exists for these attachments; the engineer works from memory, CloudTrail logs, and whatever documentation existed before the incident.
- Cross-reference Secrets Manager manually. Confirm which credential ARNs the application referenced at startup, verify that the IAM policy granting secretsmanager:GetSecretValue still exists on the restored service account, and check that rotation schedules did not invalidate a credential version during the outage window.
- Parse kubectl describe pod events on every failing pod. Determine per pod whether the failure is a volume attachment error, a readiness probe timeout, a missing secret reference, or an IAM 403. Each failure mode requires a different corrective action and a different AWS console path to fix it.
- Interpret every diff in terraform plan output. Identify which infrastructure properties diverged during the Velero restore, determine which diffs represent actual misconfiguration versus expected state differences, and decide which to apply and in what order without breaking dependencies.
- Sequence corrective actions without a dependency graph. Apply IAM fixes before restarting pods that depend on those roles. Restore secret references before restarting services that fetch credentials at startup. Re-enable ingress only after all downstream services pass readiness probes.
Each step requires pre-incident context that may not exist in any written record. For this single-namespace stack, the sequence takes two to six hours, depending on IaC coverage. For a production environment running twenty services across three availability zones, the same process has no reliable time bound, because the dependency graph the engineer is reconstructing from memory grows nonlinearly with the number of services. That nonlinear growth is exactly where small-scale recovery stops working as a mental model, see our breakdown of enterprise disaster recovery for how the failure patterns change once you're coordinating dozens of services across multiple clouds instead of one namespace.
How Does Firefly Solve the Recovery Gap That Traditional DRaaS Leaves Open?
Firefly is recognized by Gartner as a leading Cloud Application Infrastructure Recovery Solution (CAIRS), a category that addresses application-layer recovery, not just infrastructure restore. The distinction between CAIRS and traditional DRaaS maps directly onto the gap described above: traditional DRaaS restores the hardware layer; CAIRS restores the operational state the application depends on to run. Firefly addresses the cloud-native recovery gap through two capabilities: For a broader look at where CAIRS sits relative to VM replication tools, Kubernetes-native backup, and orchestration-layer platforms in general, see our guide to cloud disaster recovery platforms.
1. CAIRS (Cloud Application Infrastructure Recovery Solution): Rebuilding Full Environments from IaC, Not Snapshots
The core problem Firefly's CAIRS addresses: most organizations back up their data, but do not back up the infrastructure configuration, IAM state, Kubernetes manifest state, and service dependency relationships needed to run that data. Data backup without infrastructure backup results in data being safe, but the application that processes it cannot be rebuilt.
Firefly's CAIRS rebuilds complete cloud environments on demand using Infrastructure-as-Code. When a restore is triggered, Firefly generates Terraform code that reconstructs the full environment, compute, networking, IAM configuration, secrets references, and Kubernetes state, rather than mutating cloud resources directly through API calls. Resources recovered through Firefly are fully codified, versioned, and auditable from the moment they are restored, not retrofitted into IaC after the fact.
Application policies are defined by tagging cloud resources with key-value pairs that represent logical groupings of applications. When a policy targets an EC2 instance, Firefly automatically captures the VPC, subnet, IAM instance profile, and all other relationships required to restore the application correctly. Backup schedules run on-demand, daily, weekly, or monthly, depending on the RPO requirements defined in the policy. The result is a single-pane view of backup coverage across every environment, each application showing its data source, region, snapshot count, last backup timestamp, and completion status without opening individual records.
The Applications dashboard below shows this in a live environment: web-app-stack on AWS us-east-1 has two completed on-demand snapshots covering 26 resources each; web on Google Cloud us-central1 has a single completed snapshot covering 6 resources.
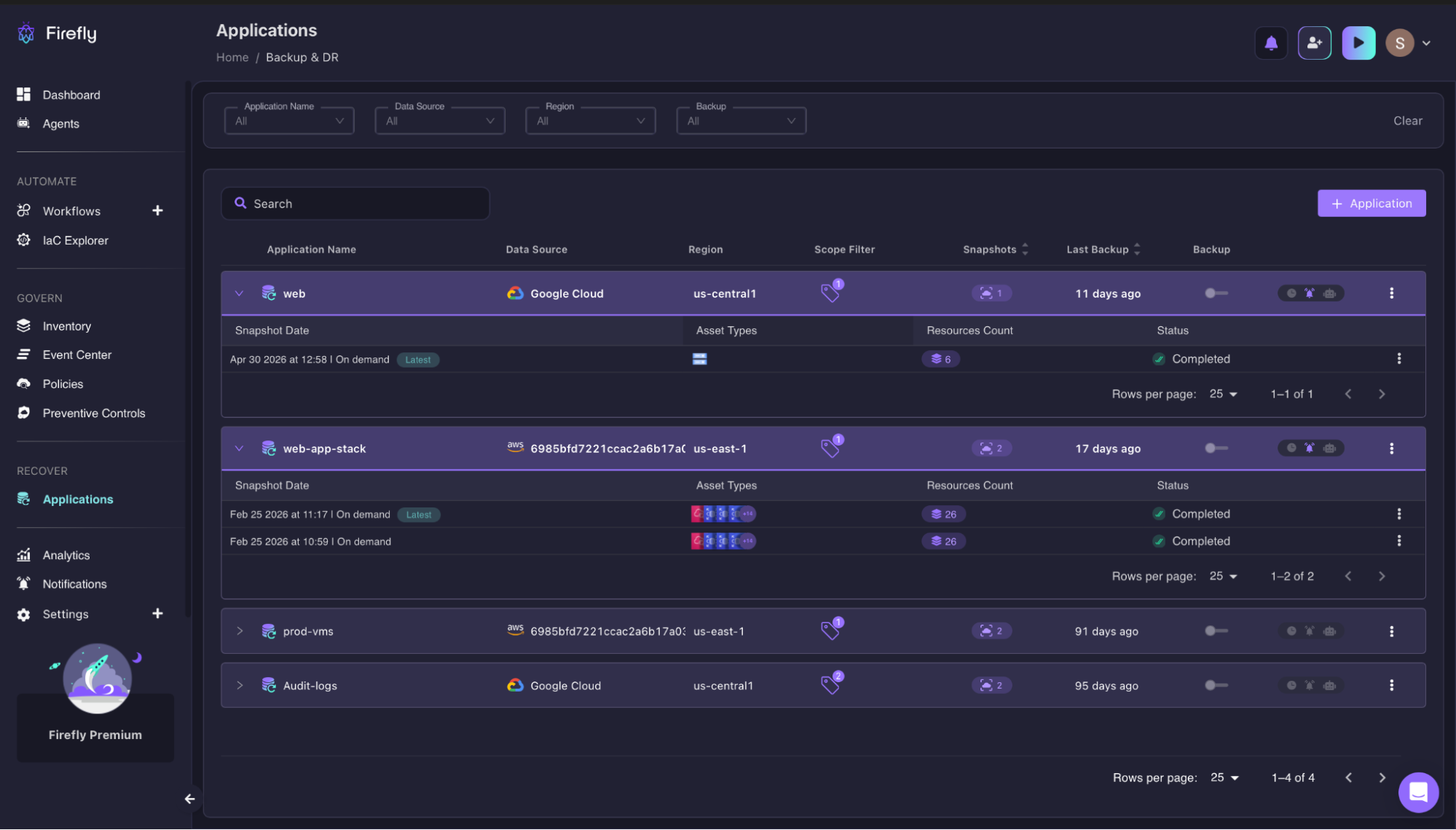
Both show completion status and recency at a glance, the same information an engineer would have spent 20 minutes reconstructing from CloudWatch and the AWS console during a manual recovery.
The recovery workflow: open a snapshot, select one or more resources, preview the generated Terraform code, and continue through Firefly's IaC orchestration flow. Every restored resource is codified and aligned with existing IaC standards from the moment it is restored. CAIRS targets RTO under one hour for full environment recovery, supports cross-region and cross-account recovery, and produces audit-ready evidence for SOC 2, ISO 27001, GDPR, and DORA at every step.
2. CRPM (Cloud Resilience Posture Management): Closing IaC Coverage Gaps Before They Become Recovery Failures
CAIRS handles recovery. CRPM addresses the conditions that can cause recovery to fail before an incident starts.
The most common reason a cloud-native recovery plan fails during execution is not a flaw in the recovery procedure. It is that IAM roles, security groups, and network configurations exist in production but are not represented in any IaC definition, and nobody knew until the recovery ran, and those resources were missing from the restored environment.
Firefly's CRPM continuously scans cloud environments across AWS, Azure, GCP, OCI, Kubernetes, and connected SaaS applications. It detects resources that exist in production but are absent from Terraform state, flags configurations that have drifted from their declared state, and generates IaC definitions for resources that were created manually and never codified.
The Governance view below, filtered to Resiliency Posture, shows what this looks like against a real AWS environment:
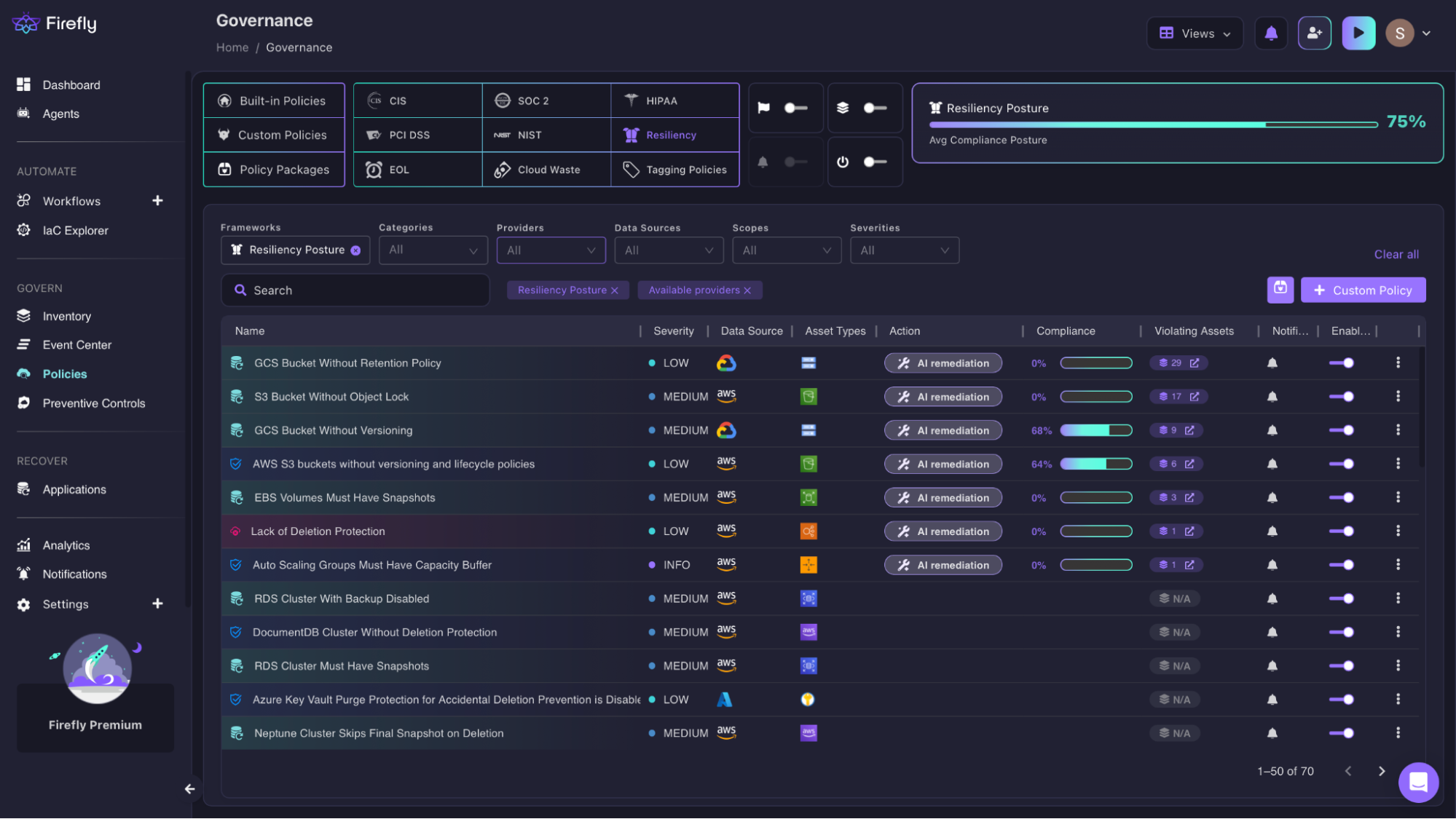
70 active policy violations, an average compliance posture of 75%, and specific violations including S3 Bucket Without Object Lock (MEDIUM, 17 assets), EBS Volumes Must Have Snapshots (MEDIUM, 3 assets), RDS Cluster With Backup Disabled (MEDIUM), and Neptune Cluster Skips Final Snapshot on Deletion (MEDIUM). Every one of these violations is a resource that would be missing or misconfigured in a recovery, surfaced before the incident, not during it.
When CRPM flags a misconfiguration, clicking into the policy shows the exact detection rule alongside the affected asset count and framework mapping. The policy rule for "AWS Subnet Without VPC Flow Logs Enabled" is three lines of readable logic, not input.flow_logs_enabled, version-controllable, and auditable the same way Terraform definitions are.
The policy detail view below shows this for a subnet misconfiguration flagged against 49 AWS assets, classified as a Misconfiguration under the CIS framework.
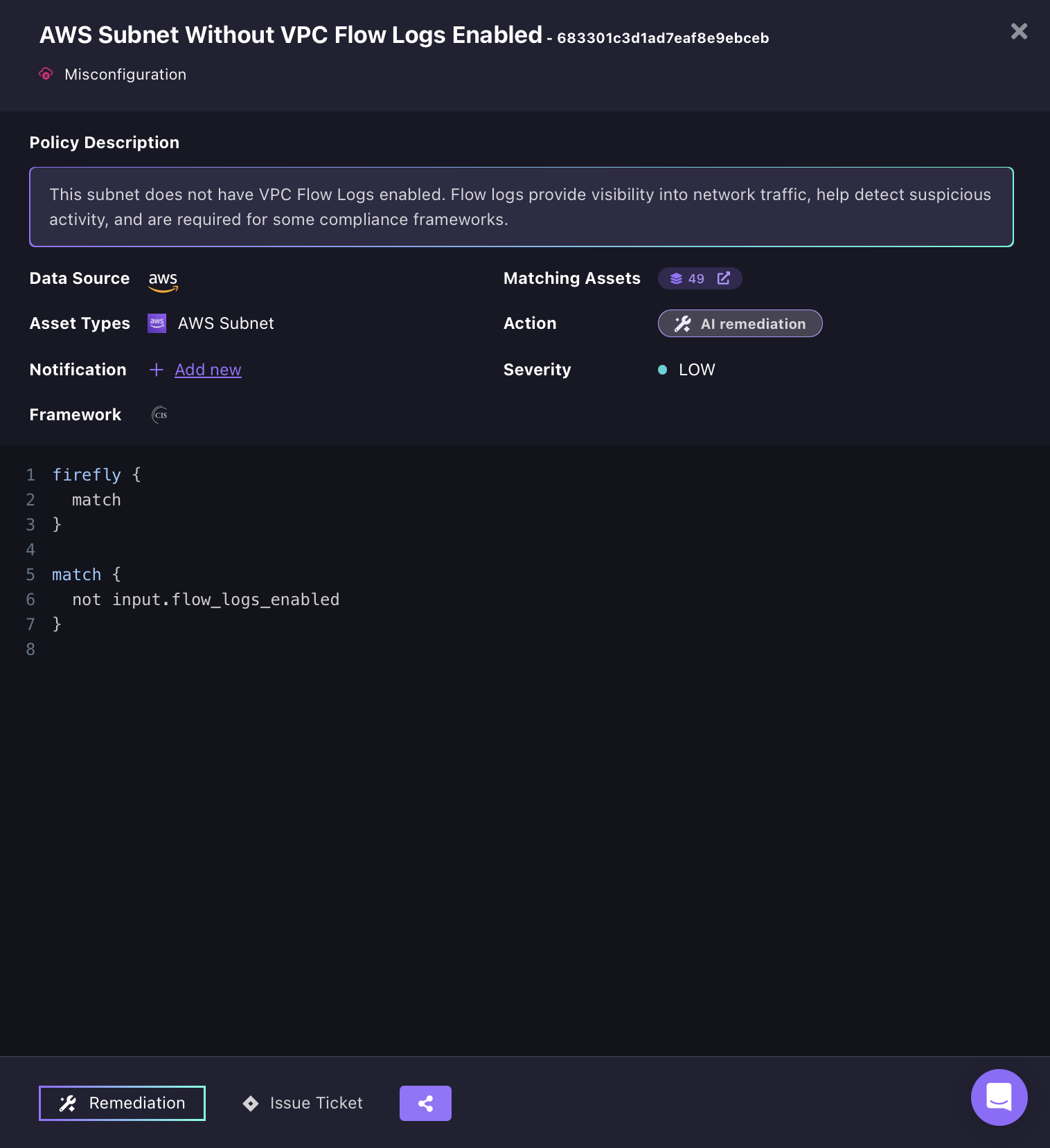
The detection rule is visible directly in the UI, no black box, no opaque scoring. From the policy view, triggering AI remediation opens the Remediation Wizard, which routes each affected resource to the correct fix path based on whether an IaC definition exists for that resource, an IaC Patch for Terraform-managed resources, or a Cloud Patch for manually-created ones.
For the subnet violation above, the IaC Patch shows 0 assets because the subnets were created directly in the console and have no Terraform state.
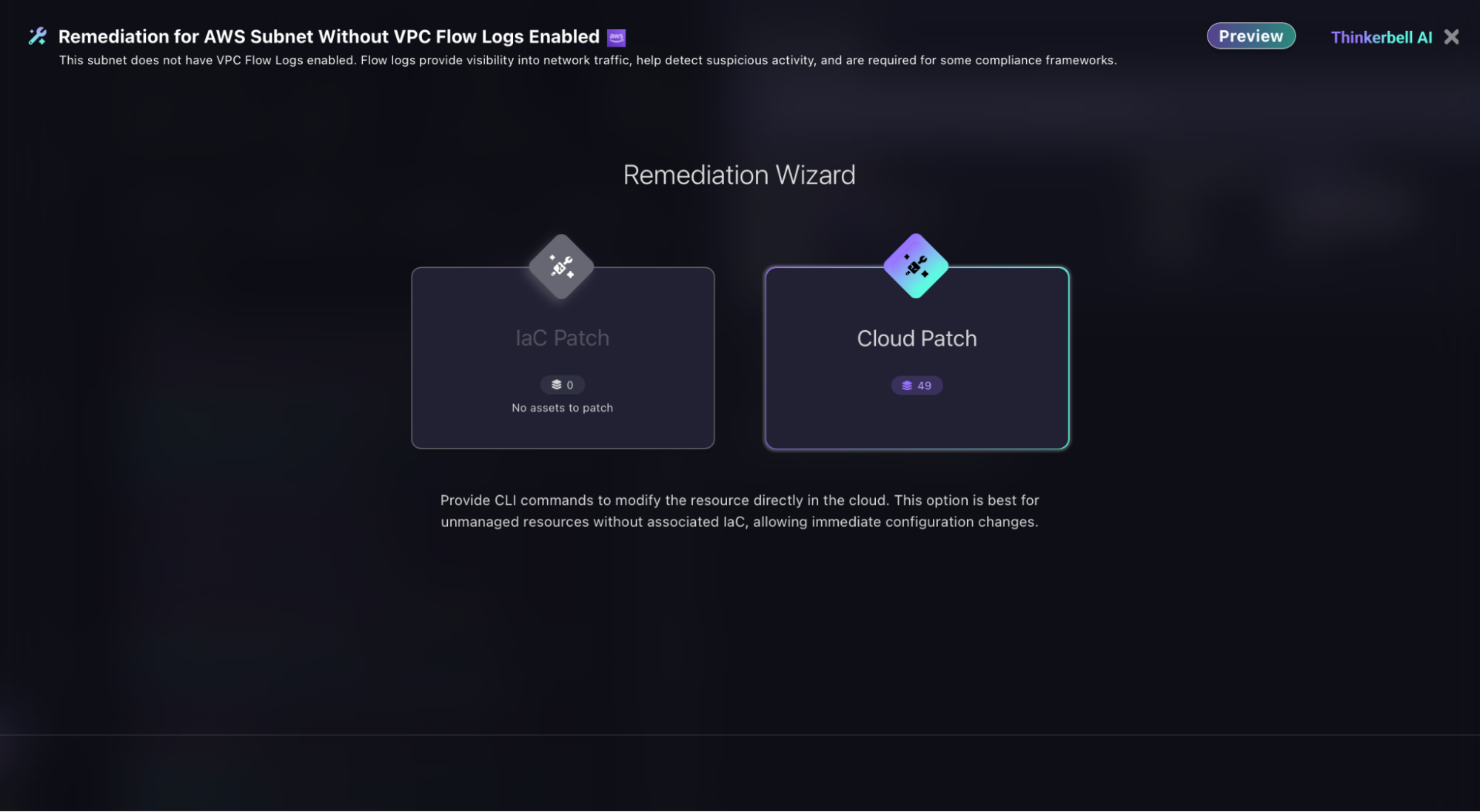
Cloud Patch shows 49 assets. Firefly does not apply a blanket fix; it identifies which resources are IaC-managed and which are not and routes each to the appropriate remediation path.
Selecting Cloud Patch generates exact, per-resource AWS CLI commands, not generic templates. For each affected subnet, Firefly produces five steps in sequence: create the CloudWatch Log Group scoped to the specific VPC ID, create the IAM role for VPC Flow Logs with the correct assume-role policy document, attach the policy to the role, enable flow logs on the exact subnet ID, and validate with aws ec2 describe-flow-logs.
The output below shows this for subnet-06ea483c2111a145b in ap-northeast-2, real subnet IDs, real ARNs, and real region.
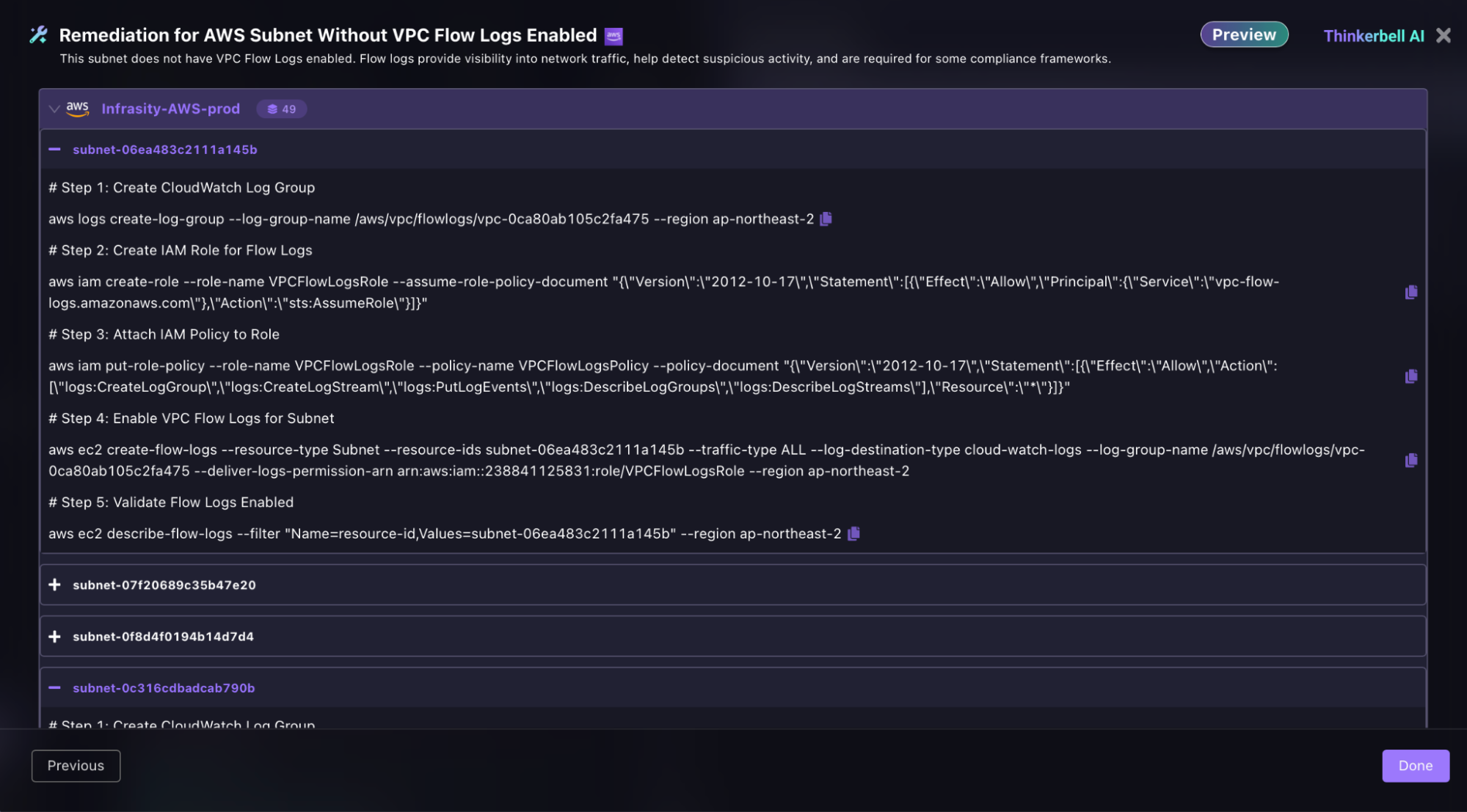
An engineer applies this directly without adaptation. The same output is generated for all 49 affected subnets in the account.
The operational shift CRPM produces: the question at 2 AM during an incident changes from "which resources did we forget to codify, and how do we reconstruct their configuration from memory and console screenshots?" to "does our orchestration sequence handle the database-before-application dependency correctly?" The first question has no good answer under incident pressure. The second is an engineering problem that can be solved in advance.
Does Having Complete IaC Coverage Mean Recovery Will Sequence Correctly?
Complete IaC coverage of a cloud-native environment is necessary for reliable recovery, but it is not sufficient. A Terraform definition that accurately describes every resource in the environment still does not encode the order in which those resources must be restored.
Cloud-native application recovery fails at the sequencing layer in predictable patterns:
- A Kubernetes cluster comes online before its backend PostgreSQL database finishes initializing. Application pods attempt database connections, fail, exhaust their restart budgets, and enter CrashLoopBackOff. The cluster is healthy, but the application is not running.
- Application service deployments are complete before the IAM roles that those services depend on are attached. Every API call the services make returns a 403. Engineers spend 40 minutes checking application logs before checking IAM.
- Traffic ingress is enabled before service health checks have passed. Load balancer health checks mark pods as healthy based on TCP connectivity, not application readiness. Users hit the application before it has completed startup initialization.
A recovery runbook that lists "step 1: restore database, step 2: restore application, step 3: enable ingress" is not orchestration. It is a checklist that a human reads under pressure at 3 AM, while simultaneously monitoring dashboards, answering incident channel messages, and updating a status page. Under that pressure, humans skip steps, execute steps out of order, and misread the state of partially initialized resources.
Reliable recovery at cloud-native scale requires automated dependency sequencing with health validation gates between each restoration step. The next component in the sequence does not start until the previous component passes its defined health check, not a TCP connectivity check, but an application-level readiness probe that confirms the component is accepting traffic and returning valid responses.
Firefly's restoration workflow handles dependency sequencing through its IaC orchestration layer. When a snapshot is restored, Firefly generates and executes Terraform in dependency order, infrastructure and networking first, then IAM, then stateful services like databases and queues, then stateless application services, then ingress and traffic routing. Each layer waits for health validation before the next begins. The full application stack is reconstructed in the correct sequence, with validation gates, without requiring an engineer to manually track and trigger each step.
The distributed system dependency graph of a production cloud-native application is too complex to sequence correctly by hand, under time pressure, while triaging the incident simultaneously. Encoding that sequence into automated orchestration, with explicit health gates and retry logic, is the engineering work that converts a theoretical RTO into a tested, repeatable one.
How Do You Verify That Your DR Plan Will Hold Under Real Incident Conditions?
The only way to know whether a DR plan works is to run it against a production-equivalent environment and measure what breaks. Most organizations do not test at that level of fidelity, and the gap between their stated RTO and their actual recovery time is discovered during a real incident.
Gartner's mandatory feature criteria for DRaaS products include an on-demand recovery cloud specifically designed for planned tests, exercises, and declared disasters. An on-demand test environment is not an advanced feature; it is a baseline requirement for any DR solution that claims a contractual RTO.
Practitioners who have implemented DRaaS at scale consistently surface the same five lessons (from 183 enterprise DRaaS users surveyed by Gartner in 2024):
- Define DR objectives and get stakeholder buy-in before selecting a vendor. RTO and RPO targets must reflect what the business actually requires, not what sounds achievable. A 1-hour RTO that requires IAM state to be manually reconstructed from memory is not a 1-hour RTO.
- Run proof-of-concept tests against your specific environment before committing to a provider. Generic vendor RTO claims are measured against vendor reference architectures. Your actual RTO depends on your IaC coverage, your dependency graph complexity, and your orchestration fidelity.
- Build a detailed onboarding plan. DRaaS implementation, particularly for cloud-native environments, is more operationally complex than most teams expect. Scoping application boundaries, defining tag-based policies, validating IaC coverage, and testing sequencing takes weeks, not days.
- Invest in training across teams. DR plans that only the infrastructure team understands fail when the infrastructure team is unavailable during an incident.
- Approach implementation as a phased program, not a one-time project. Start with the highest-criticality applications, validate recovery, then expand the scope incrementally.
Three operational patterns separate teams that recover in hours from teams that recover in days:
Validate RTO/RPO targets against actual operational state, not theoretical restore times. A 4-hour RTO sounds achievable in a planning meeting. It stops sounding achievable when the team discovers that reconstructing IAM state alone, because the definitions were never codified, takes 90 minutes. RTO targets must be measured against a full recovery drill in a production-equivalent environment, including IAM restoration, secrets repopulation, Kubernetes cluster initialization, and service dependency sequencing.
Test against production-equivalent environments quarterly, at a minimum. IaC coverage gaps, sequencing failures, and missing health validation logic surface during test drills, not during incidents. Every gap found during a drill is a gap that does not become a 3 AM debugging session. Organizations that test annually discover their gaps during real outages. Organizations that test quarterly find and fix them beforehand.
Embed DR validation into CI/CD rather than running it as a standalone annual exercise. A DR posture assessed quarterly reflects what recovery looked like three months ago, before the last 90 days of infrastructure changes, new service deployments, and IAM modifications accumulated. DR validation embedded in the deployment pipeline, where every infrastructure change is automatically checked against recovery definitions, produces a recovery posture that is current as of the last deployment, not the last quarterly drill.
The shift this represents: from disaster recovery as a compliance exercise that gets scheduled once a year and treated as complete when the report is filed, to disaster recovery as a measurable property of how the system is built and operated every day.
Conclusion
Cloud-native systems fail at the configuration and operational-state layer. A Kubernetes misconfiguration, a manually-modified IAM policy, an undeclared service dependency, a secrets manager entry deleted without updating Terraform state, these are the failure modes that block application recovery after infrastructure has been restored. Traditional DRaaS was not designed to protect against them, and adding more VM replication capacity does not close the gap.
Reliable cloud-native disaster recovery requires three investments working in combination:
IaC definitions that continuously reflect the actual production state. Terraform and Pulumi definitions that were accurate six months ago and have accumulated three months of console-applied drift are not a recovery blueprint; they are a historical artifact. Continuous drift detection that flags every manual change in real time, and generates IaC definitions for manually-created resources, keeps the recovery blueprint current with production.
Recovery orchestration that sequences dependency restoration automatically. Database initialization before application deployment. IAM role attachment before service startup. Health validation gates before traffic ingress. Encoding this sequence into automated orchestration, with explicit readiness checks between each step, converts a theoretical RTO into a tested, repeatable one.
Regular recovery testing against production-equivalent environments. IaC coverage gaps, sequencing failures, and missing health validation logic are found during drills, not during incidents. RTO targets validated against actual operational state, including IAM, secrets, Kubernetes, and service dependency restoration, are commitments. RTO targets that have never been tested against real environments are guesses.
The most common single point of failure in cloud-native recovery is the gap between what Terraform says the environment is and what the environment actually is when an incident starts. Platforms that continuously detect and codify infrastructure drift, like Firefly, close that gap before the incident, not during it. Disaster recovery that holds under real incident conditions is not assembled the night the outage occurs. It is built into how the system is operated every day.
FAQs
What is the difference between BaaS and DRaaS?
BaaS copies data off-site and measures RTO and RPO in hours or days; recovery requires an engineer to manually rebuild the environment around the retrieved backup. DRaaS replicates both data and infrastructure, automates failover, and delivers contractual RTO and RPO in minutes. BaaS protects data. DRaaS protects the operational system needed to run it.
What is disaster recovery in SaaS?
SaaS DR operates on a shared responsibility model: the provider guarantees infrastructure uptime and handles platform-level recovery, but data deleted by the customer, corrupted through an integration, or lost through a misconfigured retention policy is the customer's problem to recover. DR planning for SaaS-dependent workloads must account for both the provider's recovery SLA and the customer's own data protection posture inside the application.
What are the 4 pillars of disaster risk reduction (DRR)?
The four pillars from the Sendai Framework are: understanding disaster risk (knowing which failure modes affect your environment and how); strengthening governance (assigning clear ownership of DR planning and testing); investing in risk reduction (building IaC coverage, drift detection, and automated health validation before incidents occur); and enhancing preparedness (running regular recovery drills against production-equivalent environments and validating RTO targets against actual operational state, not theoretical restore times).
What is the difference between SLA, RTO, and RPO?
RTO is the maximum time an application can be offline before business impact becomes unacceptable, an internal target set by the organization. RPO is the maximum data loss the organization can tolerate, measured in time, which drives backup frequency. SLA is the contractual commitment a DRaaS provider makes to the customer, formalizing those targets with defined penalties. The gap that matters in practice: a provider SLA promising two-hour recovery against an internal one-hour RTO requirement is a procurement problem, not a technical one, and it should be caught before the contract is signed.

.avif)
.avif)


.webp)


.webp)















